oracle 分析函数之rank,dense_rank,row_number笔记
rank,dense_rank,row_number 函数都是为每条记录产生一个从1开始至N的自然数,N的值可能小于等于记录的总数。这3个函数的唯一区别在于,当碰到相同数据时的排名策略。
语法:rank() over(partition-clause order-by-clause)
rank:
rank函数返回一个唯一的值,除非遇到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条记录排名之间空出排名。
dense_rank:
dense_rank函数返回一个唯一的值,除非当碰到相同数据时,此时所有相同数据的排名都是一样的。
row_number:
row_number函数返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
建表如下:
create table SMALL_CUSTOMERS(CUSTOMER_ID NUMBER,SUM_ORDERS NUMBER); insert into SMALL_CUSTOMERS (CUSTOMER_ID, SUM_ORDERS) values (1000, 10); insert into SMALL_CUSTOMERS (CUSTOMER_ID, SUM_ORDERS) values (1000, 20); insert into SMALL_CUSTOMERS (CUSTOMER_ID, SUM_ORDERS) values (1000, 30); insert into SMALL_CUSTOMERS (CUSTOMER_ID, SUM_ORDERS) values (800, 5); insert into SMALL_CUSTOMERS (CUSTOMER_ID, SUM_ORDERS) values (800, 10); insert into SMALL_CUSTOMERS (CUSTOMER_ID, SUM_ORDERS) values (800, 1);
具体用法如下:
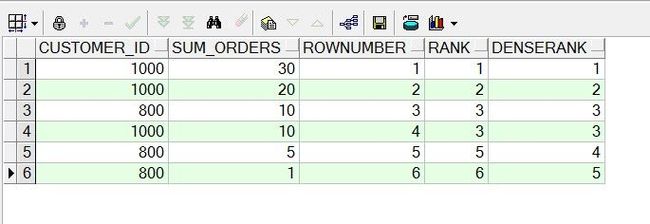
select customer_id,
sum_orders,
row_number() over(order by sum_orders desc) rowNumber,
rank() over(order by sum_orders desc) rank,
dense_rank() over(order by sum_orders desc) denseRank
from small_customers t;
也可以进行分组:
select customer_id,
sum_orders,
row_number() over(partition by customer_id order by sum_orders desc) rowNumber,
rank() over(partition by customer_id order by sum_orders desc) rank,
dense_rank() over(partition by customer_id order by sum_orders desc) denseRank
from small_customers t;
