(三)电子商务推荐系统--协同过滤
拖了两个月,终于要进入正题了,本章开始折腾真正的算法(ps:其实也没那么高深)。
第一个要说的肯定是经典的协同过滤了,从算法的主体来分可以分为两种:基于用户的协同过滤(user-CF)和基于物品的协同过滤(item-CF),CF就是collaborative filtering,所谓协同就是在大家都要对结果有贡献。
其基本思想是兴趣相似的用户其行为也相似,反之也成立,实现协同过滤的关键在于怎么算行为相似,用什么样的标准去度量相似度。
| a | b | c | |
| 101 | 5 | 1 | 3 |
| 102 | 5 | 2 | - |
行是item,列是用户,交叉点是评分。
从图中我们可以看出来101和102都对a和b评分了,且评分基本一致,说明他们俩兴趣应该相似,这个时候可以把c推荐给102。下面把这个过程数学化一下:
1、计算101与102的相似度
可以把它们对item的评分看成两个向量(只包含两个用户共同评价的item):(5,1)、(5,2),把这两个向量看成坐标轴上的两个点:
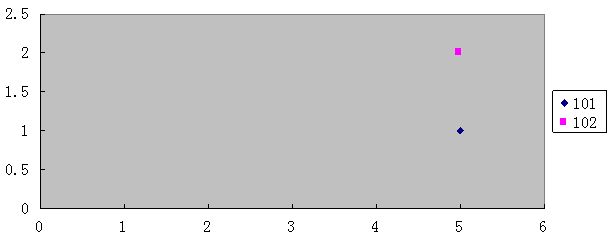
然后可以把这两个点之前的距离做为101和102之间的相似度,计算公式大家应该都知道了,就是初中学的平面几何了。
w=sqrt((5-5)^2+(1-2)^2) = 1
本来打算昨天写完,但是iteye的编辑器实在不好用,不支持LaTex不说,连潜入个图片都这么麻烦。长话短说,先把主要意思写完吧,回头博客会搬到csdn上去。
上面的公式其实就是欧几里得距离啦,很简单是吧,如果item多了也是这么着算,这里就不贴公式了(蛋疼。。。)
2、推荐
我们可以为每一个用户都维护一个列表,用于存储于他相似的用户,然后,从这些用户评过分的item中挑一些推荐给他,过滤他评过分的item,具体到这个例子中就是把101评过分的c推荐给102。
当然这个过程还有很多细节问题,比如如果与用户A相似的用户有很多,他们评过分的商品也有很多,那么如何从这么多的商品中挑选出一部分推荐给A呢?还有,挑选出的商品如何排序?此系后话,且听下回分解……
上面讲的是USER-CF,ITEM-CF同理,其实一般常用的是ITEM-CF,因为对于B2C网站来说,商品有限,而用户无限,计算量会小得多,但是因为USER-CF讲起来比较容易理解,所以这里就以USER-CF为例。
=================================华丽的分隔线=============================
下面以item-CF为例进行讲解
上面的讲的方法是根据用户对商品的评分,那么如果用户对于商品只有购买而没有评分,或者评分数据太少怎么办呢?
这其实就是我要讲的重点,对于用户和商品之间只有购买与不购买的关系,我们可以称之为布尔矩阵,购买是1,不购买是0,这个时候如果也使用欧几里得距离去计算的话,会发现很不合适,那我们怎么得出用户之间的相似度呢?
{N(a) ^ N(b)} / {N(a) * N(b)}(凑合着看吧。。。)
N(a):买了商品a的用户
N(b):买了商品b的用户
分子的意思是同时买了a和b的用户的数量
分母是买了a的用户的个数与买了b的用户的个数的积
这样我们就得出了商品a和b之间的相似度,推荐的话,如果a和b相似,就可以给买了a的用户推荐b。
这就是item-CF了,也很简单是吧。
但是简单不代表不强大,这里面有很多可以优化的地方,其实主要看你的源数据的形态了,下一篇我们会讲增强版的协同过滤,如果有时间我会把这一篇完善下,公式填上去,真不爽,真心希望iteye能对这个编辑器改进一下,学学Wordpress