吞噬大数据存储领域新机制——NoSQL模式解析

在过去几年,一种新兴的大型数据存储机制正吞噬大数据存储市场。这种存储 解决方案与传统的RDBMS有显著的区别,它们被称之为NoSQL。
在NoSQL世界中有以下关键的成员,包括
●Google BigTable、HBase、Hypertable
●Amazon Dynamo、Voldemort、Cassendra、Riak
●Redis
●CouchDB、MongoDB
而这些解决方案又有一些共同的特点
●基于键-值存储
●系统运行在海量的普通机器上
●数据在经过分区和复制后分布在集群中
●放宽对数据一致性的要求(因为CAP定理)。
选择NoSQL的重要标准就是要看CAP(Consistency、 Availability和Partition Tolerance),也就是我们所说的一致性、可用性和分区容忍性。但CAP原则要求在分布式系统只能选择一致性、可用性和分区容忍性其中的两项。
本文旨在提取这些解决方案背后的共同的技术,以便更深入的了解应用程序设 计的意义。本文并不会对这些解决方案作比较,也不会建议使用某一款产品。
API模型
底层的数据模型可以被看作为一个大的Hashtable(键/值存储)
API访问基本形式:
get(key):提取给定键的对应值
put(key,value) :新建或更新给定键的对应值
delete(key):删除键及其关联值
在服务器环境利用更高级的API执行用户自定义的函数
execute(key, operation, parameters) :调用操作给定键对应的值,值具有特殊数据(例如List、Set、Map等)
mapreduce(keyList, mapFunc, reduceFunc) :对范围内的键调用MapReduce
机器布局
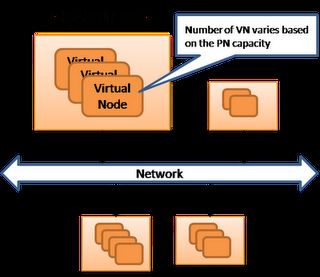
底层基础设施由大量(成百上千)廉价的、普通的、不可靠的机器通过网络组 成。每台机器为一个单独的物理节点(PN)。在每个PN软件配置相同,但CPU、内存、硬盘等会有所不同。每个PN根据不同的硬件配置运行不同数目的虚拟 节点。
数据分区

由于整个Hashtable分布在众多VN之中,我们需要一种能够将每个 键映射到对应VN的方法。一种行之有效的方法是:partition = key mod (total_VNs)。这种方案的缺点是当我们改变VN的数量时,现有键的所有权将发生巨大的变化,这导致全部的数据需要重新再分配。所以多数大型存储 使用被称为“consistent hashing”的技术将键所有权变更的影响最小化。
在“consistent hashing”方法中,键空间是有限的,且分布在一个环上。虚拟节点的ID也从相同的键空间中分配。对于任意键,如果从该键沿着环 顺时针移动,遇到了第一个虚拟节点就是它的所属节点。当某一节点崩溃时,他所属的所有键都将顺时针的移动到相邻的节点。因此,重新分配键的情况只发生在崩 溃节点的相邻节点中,而所有其他的节点仍保持原有的键值。
数据复制
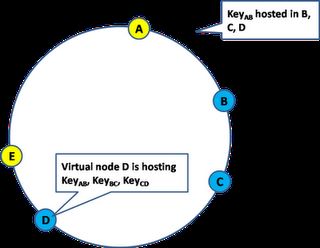
为了从单个并不可靠的资源来提供更高的可靠性,迫使我们需要复制数据分 区。
复制不仅提高了数据的可靠性,同时将工作负载分布到多个副本还有助于提升 性能。
只读请求可以分发到任何副本,而更新的要求却具有挑战性。因为需要任职协 调各个副本的更新。
成员变动

