从一道Neusoft题中想到的Java日志API
先来看看这一季度的试题的总体要求:
部门已经完成了多次编程考试,为了方便对每个人的考试情况进行跟踪,需要
将所有人员的成绩进行合并、汇总。
历次考试成绩格式为Excel格式,共有三列数据:邮件地址、姓名、成绩。为了
简化代码实现,在统计时,会先将Excel格式的成绩单“另存为”保存类型为“文本文件
(制表符分隔)(*.txt)”格式的文件,文件名称格式为“yyyymm.txt”(即:4位年份2位
月分.txt),作为程序的输入文件进行读取、合并操作。
输入文件保存在c:\test\src\文件夹下,此文件夹下不会有其它文件。在汇总处
理之前,我们会检查此文件夹下的输入文件,确保文件名符合输入要求。
在读取文件进行处理的过程中,如果遇到非法的数据,可以直接跳过当前人员的
成绩,继续处理其它数据。同时,需要将错误发生的源文件名,错误发生的行数,及
所在行内容记录在日志文件c:\test\test.log文件中。
记录信息为“数据错误:yyyymm.txt 第 N 行。”。其中,yyyymm.txt、N分别为实际
的文件名与行数。
合并后文件格式仍为文本文件,前两列为:邮件地址、姓名,从第三列开始,按
考试日期先后顺序逐一列出每次考试的成绩,如果某次考试缺考,则成绩以“--”
代替。合并后文件名称为“result.txt”,保存在c:\test\文件夹下。
便于后续做进一步检索与处理,输出文件格式需要严格符合下面的要求:
1)不需要有表头列,从文件第一行开始即为人员的成绩。
2)列宽与对齐方式:前两列,“邮件地址”列宽30字符,左对齐;“姓名”列宽15
字符,左对齐;从第三列开始,列宽统一为4字符且右对齐。
3)每位人员的成绩为一行数据,行末换行要符合windows平台习惯。
4)人员成绩按姓名的汉语拼音顺序排序,如果姓名相同,按邮件地址字母顺序排序。
附件给出输入文件与输出文件的示例,可仔细阅读以帮助理解上述格式要求。
提示:1)如果采用Java语言完成,编程过程中可以使用apache commons包中的api(这个
建议与考查的内容无关,至少便于对文件读写,评分是不会有任何影响)。
例如:固定列宽并且有对齐要求的文本格式化,可以使用commons-lang包中StringUtils
提供的LeftPad、RightPad方法(当然,这现方式并不强制要求,你也可以直接使用jdk
提供的PrintWriter.printf或者String.format或者其它方法这现同样的目的,选择自己
熟悉的就可以)
除以上包以外,请使用j2se6.0的标准内容。引入其他第3方库(如使用数据库)并不符合
考试要求。
2)日志记录推荐使用log4j或log4net。配置格式不做强制要求,但需要在源文件存在错误
时按要求记录问题。
我们仍然忽略任何第三方API,只要是Java API能完成的工作,我们不只用第三方工具。看了这个需求,其中需要进行日志的操作和数据格式化输出,其余就是简单IO和一个合并算法。日中日志我们可以使用java.util.logging的API,数据格式化就使用String.format()方法,下面我们来分析分析。
要使用Java的日志API,结合使用比较多的Log4j,首先想到的是日志的配置,下面来看看如何配置Java的日志API:
这个类是用来规范日志记录格式的,我们自定义的日志记录方式可以通过扩展Formatter类来进行,覆盖其中的format方法即可,其中的程序是生成日期,然后返回我们要在日志中看到的日志格式,这都很好理解,就不多说什么了。
写好了日志格式,那么在实际中该如何来使用呢,也很简单:
在类中声明一个静态的成员变量,然后对其进行一些设置,这里包括日志级别,输出位置和格式,那么格式就是上面那个类中设置的,调用setLoggerSettings()方法之后,就可以使用日志API了,这很简单。
下面来分析题目需求,要从几个文件中来读取信息然后进行合并,文件中可能有非法数据,要进行处理。文件中的信息包括电子邮件,姓名和每次的成绩,要求合并成绩到一条记录中,那么我们就要首先读取这些信息,然后进行合并处理。信息是用制表符分隔的,那么读取上来后就要根据制表符分割,如果发现分割出现问题,就记录日志。
首先抽象出数据中的对象,就是考试记录对象,我们简单刻画这个对象:
这里可说的不多,主要是构造方法,重载的方法有一个是填充record的,就是每条记录的成绩,而records变量是我们后期进行填充的。
我们开始编写readFromFile(String basePath)方法:
这些变量用于对数据进行处理。flagSet一看名字就是一个标识位,为什么用Set,因为合并之后每人是一条记录,那么处理后就合并了,而原始数据中一个人的信息可能有多条,那么我们要记录到底有多少不重复的人,就使用Set了,它会为我们自动去除重复的,同时TreeSet会按找字母顺序为我们自动排序,那么需求中的要求就满足了,我们不用再写排序的方法。InfoList用于放置从文件连续读出的原始数据,recordList是方法返回的结果,也是我们写入结果文件的最终对象,recordsPerFile是辅助变量,用于存储从每个文件中读取的文件数量,这是处理拼装大规模数据的基本方法,用于后期数据处理时的循环变量控制。
