nutch SolrIndexer 详解
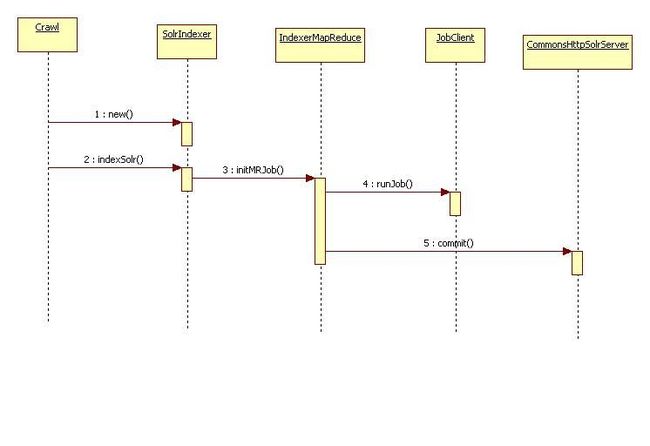
这个 job的 具体和 nutch1.2 index http://chengqianl.iteye.com/admin/blogs/1597617一样
IndexerMapReduce.initMRJob(crawlDb, linkDb, segments, job);
唯一不同的是writer是设置的 SolrWriter
它的open方法 如下粗体部分通过solrj,new了一个CommonsHttpSolrServer
public void open(JobConf job, String name) throws IOException {
solr = new CommonsHttpSolrServer(job.get(SolrConstants.SERVER_URL));
commitSize = job.getInt(SolrConstants.COMMIT_SIZE, 1000);
solrMapping = SolrMappingReader.getInstance(job);
}
它的write方法如下,粗体部分是把数据写入solr
public void write(NutchDocument doc) throws IOException {
final SolrInputDocument inputDoc = new SolrInputDocument();
for(final Entry<String, NutchField> e : doc) {
for (final Object val : e.getValue().getValues()) {
inputDoc.addField(solrMapping.mapKey(e.getKey()), val, e.getValue().getWeight());
String sCopy = solrMapping.mapCopyKey(e.getKey());
if (sCopy != e.getKey()) {
inputDoc.addField(sCopy, val, e.getValue().getWeight());
}
}
}
inputDoc.setDocumentBoost(doc.getWeight());
inputDocs.add(inputDoc);
if (inputDocs.size() > commitSize) {
try {
solr.add(inputDocs);
} catch (final SolrServerException e) {
throw makeIOException(e);
}
inputDocs.clear();
}
}