通过Map-Reduce实现Join系列之一
本系列的开篇在提到使用Map-Reduce实现Join之前,先来看看目前在数据库中应用比较广泛和流行的集中Join算法。它们分别是嵌套循环Join(Nested Loops Join)、排序合并Join(Sort-Merge Join)和哈希Join(Hash Join)。
1.嵌套循环Join
这种Join算法实现起来非常简单,而且可以支持任何类型的Join条件。但是在当两个集合包含的记录数变大的情况下,性能下降非常厉害,因为对于一个具有n条记录的集合R和m条记录的集合S来说,时间复杂度是O(m*n)。
2.排序合并Join
合并排序Join,应该使用比较普遍的算法,对于两个需要进行Join的集合P和Q,首先分别对这两个集合进行排序,每个集合在排序时使用的属性就是Join的时候需要用的属性。排序完成之后使用下面的算法对这两个集合进行合并:
假设数据集合P和Q中的记录情况如下:
集合P:
集合Q:
我们通过B列对两个数据集合进行Join,首先需要对两个集合在B列上进行排序,得到的接结果如下:
集合P:
集合Q:
根据算法,当第一次发现有可以Join的两个记录时,指向集合P和集合Q的两个记录指针的位置如下图所示:
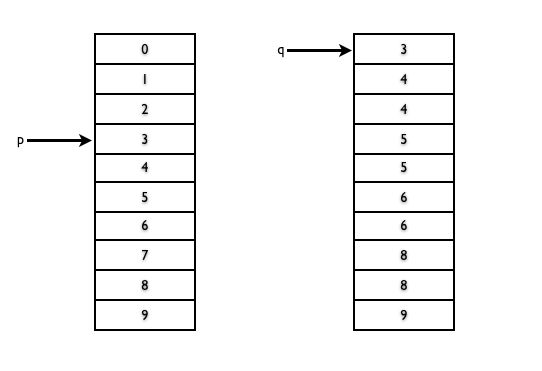
发现有可以Join的记录之后,根据算法,会将p和q所指向的两条记录进行Join,然后输出,之后q指向下一条记录,这个时候发现p和q的B列值不相等了,根据算法p会指向下一条记录,由于这个时候p和q指向的B列值相等,因此算法中的前两个while循环被跳过,直接进入第三个while循环,找个循环将集合P中B值为4的一条记录与集合Q中B列值为4的两条记录进行Join,循环结束之后,p和q的指向如下图所示:

算法继续执行,知道两个集合中B列值相等的所有记录都被Join之后,算法结束。
3.哈希Join
哈希Join需要将被Join的两个数据集合中的一个全部载入内存的哈希表中。因此,这种Join方式适用于被Join的两个数据集合中,有一个集合数据量比较小,可以全部放入内存的场景。这种Join方式的伪代码如下,其中有两个数据集合,分别是P和Q,而集合P数据量比较小,可以全部载入内存中的哈希表中:
这种Join算法同样只能用于等值Join操作。相比于排序合并Join,这种方式速度要更快,但是对内存的消耗比较大。
1.嵌套循环Join
for R中的每一条记录r do
for S中的每一条记录s do
if (r和s满足Join条件)
将r和s进行合并,然后输出
end for
end for
这种Join算法实现起来非常简单,而且可以支持任何类型的Join条件。但是在当两个集合包含的记录数变大的情况下,性能下降非常厉害,因为对于一个具有n条记录的集合R和m条记录的集合S来说,时间复杂度是O(m*n)。
2.排序合并Join
合并排序Join,应该使用比较普遍的算法,对于两个需要进行Join的集合P和Q,首先分别对这两个集合进行排序,每个集合在排序时使用的属性就是Join的时候需要用的属性。排序完成之后使用下面的算法对这两个集合进行合并:
p∈P;q∈Q;gq∈Q while q中还有记录 do while p.a gq.b do 令gq指向集合Q中的下一条记录 end while while p.a == gq.b do q = gq //找到要Join的两条记录了 while p.a == q.b do 将记录p和q Join之后输出 令q指向集合Q中的下一条记录 end while 令p指向集合P中的下一条记录 end while gq = q //记录查询可以进行Join的记录 end while
假设数据集合P和Q中的记录情况如下:
集合P:
| A | B |
| ABC | 1 |
| ABC | 2 |
| ABC | 9 |
| ABC | 8 |
| ABC | 0 |
| ABC | 3 |
| ABC | 5 |
| ABC | 7 |
| ABC | 4 |
| ABC | 6 |
集合Q:
| C | B |
| DEF | 5 |
| DEF | 6 |
| DEF | 9 |
| DEF | 4 |
| DEF | 6 |
| DEF | 3 |
| DEF | 8 |
| DEF | 8 |
| DEF | 4 |
| DEF | 5 |
我们通过B列对两个数据集合进行Join,首先需要对两个集合在B列上进行排序,得到的接结果如下:
集合P:
| A | B |
| ABC | 0 |
| ABC | 1 |
| ABC | 2 |
| ABC | 3 |
| ABC | 4 |
| ABC | 5 |
| ABC | 6 |
| ABC | 7 |
| ABC | 8 |
| ABC | 9 |
集合Q:
| C | B |
| DEF | 3 |
| DEF | 4 |
| DEF | 4 |
| DEF | 5 |
| DEF | 5 |
| DEF | 6 |
| DEF | 6 |
| DEF | 8 |
| DEF | 8 |
| DEF | 9 |
根据算法,当第一次发现有可以Join的两个记录时,指向集合P和集合Q的两个记录指针的位置如下图所示:
发现有可以Join的记录之后,根据算法,会将p和q所指向的两条记录进行Join,然后输出,之后q指向下一条记录,这个时候发现p和q的B列值不相等了,根据算法p会指向下一条记录,由于这个时候p和q指向的B列值相等,因此算法中的前两个while循环被跳过,直接进入第三个while循环,找个循环将集合P中B值为4的一条记录与集合Q中B列值为4的两条记录进行Join,循环结束之后,p和q的指向如下图所示:
算法继续执行,知道两个集合中B列值相等的所有记录都被Join之后,算法结束。
3.哈希Join
哈希Join需要将被Join的两个数据集合中的一个全部载入内存的哈希表中。因此,这种Join方式适用于被Join的两个数据集合中,有一个集合数据量比较小,可以全部放入内存的场景。这种Join方式的伪代码如下,其中有两个数据集合,分别是P和Q,而集合P数据量比较小,可以全部载入内存中的哈希表中:
for 集合P中的记录p do 将p载入内存中的哈希表H中 end for for 集合Q中的记录q do if H中有记录与q在Join条件匹配 将p和q做Join操作,然后将结果输出 end if end for
这种Join算法同样只能用于等值Join操作。相比于排序合并Join,这种方式速度要更快,但是对内存的消耗比较大。