这部分就是从文件夹下读取文件并写入我们准备的变量中,首先进行文件夹判断,之后开始读取,我们将数据分行读取,然后用split函数对原始数据进行分隔,如果没有得到3个数据部分,那么视为该数据无效,就写日志,如果获取到了三个部分,首先将电子邮件和姓名存入Set,剩余信息存入infoList,使用辅助循环变量num来计算数量。
至此,我们已经读取到所需数据了,下面就是对数据进行处理了,首先是对我们的结果recordList进行一些初始化操作:
这里我们可以从flagSet中获取最终结果数量,然后对应写入recordList并初始化records数组,就做完了,下面是对成绩的处理了,这部分涉及到题目的核心算法,下面所示代表我的一个处理方式,可能不是最好的:
解释一下:我们首先变量recordsPerFile,这里标识出一共读取出几个文件,每个文件中的记录数量是多少,下面的while循环是变量recordList,就是我们每次要处理几个用户。进入while循环,首先获取一个ExamRecord对象,然后对其成绩栏位进行填充,如果没有值,那么就是”--”,下面开始处理infoList部分,这里就看到辅助变量的用途了,因为每个文件中可能没有全部人员的记录,就是文件记录数小于总人数,那么怎么办呢,每次遍历多少呢?就是辅助变量中记录的数据,两个集合的记录数不同,也同时可以遍历来进行对比处理,这就是一种方法,如果发现相同数据,在相应位置填充,最后的for循环是删除我们处理过的数据,每次删除0号元素,删除的次数是辅助变量中记录的。此时我们的数据处理完成,获得了recordList。
下面是写入文件的操作:
这里就没什么多说的了,就是需求中要求对数据格式进行处理,左对齐还是右对齐也很简单了。这里使用了C语言中printf()函数的格式,String的format()方法支持这点,就很简单了。
主函数如下:
执行主函数,就可以在相应位置看到结果。
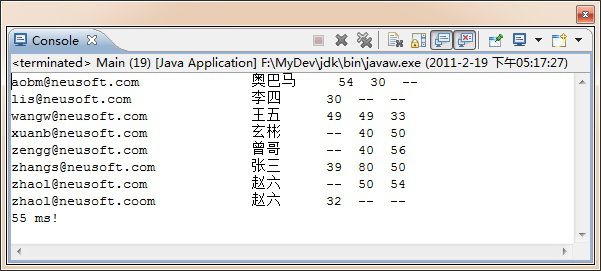
原始数据和源码见附件。本文系作者本人的探索,希望大家批评指正。也希望和Neusofter们交流提高。
部门已经完成了多次编程考试,为了方便对每个人的考试情况进行跟踪,需要
将所有人员的成绩进行合并、汇总。
历次考试成绩格式为Excel格式,共有三列数据:邮件地址、姓名、成绩。为了
简化代码实现,在统计时,会先将Excel格式的成绩单“另存为”保存类型为“文本文件
(制表符分隔)(*.txt)”格式的文件,文件名称格式为“yyyymm.txt”(即:4位年份2位
月分.txt),作为程序的输入文件进行读取、合并操作。
输入文件保存在c:\test\src\文件夹下,此文件夹下不会有其它文件。在汇总处
理之前,我们会检查此文件夹下的输入文件,确保文件名符合输入要求。
在读取文件进行处理的过程中,如果遇到非法的数据,可以直接跳过当前人员的
成绩,继续处理其它数据。同时,需要将错误发生的源文件名,错误发生的行数,及
所在行内容记录在日志文件c:\test\test.log文件中。
记录信息为“数据错误:yyyymm.txt 第 N 行。”。其中,yyyymm.txt、N分别为实际
的文件名与行数。
合并后文件格式仍为文本文件,前两列为:邮件地址、姓名,从第三列开始,按
考试日期先后顺序逐一列出每次考试的成绩,如果某次考试缺考,则成绩以“--”
代替。合并后文件名称为“result.txt”,保存在c:\test\文件夹下。
便于后续做进一步检索与处理,输出文件格式需要严格符合下面的要求:
1)不需要有表头列,从文件第一行开始即为人员的成绩。
2)列宽与对齐方式:前两列,“邮件地址”列宽30字符,左对齐;“姓名”列宽15
字符,左对齐;从第三列开始,列宽统一为4字符且右对齐。
3)每位人员的成绩为一行数据,行末换行要符合windows平台习惯。
4)人员成绩按姓名的汉语拼音顺序排序,如果姓名相同,按邮件地址字母顺序排序。
附件给出输入文件与输出文件的示例,可仔细阅读以帮助理解上述格式要求。
提示:1)如果采用Java语言完成,编程过程中可以使用apache commons包中的api(这个
建议与考查的内容无关,至少便于对文件读写,评分是不会有任何影响)。
例如:固定列宽并且有对齐要求的文本格式化,可以使用commons-lang包中StringUtils
提供的LeftPad、RightPad方法(当然,这现方式并不强制要求,你也可以直接使用jdk
提供的PrintWriter.printf或者String.format或者其它方法这现同样的目的,选择自己
熟悉的就可以)
除以上包以外,请使用j2se6.0的标准内容。引入其他第3方库(如使用数据库)并不符合
