早在两个星期前,我就自以为对MR的数据处理流程已大致清楚,但是真正到了写mapreduce程序时还是无从下手,因此怀着悲愤的心情决定将其以书面的形式再梳理一遍。
先不谈MemoryBuffer,我直接将MR的处理流程大体说下。
(block)输入—>分片(split)—>读取(RecordReader)—>调用函数(map)
—>分区(Partition)—>溢写(spill)—>sort(对key排序)—>合并(combiner)—>归并(merge)
—>传送数据(copy)—>归并(merge)—>归并排序(Sort)—>Reduce—>写出(write)
可以看出,以上流程分为3个阶段:Map-Shuffle-Reduce,其中shuffle横跨其他两个阶段。
按照正常思维理解,要处理数据,首先是要将它存在一个容器中,经过步步操作,得出我们想要的格式,输出。MR不过是在处理过程中先得出一个map中间结果 (不过并未输出),然后此结果作为reduce task的输入继续参与我们的计算。
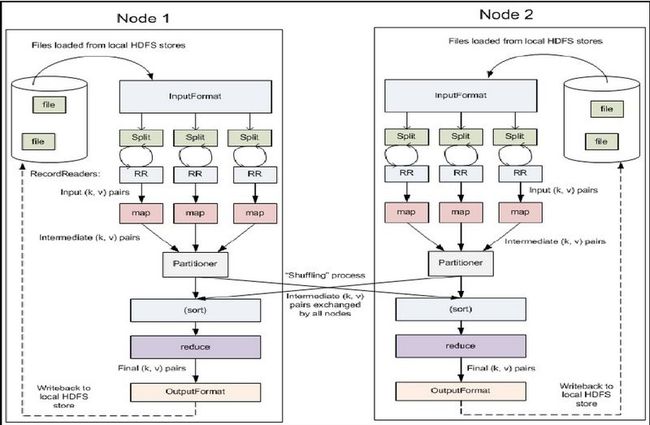
Map:map端的处理过程很简单,文件传入之前首先是分成默认的block的文件块,输入到InputFormat当中,之后hadoop对输入的文件进行逻辑分片,分成一个个的split,这就是map的输入。之后就是读取这些split,每读取一条就会调用一次map函数。map函数是自定义的,我们一般定义如下: function map(record v){
for word in v:
write(key,value)
}
经过map处理,数据一般会以<key,value>的形式存入内存,其中value一般自定义为1。
Shuffle:都说shuffle过程是个神奇的过程,因为它是mapreduce处理数据的核心,也是优化性能时可塑性最强的阶段。
数据被写成键-值对形式后,就要被分配到对应的reduce task进行处理。因此首先涉及的就是reduce端的分区,hadoop中partition的默认实现是hash取模算法。eg:wordcount程序的map后的数据格式{this,1},设有n个reducer,那么就是对数据的key值“this”先hash后再对n取模,返回m。就是指这个split的数据会被分配到m号的reducer上去进行reduce过程。
partition过程之后,数据格式变为<partition,key,value>,但是之后数据并不是立即存往reduce端,而是先存入MemeoryBuffer(内存缓冲区)。顾名思义,MemoryBuffer相当于数据的一个中转站,它设置在map端,默认值是100M。整个缓冲区有个溢写的比例spill.percent,这个比例默认是0.8,因此它又分为两个部分,其中的80M用于预存预存map task的输出结果。当输入数据达到80M这个阀值时,spill线程启动,锁定这80MB的内存,执行溢写过程。Map端的输出结果还可以往剩下的20MB内存中写,互不影响。如此一来,效率显然提高不少,不必时时停止输入,加快了进程。
溢写(spill)线程启动后,需要对这80MB空间内的key做排序(Sort)。这里的排序是MapReduce模型默认的行为,也就是对序列化的字节做的排序,hadoop默认升序,我们有时需要根据自己的需求重写Sort方法。
在wordcount里就是将value相加,这个过程就是减少溢写到磁盘的数量,这时候数据的格式是这样的<key,num>。
到这里,数据仍是<partition,key,1>的形式,所以为了减少与partition相关的索引记录,如果有很多个key/value对需要发送到某个reduce端去,那么需要将这些key/value值拼接到一块,这个合并的过程叫做combiner,可以看出这个函数的功能其实和reduce是一样的,他的作用就是将key相同的<key,value>的value合并,在wordcount里就是将value相加,这个过程就是减少溢写到磁盘的数量,这时候数据的格式变成<partition,key,num>。
在spill过程,每次溢写会在磁盘上生成一个溢写文件,如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个溢写文件存在。当map task真正完成时,内存缓冲区中的数据也全部溢写到磁盘中形成一个溢写文件。最终磁盘中会至少有一个这样的溢写文件存在(如果map的输出结果很少,当map执行完成时,只会产生一个溢写文件),因为最终的文件只有一个,所以需要将这些溢写文件归并到一起。eg:还是以wordcount为例子,merge的最终文件只有一个,所以要将这些溢写文件归并到一起,比如从一个map读过来的是{“this”,8},另一个是{“this”:7},merge的结果就会变成{“this”,[8,7]}。 (此段摘自林豪翔的整理文档)
我之前一直搞不清combiner和merge的区别,后来的理解是,combiner是对一个map任务处理结果的合并,儿merge是对多个map任务处理结果的合并,这也是后者在前者之后执行的原因。
Reduce:自此map端的任务才算真正结束,它的最终结果是在map端本地存着生成的文件,之后就是交给reduce端来进行reduce过程。reduce端通过RPC来不断的从map端那里获取map task是否完成的信息,一旦完成就开始进行reduce端的shuffle过程。
reduce端处理数据,先要获取map task的输出文件,这一copy操作其实就是简单的拉取数据。之后是reduce的merge过程,从上可知,经过map端的merge后,数据是变为<“this”,[8,7]>的形式,reduce的merge就是对其进行一个整的合并,得出最终结果<this,num>。
至此mapreduce的流程大体分析完毕,理论上来说,我们只要分析map和reduce过程就可以完成MR的编程,数据格式各样时,也只是需要重写一些中间省略了的方法,比如Sort、partition,etc。但是,最近开写MR程序时着实有种无从下手的感觉,希望有经验的朋友能够分享一些自己学习编写MR程序的方法,不甚感激!
如果对我的理解有疑问的话,可以参考这篇文章和hadoop教程,配上图文和代码,应该更好理解一些吧。
Welcome criticism~