SolrCloud是基于Solr和Zookeeper的分布式搜索方案,是正在开发中的Solr4.0的核心组件之一,它的主要思想是使用Zookeeper作为集群的配置信息中心。它有几个特色功能:1)集中式的配置信息 2)自动容错 3)近实时搜索 4)查询时自动负载均衡
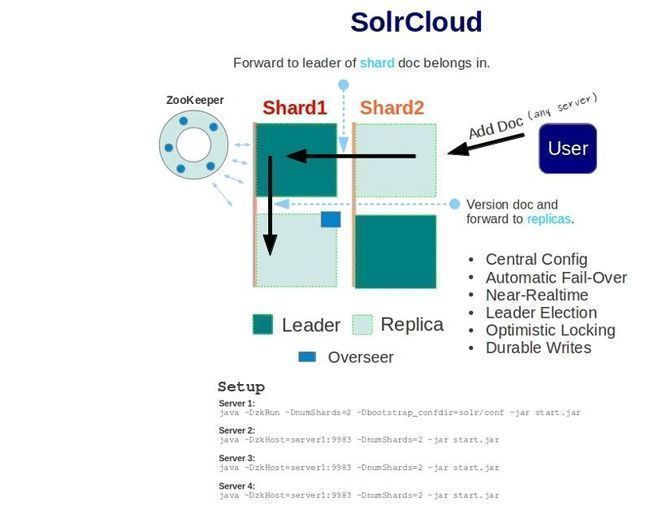
基本可以用上面这幅图来概述,这是一个拥有4个Solr节点的集群,索引分布在两个Shard里面,每个Shard包含两个Solr节点,一个是Leader节点,一个是Replica节点,此外集群中有一个负责维护集群状态信息的Overseer节点,它是一个总控制器。集群的所有状态信息都放在Zookeeper集群中统一维护。从图中还可以看到,任何一个节点都可以接收索引更新的请求,然后再将这个请求转发到文档所应该属于的那个Shard的Leader节点,Leader节点更新结束完成,最后将版本号和文档转发给同属于一个Shard的replicas节点。
下面我们来看一个简单的SolrCloud集群的配置过程。
首先去https://builds.apache.org/job/Solr-trunk/lastSuccessfulBuild/artifact/artifacts/下载Solr4.0的源码和二进制包。
示例1,简单的包含2个Shard的集群

这个示例中,我们把一个collection的索引数据分布到两个shard上去,步骤如下:
为了弄2个solr服务器,我们拷贝一份example目录
然后启动第一个solr服务器,并初始化一个新的solr集群,
java -Dbootstrap_confdir=./solr/conf -Dcollection.configName=myconf -DzkRun -DnumShards=2 -jar start.jar
-DzkRun参数是启动一个嵌入式的Zookeeper服务器,它会作为solr服务器的一部分,-Dbootstrap_confdir参数是上传本地的配置文件上传到zookeeper中去,作为整个集群共用的配置文件,-DnumShards指定了集群的逻辑分组数目。
然后启动第二个solr服务器,并将其引向集群所在位置
java -Djetty.port=7574 -DzkHost=localhost:9983 -jar start.jar
-DzkHost=localhost:9983就是指明了Zookeeper集群所在位置
我们可以打开http://localhost:8983/solr/collection1/admin/zookeeper.jsp 或者http://localhost:8983/solr/#/cloud看看目前集群的状态,
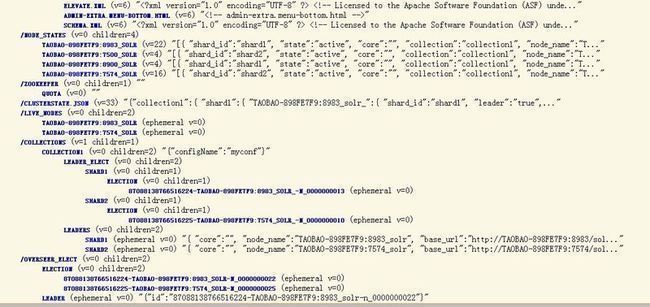
现在,我们可以试试索引一些文档,
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar ipod_video.xml
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar monitor.xml
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar mem.xml
最后,来试试分布式搜索吧:
http://localhost:8983/solr/collection1/select?q
Zookeeper维护的集群状态数据是存放在solr/zoo_data目录下的。
现在我们来剖析下这样一个简单的集群构建的基本流程:
先从第一台solr服务器说起:
1) 它首先启动一个嵌入式的Zookeeper服务器,作为集群状态信息的管理者,
2) 将自己这个节点注册到/node_states/目录下
3) 同时将自己注册到/live_nodes/目录下
4)创建/overseer_elect/leader,为后续Overseer节点的选举做准备,新建一个Overseer,
5) 更新/clusterstate.json目录下json格式的集群状态信息
6) 本机从Zookeeper中更新集群状态信息,维持与Zookeeper上的集群信息一致
7)上传本地配置文件到Zookeeper中,供集群中其他solr节点使用
8) 启动本地的Solr服务器,
9) Solr启动完成后,Overseer会得知shard中有第一个节点进来,更新shard状态信息,并将本机所在节点设置为shard1的leader节点,并向整个集群发布最新的集群状态信息。
10)本机从Zookeeper中再次更新集群状态信息,第一台solr服务器启动完毕。
然后来看第二台solr服务器的启动过程:
1) 本机连接到集群所在的Zookeeper,
2) 将自己这个节点注册到/node_states/目录下
3) 同时将自己注册到/live_nodes/目录下
4) 本机从Zookeeper中更新集群状态信息,维持与Zookeeper上的集群信息一致
5) 从集群中保存的配置文件加载Solr所需要的配置信息
6) 启动本地solr服务器,
7) solr启动完成后,将本节点注册为集群中的shard,并将本机设置为shard2的Leader节点,
8) 本机从Zookeeper中再次更新集群状态信息,第二台solr服务器启动完毕。
示例2,包含2个shard的集群,每个shard中有replica节点