考试要求。
2)日志记录推荐使用log4j或log4net。配置格式不做强制要求,但需要在源文件存在错误
时按要求记录问题。
我们仍然忽略任何第三方API,只要是Java API能完成的工作,我们不只用第三方工具。看了这个需求,其中需要进行日志的操作和数据格式化输出,其余就是简单IO和一个合并算法。日中日志我们可以使用java.util.logging的API,数据格式化就使用String.format()方法,下面我们来分析分析。
要使用Java的日志API,结合使用比较多的Log4j,首先想到的是日志的配置,下面来看看如何配置Java的日志API:
package logging;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.logging.Formatter;
import java.util.logging.LogRecord;
/**
* 日志记录器格式
*
* @author Nanlei
*
*/
public class LogFormatter extends Formatter {
@Override
public String format(LogRecord record) {
Date date = new Date();
DateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String dateStr = df.format(date);
return "[" + dateStr + "] [" + record.getLevel() + "]"
+ record.getClass() + " : " + record.getMessage() + "\n";
}
}
这个类是用来规范日志记录格式的,我们自定义的日志记录方式可以通过扩展Formatter类来进行,覆盖其中的format方法即可,其中的程序是生成日期,然后返回我们要在日志中看到的日志格式,这都很好理解,就不多说什么了。
写好了日志格式,那么在实际中该如何来使用呢,也很简单:
private static final Logger logger = Logger.getLogger(Main.class.getName());
private static void setLoggerSettings() throws Exception {
logger.setLevel(Level.INFO);
FileHandler fileHandler = new FileHandler("c:\\test\\test.log");
fileHandler.setFormatter(new LogFormatter());
logger.addHandler(fileHandler);
}
在类中声明一个静态的成员变量,然后对其进行一些设置,这里包括日志级别,输出位置和格式,那么格式就是上面那个类中设置的,调用setLoggerSettings()方法之后,就可以使用日志API了,这很简单。
下面来分析题目需求,要从几个文件中来读取信息然后进行合并,文件中可能有非法数据,要进行处理。文件中的信息包括电子邮件,姓名和每次的成绩,要求合并成绩到一条记录中,那么我们就要首先读取这些信息,然后进行合并处理。信息是用制表符分隔的,那么读取上来后就要根据制表符分割,如果发现分割出现问题,就记录日志。
首先抽象出数据中的对象,就是考试记录对象,我们简单刻画这个对象:
package bean;
/**
* 考试记录bean
*
* @author Nanlei
*
*/
public class ExamRecord {
private String email;// 电子邮件
private String name;// 人名
private String record;// 单条成绩
private String[] records;// 考试记录
public ExamRecord() {
super();
}
public ExamRecord(String email, String name, String record) {
super();
this.email = email;
this.name = name;
this.record = record;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getRecord() {
return record;
}
public void setRecord(String record) {
this.record = record;
}
public String[] getRecords() {
return records;
}
public void setRecords(String[] records) {
this.records = records;
