ZZ SMAQ:海量数据的存储计算和查询模型
本文翻译自The SMAQ stack for big data
英文原文:http://radar.oreilly.com/2010/09/the-smaq-stack-for-big-data.htm
译者:phylips@bmy
出处:http://duanple.blog.163.com/blog/static/709717672011016103028473/
海量数据(“Big Data”)是指那些足够大的数据,以至于无法再使用传统的方法进行处理。在过去,一直是Web搜索引擎的创建者们首当其冲的面对这个问题。而今天,各种社交网络,移动应用以及各种传感器和科学领域每天创建着上PB的数据。 为了应对这种大规模数据处理的挑战,google创造了MapReduce。Google的工作以及yahoo创建的Hadoop孵化出一个完整的海量数据处理工具的生态系统。
随着MapReduce的流行,一个由数据存储层,MapReduce和查询(简称SMAQ)组成的海量数据处理的栈式模型也逐渐展现出来。SMAQ系统通常是开源的,分布式的,运行在普通硬件上。

就像由Linux, Apache, MySQL and PHP 组成的LAMP改变了互联网应用开发领域一样,SMAQ将会把海量数据处理带入一个更广阔的天地。正如LAMP成为Web2.0的关键推动者一样,SMAQ系统将支撑起一个创新的以数据为驱动的产品和服务的新时代。
尽管基于Hadoop的架构占据了主导地位,但是SMAQ模型也包含大量的其他系统,包括主流的NoSQL数据库。这篇文章描述了SMAQ栈式模型以及今天那些可以包括在这个模型下的海量数据处理工具。
MapReduce
MapReduce是google为创建web网页索引而创建的。MapReduce框架已成为今天大多数海量数据处理的厂房。MapReduce的关键在于,将在数据集合上的一个查询进行划分,然后在多个节点上并行执行。这种分布式模式解决了数据太大以至于无法存放在单独一台机器上的难题。
为了理解MapReduce是如何工作的,我们首先看它名字所体现出的两个过程。首先在map阶段,输入数据被一项一项的处理,转换成一个中间结果集,然后在reduce阶段,这些中间结果又被规约产生一个我们所期望得到的归纳结果。
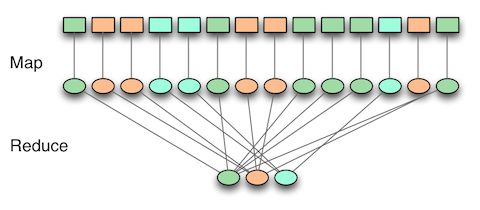
说到MapReduce,通常要举的一个例子就是查找一篇文档中不同单词的出现个数。在map阶段单词被抽出来,然后给个count值1,在reduce节点,将相同的单词的count值累加起来。
看起来是不是将一个很简单的工作搞地很复杂了,这就是MapReduce。为了让MapReduce完成这项任务,map和reduce阶段必须遵守一定的限制来使得工作可以并行化。将查询请求转换为一个或者多个MapReduce并不是一个直观的过程,为了解决这个问题,一些更高级的抽象被提出来,我们将在下面关于查询的那节里进行讨论。
使用MapReduce解决问题,通常需要三个操作:
数据加载—用数据仓库的叫法,这个过程叫做抽取(extract),转换(transform),加载(load){简称ETL}更合适些。为了利用MapReduce进行处理,数据必须从源数据里抽取出来,进行必要的结构化,加载到MapReduce可以访问的存储层。
MapReduce—从存储层访问数据,进行处理,再将结果返回给存储层
结果抽取—一旦处理完毕,为了让结果对于人来说是可用的,还需要能够将存储层的结果数据进行查询和展示。
很多SMAQ系统都具有自身的一些属性,主要就是围绕上述三个过程的简化。
Hadoop MapReduce
Hadoop是主要的开源MapReduce实现。由yahoo资助,2006年由Doug Cutting 创建,2008年达到了web规模的数据处理容量。
Hadoop项目现在由Apache管理。随着不断的努力,和多个子项目一起共同构成了完整的SMAQ模型。
由于是用java实现的,所以Hadoop的MapReduce实现可以通过java语言交互。创建MapReduce job通常需要写一些函数用来实现map和reduce阶段需要做的计算。处理数据必须能够加载到Hadoop的分布式文件系统中。
以wordcount为例,map函数如下(来源于Hadoop MapReduce文档,展示了其中关键的步骤)
public static class Map
extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
对应的reduce函数如下:
public static class Reduceextends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
使用Hadoop运行一个MapReduce job包括如下几个步骤:
1. 用一个java程序定义MapReduce的各个阶段
2. 将数据加载进文件系统
3. 提交job进行执行
4. 从文件系统获取执行结果
直接通过java API,Hadoop MapReduce job写起来可能很复杂,需要程序员很多方面的参与。为了让数据加载和处理工作更加简单直接,围绕着Hadoop一个很大的生态系统已经形成。
其他实现
MapReduce已经在很多其他的程序语言和系统中实现,详细的列表可以参考Wikipedia's entry for MapReduce .。尤其是几个NoSQL数据已经集成了MapReduce,后面我们会对此进行描述。
Storage
从数据获取到结果存放,MapReduce都需要与存储打交道。与传统数据库不同,MapReduce的输入数据并不是关系型的。输入数据存放在不同的chunk上,能够划分给不同的节点,然后提供以key-value的形式提供给map阶段。数据不需要一个schema,而且可能是无结构的。但是数据必须是可分布的,能够提供给不同的处理节点。
