问题描述:
应用服务器jboss,数据库 oracle RAC
DataSource URL:
<xa-datasource-property name="URL">
jdbc:oracle:thin:@(description=(address_list=(load_balance=on)(failover=on)(address=(protocol=tcp)(host=db1)(port=xxx))(address=(protocol=tcp)(host=db2)(port=xxx)))(connect_data=(service_name=xxx)(failover_mode=(type=select)(method=basic))))
</xa-datasource-property>
当RAC环境中一台机器(db2)宕机后,jboss的所有连接会切换到db1,但是当db2重启恢复后,db1的压力很大,db2的压力为零,再也不会有新的jboss 来的应用DB 请求会hit 到db2 上。
出现以上情况的时候, 我们短期应对的办法是将所有应用服务重启一遍,App 新的连接会重新到分布到db2 上。
那么我们需要研究确认的问题,rac环境中一个节点宕机重启恢复后,
1、jboss是否有其他什么办法会自动重连到重启过的节点?
2、负载达到平衡的过程需要多少时间?
问题分析
猜测
应为Oracle odbc 包 ojdbc.1.4G.jar 是不开源的, 而且我手头上也没什么好的反编译手段, 那么也就只有猜了。
可以猜测当Jboss datasource 使用如上配置时, Jboss 连接RAC DB 的时候, DB connection pool 管理器从配置中读取到db rac 的配置, 使用简单select 语句在db 实例上做health check, 当发现某一个db 实例为不可用状态的时候, 把 DB connection pool 里面的使用该db 实例的连接设置为null, 然后如果我们还需要更多的db connection 的时候, 我们会重新创建使用另外一个可用的db实例的连接并放回连接池中。后面, 即使我们的其中一个db 实例已经恢复了, 但是我们db 连接池中其他的db connection 都已经使用了其他的db 实例, 并且状态都可用, 那么应用程序就再也不会使用刚刚恢复的DB 实例了。好吧, 说的有点罗嗦, 我们另外打个比方吧。
- 我们可以假设当前有Jboss 维护了50个connection (最大连接池size 50)在连接池中, 其中20个指向db1, 30个指向db2;
- 某时刻db2 宕机了,Jboss 的health check发现db1 不可用, 把所有使用db2 的连接置为null;
- 后续线程从连接池获取连接的时候, 发现当前的连接池的size 未满, 会创建新的指向db1 的连接使用并放回线程池中, 假设经过一段时间以后, 连接池里面的50 个连接都变成指向db1
- 当db2 恢复以后, 虽然db2 已经可用, 但是因为连接池中的连接全部被指向db1 的连接占满, 并且这50 个连接都是处于健康可用状态, 连接池的管理器便很难找到合适的时机把连接池中可用的指向db1 的连接设置为空并替换成指向db2 的连接。
要解决这个问题可以有两方面的思路
1. Jboss 容器或者我们的应用去管理DB connection, 周期性的check 已经down 掉的db2 实例是否已经恢复到可用状态, 如果已经恢复了,然后把连接池中的部分连接换成指向db2 的连接。 这样做比较简单粗暴, 可能会带来一些意想不到的问题。 寄希望Jboss 或者ojdbc 已经做掉了相似的逻辑, 拿着我们的问题找谷歌大神求救, 发现他们都没有cover 这个case。好吧, 这个方案直接走不通。
2. 通过与IT 联系检查, 我们发现早期我们的 db url 配置中的db 地址是直接物理地址。 也就是如下图所示。 那么如果我们使用虚拟地址, 让floating VIP 去为应用屏蔽掉RAC db 实例中集群的细节。
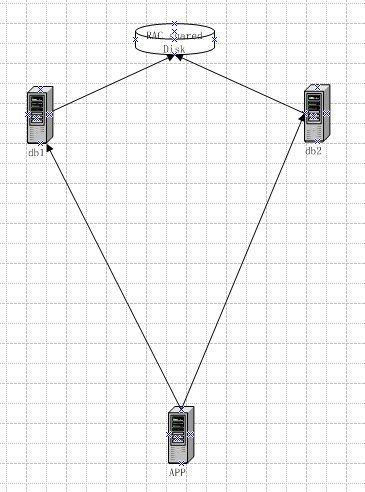
Floating VIP 方案描述
方案1
使用两个floating VIP , 如图所示。 floating VIP1 优先绑定db1 server 物理地址, 当db1 不可用时,漂移到db2 上。 floating VIP2 和floating VIP1 类似。(这里的漂移发生的条件和表现可能不正确, 需要恩良童鞋补充下). 客户端jboss 使用如下格式在datasource-<appName>.xml 中配置

<xa-datasource-property name="URL">
jdbc:oracle:thin:@(description=(address_list=(load_balance=on)(failover=on)(address=(protocol=tcp)(host=floating vip1)(port=xxx))(address=(protocol=tcp)(host=floating vip2)(port=xxx)))(connect_data=(service_name=xxx)(failover_mode=(type=select)(method=basic))))
</xa-datasource-property>
方案2
使用一个个floating VIP , 如图所示。 floating VIP 优先绑定RAC 中的两个db server 物理地址, 当任何一个db 不可用时, floating VIP从双IP 漂移到单IP, 在db 宕机恢复后, floating VIP 重新恢复绑定双IP。
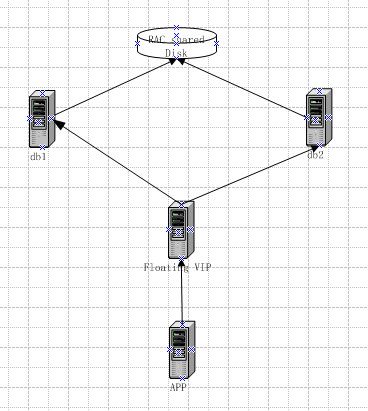
那么客户端的db 连接配置如下
<xa-datasource-property name="URL">
jdbc:oracle:thin:@(description=(address=(protocol=tcp)(host=floating VIP)(port=xxx))(connect_data=(service_name=xxx)))
</xa-datasource-property>
方案比较测试
比较测试的目的是为了验证floating VIP 是否能够解决我们线上的问题, 并且比较两种floating 方案的优劣
测试环境