}
@Override
public String toString() {
return "ExamRecord [email=" + email + ", name=" + name + ", record="
+ record + ", records=" + records + "]";
}
}
这里可说的不多,主要是构造方法,重载的方法有一个是填充record的,就是每条记录的成绩,而records变量是我们后期进行填充的。
我们开始编写readFromFile(String basePath)方法:
Set<String> flagSet = new TreeSet<String>(); List<ExamRecord> infoList = new ArrayList<ExamRecord>(); List<ExamRecord> recordList = new ArrayList<ExamRecord>(); List<Integer> recordsPerFile = new ArrayList<Integer>();// 标识每个文件中合法记录的数量
这些变量用于对数据进行处理。flagSet一看名字就是一个标识位,为什么用Set,因为合并之后每人是一条记录,那么处理后就合并了,而原始数据中一个人的信息可能有多条,那么我们要记录到底有多少不重复的人,就使用Set了,它会为我们自动去除重复的,同时TreeSet会按找字母顺序为我们自动排序,那么需求中的要求就满足了,我们不用再写排序的方法。InfoList用于放置从文件连续读出的原始数据,recordList是方法返回的结果,也是我们写入结果文件的最终对象,recordsPerFile是辅助变量,用于存储从每个文件中读取的文件数量,这是处理拼装大规模数据的基本方法,用于后期数据处理时的循环变量控制。
File file = new File(basePath);
if (!file.isDirectory()) {
logger.info(file.getAbsolutePath() + " is not a directory");
} else {
try {
String[] files = file.list();
for (int i = 0; i < files.length; i++) {
File targetFile = new File(basePath + "\\" + files[i]);
BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream(
targetFile), "GBK"));
String s = null;
int line = 0;
int num = 0;
while ((s = br.readLine()) != null) {
if (line == 0) {
} else {
String[] infos = s.split("\t");
if (infos.length != 3) {
logger.info("错误数据 " + files[i] + " 第"
+ (line + 1) + "行");
} else {
flagSet.add(infos[0] + "\t" + infos[1]);
infoList.add(new ExamRecord(infos[0], infos[1],
infos[2]));
num++;
}
}
line++;
}
recordsPerFile.add(num);
br.close();
}
} catch (Exception e) {
e.printStackTrace();
}
这部分就是从文件夹下读取文件并写入我们准备的变量中,首先进行文件夹判断,之后开始读取,我们将数据分行读取,然后用split函数对原始数据进行分隔,如果没有得到3个数据部分,那么视为该数据无效,就写日志,如果获取到了三个部分,首先将电子邮件和姓名存入Set,剩余信息存入infoList,使用辅助循环变量num来计算数量。
至此,我们已经读取到所需数据了,下面就是对数据进行处理了,首先是对我们的结果recordList进行一些初始化操作:
Iterator<String> it = flagSet.iterator();
String str = null;
while (it.hasNext()) {
str = it.next();
String[] infos = str.split("\t");
ExamRecord er = new ExamRecord();
er.setEmail(infos[0]);
er.setName(infos[1]);
String[] arrays = new String[recordsPerFile.size()];
er.setRecords(arrays);
recordList.add(er);
}