请注意,虚拟节点可以随时加入和离开而不影响环的运作网络。
当心节点加入到网络
1.新加入的节点将示意自身的存在,并将其ID通知其他重要的节点。
2.所有相邻(左边或右边)节点将调整键的所有权以及副本成员的信息,这 将通过同步完成。
3.新加入的节点开始从其相邻的节点并行、异步的批量复制数据。
4.副本成员的变更异步传播到其他节点
当现有节点脱离网络时(例如崩溃)
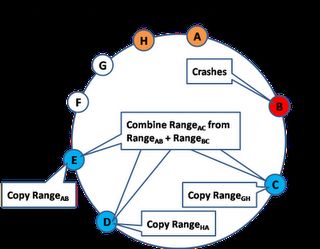
1.崩溃的节点不再回应Gossip消息,因此相邻的节点也会得知此情 况。
2.相邻节点更新成员信息,同时异步复制数据。
客户端的一致性
一旦我们拥有相同数据的多个副本,就必须考虑如何同步他们,这样在客户端 看来数据才能使一致的。
1.严格的一致性:从语义上看相当只存在一个数据副本,任何更新看上去都 是实时发生的。
2.读取已写内容的一致性:允许客户端立刻看到自身所做的更新,但无法看 到其他客户端的更新
3.会话一致性:对于客户端在同一会话作用域发出的请求,提供读取已写内 容一致性。
4.单调读一致性:保证时间的单调性,保证客户端在未来的请求中只读区比 当前更新的数据。
5.最终一致性:提供最低限度的保证。在更新过程中客户端将看到不一致的 视图。当并发访问同一数据几率非常小的时候,此模型效果可以得到保证。
同时取决采用何种一致性模型需要安排两种机制
●客户端请求如何让分发到副本
●副本如何传播以及应用更新
围绕着如何实现这两方面。出现了许多模型,各有不同的权衡取舍。
矢量时钟
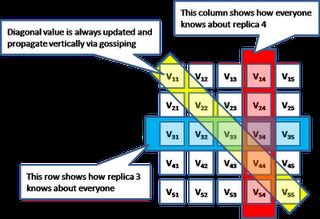
矢量时钟是一种时间戳机制,透过矢量时钟我们可以推到更新之前的因果关 系。首先,每个副本都持有矢量时钟。假设副本i的时钟是Vi。Vi[i]是副本根据特定规则更新矢量时钟之后的逻辑时钟。
●当副本i执行了一则内部操作,副本i的时钟加1。
●当副本i向副本j发送一则消息,副本i首先把自己的时钟Vi[i]加 1,并将自己的矢量时钟Vi附加到消息中发送出去。
●当副本j收到来自副本i的消息,首先自增其时钟Vj[j],然后合并其 时钟及消息所附的时钟Vm。即Vj[k] = max (Vj[k], Vm[k])。
于是可以定义偏序关系,Vi > Vj,当且仅当对于所有的k,Vi[k] >= Vj[k]。根据这样的偏序关系,我们就可以推导出更新之间的因果关系。其背后原理如下
●内部操作的效果可在同一节点上立即看到。
●接到消息之后,接收节点得知发送节点在消息发送之时的情况。情况不仅包 括发送节点上发生的事情,还包括发送节点所知的所有其他节点上发生的事情。
●Vi[i]反映了节点i上发生最后一次内部操作的时间。Vi[k] = 6意味着副本i已经知道副本k在他的逻辑时钟6时刻的情况。
MapReduce的执行过程
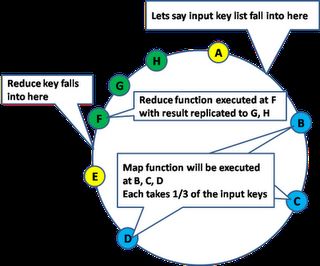
分布式存储架构同样适合分布式的处理,例如对一个键列表执行 Map/Reduce操作情况。
系统将Map和Reduce函数推送给全部的节点。Map函数分布到键所 属的各个副本上处理,然后Map函数的输出被转交给Reduce函数去执行聚合操作。
对删除的处理
在多主复制系统中,用矢量时钟时间戳去判定因果序,需要非常小心处理 “删除”的情况。以免丢失掉删除对象关联的时间戳信息,否则根本无法推到何时执行删除。因此,通常需要将删除当 作一种特殊的更新来处理,把对象标记为删除,但仍然保留元数据、时间戳信息。当经过足够长的时间,并确信所有节点都已经对该对象标记为删除之后,才能通过 垃圾回收已删除对象的空间。(Шевченко/编译)
原文链接:DZone.com