乘着WMS DB 升级RAC 的机会, 我们在测试环境终于等到一套环境可以用来玩RAC了。 目前RAC 是这样的(这里的IP都是隐去的真实的IP,用户名密码信息和floating VIP 域名)
- 物理IP 192.1.1.101 server 上有sid wms1, service name wms 的Oracle 实例
- 物理IP 192.1.1.102 server 上有sid wms2, service name wms 的Oracle 实例
- wms1, wms2 共用同一个高速存储
- wms1, wms2 分配给应用的user/PWD 相同, 为 wms/wmspass
- 我们使用wms-vip1.com, wms-vip1.com 和wms-vip.com 三个floating VIP
测试手段
- 机器部署Jboss 并发布WMS ear 包
- 在PC 机上使用Jmeter 脚本以160 个线程的并发无限循环发送请求到172.18.48.122, 请求的序列为
- Logon
- 如果Logon 成功, List当前用户下的最多 50 个最新的Customer
- 在Jmeter 不断制造访问压力给Jboss 上的应用的时候, 我们对RAC 中的某个DB 实例进行重启, 分为软重启和硬重启
- 软重启: 命令行shutdown Oracle 实例, 等20 分钟后启动Oracle 实例
- 硬重启:命令行restart linux OS, 等linux 启动完毕, 15 分钟后启动Oracle 实例
测试步骤和测试数据
双floating VIP 方式:
<xa-datasource-property name="URL">
jdbc:Oracle:thin:@(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = wms-vip1.com)(PORT = 1521))(ADDRESS = (PROTOCOL = TCP)(HOST = wms-vip2.com)(PORT = 1521))(LOAD_BALANCE = yes)(FAILOVER = yes)(CONNECT_DATA =(SERVER = DEDICATED)(SERVICE_NAME = wms)(FAILOVER_MODE=(TYPE = SELECT)(METHOD = BASIC)(RETIRES = 180)(DELAY = 15))))
</xa-datasource-property>
Oracle 软重启方式
- 在Jmeter 执行界面看到在Oracle RAC 中其中一个实例在Shutdown的瞬间有8 个错误, 通过后台日志, 可以看到的是 db connection cannot be open
- 过了重启Shutdown 时间窗口以后再没有其他和DB相关的错误;
- 在Oracle 实例Shutdown 前 oracle instance1 有31 个连接, Oracle instance2 有39 个连接;
- Shutdown instance1 以后 instance2 连接数到63 个, instance1 0个
- 启动instance1 以后, instance2 连接数在大约15 分钟(可能需要的时间更少, 我们是在大约15 分钟后重新检查的)后降到35 个, instance 1 中连接数达到33个
Oracle 硬重启方式
- 在Jmeter 执行界面可以看到大概有162 个错误(猜测是Jemter 执行160个线程正在被Jboss执行中的140个), 查看后台日志如下错误类型
- Db connection 连接错误
- DB commit abort 错误
- 其他还有若干拿到的DBconnection 为Null 的错误
- 过了Shutdown 时间窗口以后再没有其他和DB相关的错误;
- 在Oracle 实例上的压力分摊类似Oracle 软重启, 不再累述
单floating VIP 方式:
<xa-datasource-property name="URL">
jdbc:oracle:thin:@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=wms-vip.com)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=wms)))
</xa-datasource-property>
Oracle 软重启方式
- 在Jmeter 执行界面看到在Oracle RAC 中其中一个实例在Shutdown的瞬间没有任何Http 请求返回错误
- 在Oracle 实例上的压力分摊类似双VIP配置 下的Oracle 软重启
Oracle 硬重启方式
- 在Jmeter 执行界面可以看到大概有140 个错误(猜测是Jemter 执行160个线程正在被Jboss执行中的140个), 查看后台日志如下错误类型
- Db connection 连接错误
- DB commit abort 错误
- 其他还有若干拿到的DBconnection 为Null 的错误
- 过了Shutdown 时间窗口以后再没有其他和DB相关的错误;
- 在Oracle 实例上的压力分摊类似Oracle 软重启, 不再累述
结论和建议
从测试结果看,
- JBoss会自动重联到重启的instance
- 达到平衡的时间应该在15分钟以内
- 两种Floating VIP 方式在Oracle 实例硬重启的时候表现大体相同
- 对Oracle 实例软重启情况下, 使用单一floating VIP在可用性上有更好的表现
建议单一VIP 方式。对应用可以屏蔽掉很多的DB 的细节。
注意事项
在RAC 环境中, 因为db 实例1 和实例2 的一定是使用不同的SID但是共用相同的service name,
所以我们这种db 连接的配置就不灵光了
<xa-datasource-property name="URL">jdbc:oracle:thin:@floating-IP:port:SID</xa-datasource-property>
必须使用类似下面的配置方式
<xa-datasource-property name="URL">
jdbc:oracle:thin:@(description=(address=(protocol=tcp)(host=floating VIP)(port=xxx))(connect_data=(service_name=xxx)))
</xa-datasource-property>
希望注意下。