如图所示,集群包含2个shard,每个shard中有两个solr节点,一个是leader,一个是replica节点,
cp -r example2 example2B
cd exampleB
java -Djetty.port=8900 -DzkHost=localhost:9983 -jar start.jar
cd example2B
java -Djetty.port=7500 -DzkHost=localhost:9983 -jar start.jar
我们可以打开http://localhost:8983/solr/collection1/admin/zookeeper.jsp 看看包含4个节点的集群的状态,
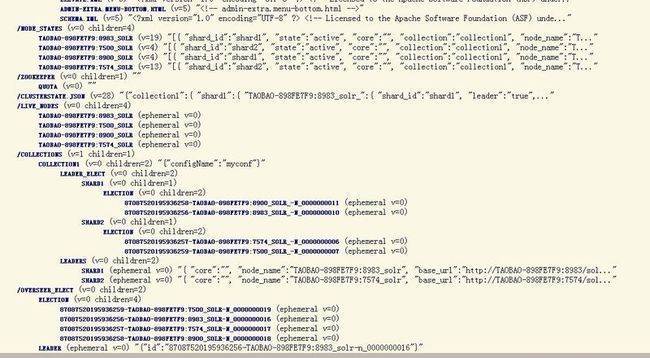
这个集群现在就具备容错性了,你可以试着干掉一个Solr服务器,然后再发送查询请求。背后的实质是集群的ov erseer会监测各个shard的leader节点,如果leader节点挂了,则会启动自动的容错机制,会从同一个shard中的其他replica节点集中重新选举出一个leader节点,甚至如果overseer节点自己也挂了,同样会自动在其他节点上启用新的overseer节点,这样就确保了集群的高可用性。
示例3 包含2个shard的集群,带shard备份和zookeeper集群机制

上一个示例中存在的问题是:尽管solr服务器可以容忍挂掉,但集群中只有一个zookeeper服务器来维护集群的状态信息,单点的存在即是不稳定的根源。如果这个zookeeper服务器挂了,那么分布式查询还是可以工作的,因为每个solr服务器都会在内存中维护最近一次由zookeeper维护的集群状态信息,但新的节点无法加入集群,集群的状态变化也不可知了。因此,为了解决这个问题,需要对Zookeeper服务器也设置一个集群,让其也具备高可用性和容错性。
有两种方式可选,一种是提供一个外部独立的Zookeeper集群,另一种是每个solr服务器都启动一个内嵌的Zookeeper服务器,再将这些Zookeeper服务器组成一个集群。 我们这里用后一种做示例:
java -Dbootstrap_confdir=./solr/conf -Dcollection.configName=myconf -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -DnumShards=2 -jar start.jar
cd example2
java -Djetty.port=7574 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
cd exampleB
java -Djetty.port=8900 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
cd example2B
java -Djetty.port=7500 -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
我们可以打开http://localhost:8983/solr/collection1/admin/zookeeper.jsp 看看包含4个节点的集群的状态,可以发现其实和上一个没有任何区别。
来自互联网