这里我们可以从flagSet中获取最终结果数量,然后对应写入recordList并初始化records数组,就做完了,下面是对成绩的处理了,这部分涉及到题目的核心算法,下面所示代表我的一个处理方式,可能不是最好的:
// 开始处理成绩
for (int i = 0; i < recordsPerFile.size(); i++) {
int num = recordsPerFile.get(i);
int count = 0;
while (count < recordList.size()) {
ExamRecord tmpER = recordList.get(count);
tmpER.getRecords()[i] = "--";
for (int j = 0; j < num; j++) {
ExamRecord er = infoList.get(j);
if (tmpER.getEmail().equals(er.getEmail())) {
tmpER.getRecords()[i] = er.getRecord();
}
}
count++;
}
for (int k = 0; k < num; k++) {
infoList.remove(0);
}
}
解释一下:我们首先变量recordsPerFile,这里标识出一共读取出几个文件,每个文件中的记录数量是多少,下面的while循环是变量recordList,就是我们每次要处理几个用户。进入while循环,首先获取一个ExamRecord对象,然后对其成绩栏位进行填充,如果没有值,那么就是”--”,下面开始处理infoList部分,这里就看到辅助变量的用途了,因为每个文件中可能没有全部人员的记录,就是文件记录数小于总人数,那么怎么办呢,每次遍历多少呢?就是辅助变量中记录的数据,两个集合的记录数不同,也同时可以遍历来进行对比处理,这就是一种方法,如果发现相同数据,在相应位置填充,最后的for循环是删除我们处理过的数据,每次删除0号元素,删除的次数是辅助变量中记录的。此时我们的数据处理完成,获得了recordList。
下面是写入文件的操作:
private static void writeResultToFile(String fileName,
List<ExamRecord> recordList) {
BufferedOutputStream output = null;
try {
output = new BufferedOutputStream(new FileOutputStream(fileName));
for (int i = 0; i < recordList.size(); i++) {
ExamRecord examRecord = recordList.get(i);
output.write(String.format("%-30s", examRecord.getEmail())
.getBytes());
output.write(String.format("%-15s", examRecord.getName())
.getBytes());
for (int j = 0; j < examRecord.getRecords().length; j++) {
output.write(String.format("%4s",
examRecord.getRecords()[j]).getBytes());
}
output.write("\r\n".getBytes());
}
output.flush();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (output != null) {
output.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
这里就没什么多说的了,就是需求中要求对数据格式进行处理,左对齐还是右对齐也很简单了。这里使用了C语言中printf()函数的格式,String的format()方法支持这点,就很简单了。
主函数如下:
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
// 设置Log
setLoggerSettings();
// 读取文件到对象中
List<ExamRecord> recordList = readFromFile("c:\\test\\src");
// 将结果写入文件
writeResultToFile("c:\\test\\result.txt", recordList);
long end = System.currentTimeMillis();
System.out.println(end - start + " ms!");
}
执行主函数,就可以在相应位置看到结果。
原始数据和源码见附件。本文系作者本人的探索,希望大家批评指正。也希望和Neusofter们交流提高。