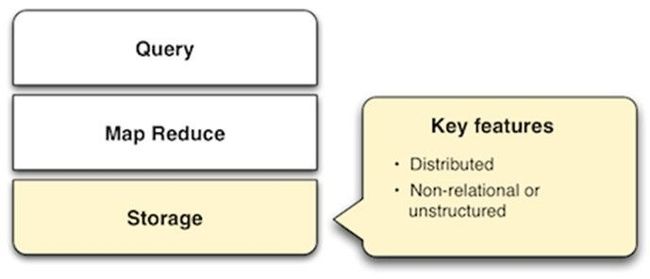
存储层的设计和特点很重要不仅仅是因为它与MapReduce的接口,而且因为它们直接决定了数据加载和结果查询和展示的方便性。
Hadoop分布式文件系统
Hadoop使用的标准存储机制是HDFS。作为Hadoop的核心部分,HDFS有如下特点,详细参见HDFS design document .:
容错 -- 假设失败是常态允许HDFS运行在普通硬件上
流数据访问 – HDFS实现时考虑的是批量处理,因此着重于高吞吐率而不是数据的随机访问
高度可扩展性 – HDFS可以扩展到PB级的数据,比如Facebook就有一个这样的产品级使用
可移植性 – Hadoop是可以跨操作系统移植的
单次写 – 假设文件写后不会改变,HDFS简化了replication提高了数据吞吐率
计算本地化 – 考虑到数据量,通常将程序移到数据附近执行会更快,HDFS提供了这方面的支持
HDFS提供了一个类似于标准文件系统的接口。与传统数据库不同,HDFS只能进行数据存储和访问,而不能为数据建立索引。无法对数据进行简单的随机访问。但是一些更高级的抽象已经创建出来,用来提供对Hadoop的更细粒度的功能,比如HBase。
HBase,Hadoop数据库
一种使HDFS更具可用性的方法是HBase。模仿谷歌的BigTable数据库,HBase也是一个设计用来存储海量数据的列存式数据库。它也属于NoSQL数据库范畴,类似于Cassandra and Hypertable。
HBase使用HDFS作为底层存储系统,因此也具有通过大量容错分布式节点来存储大量的数据的能力。与其他的列存储数据库类似,HBase也提供基于REST和Thrift的访问API。
由于创建了索引,HBase可以为一些简单的查询提供对内容快速的随机访问。对于复杂的操作,HBase为Hadoop MapReduce提供数据源和存储目标。因此HBase允许系统以数据库的方式与MapReduce进行交互,而不是通过底层的HDFS。
Hive
数据仓库或者是使报告和分析更简单的存储方式是SMAQ系统的一个重要应用领域。最初在Facebook开发的Hive,是一个建立在Hadoop之上是数据仓库框架。类似于HBase,Hive提供一个在HDFS上的基于表的抽象,简化了结构化数据的加载。与HBase相比,Hive只能运行MapReduce job进行批量数据分析。如下面查询那部分描述的,Hive提供了一个类SQL的查询语言来执行MapReduce job。
Cassandra and Hypertable
Cassandra和 Hypertable都是具有BigTable模式的类似于HBase的列存储数据库。

作为Apache的一个项目,Cassandra最初是在Facebook产生的。现在应用在很多大规模的web站点,包括Twitter, Facebook, Reddit and Digg。Hypertable产生于Zvents,现在也是一个开源项目。
这两个数据库都提供与Hadoop MapReduce交互的接口,允许它们作为Hadoop MapReduce job的数据源和目标。在更高层次上,Cassandra提供与Pig查询语言的集成(参见查询章节),而Hypertable已经与Hive集成。
NoSQL数据库的MapReduce实现
目前为止我们提到的存储解决方案都是依赖于Hadoop进行MapReduce。还有一些NoSQL数据库为了对存储数据进行并行计算本身具有内建的Mapreduce支持。与Hadoop系统的多组件SMAQ架构不同,它们提供一个由storage, MapReduce and query一体组成的自包含系统。
基于Hadoop的系统通常是面向批量处理分析,NoSQL存储通常是面向实时应用。在这些数据库里,MapReduce通常只是一个附加功能,作为其他查询机制的一个补充而存在。比如,在Riak里,对MapReduce job通常有一个60秒的超时限制,而通常来说, Hadoop 认为一个job可能运行数分钟或者数小时。
下面的这些NoSQL数据库都具有MapReduce功能:
CouchDB,一个分布式数据库,提供了半结构化的文档存储功能。主要特点是提供很强的多副本支持,以及可以进行分布式更新。在CouchDB里,查询是通过使用javascript定义MapReduce的map和reduce阶段实现的。
MongoDB,本身很类似于CouchDB,但是更注重性能,对于分布式更新,副本,版本的支持相对弱些。MapReduce也是通过javascript描述的。
Riak,与前面两个数据库也很类似。但是更关注高可用性。可以使用javascript或者Erlang描述MapReduce。
与关系型数据库的集成
在很多应用中,主要的源数据存储在关系型数据库中,比如Mysql或者Oracle。MapReduce通常通过两种方式使用这些数据:
使用关系型数据库作为源(比如社交网络中的朋友列表)
将MapReduce结果重新注入到关系型数据库(比如基于朋友的兴趣产生的产品推荐列表)
理解MapReduce如何与关系型数据库交互是很重要的。最简单的,通过组合使用SQL导出命令和HDFS操作,带分隔符的文本文件可以作为传统关系型数据库和Hadoop系统间的导入导出格式。更进一步的讲,还存在一些更复杂的工具。
Sqoop工具是设计用来将数据从关系型数据库导入到Hadoop系统。它是由Cloudera开发的,一个专注于企业级应用的Hadoop平台经销商。Sqoop是与具体数据库无关的,因为它使用了java的JDBC数据库API。可以将整个表导入,也可以使用查询命令限制需要导入的数据。
Sqoop也提供将MapReduce的结果从HDFS导回关系型数据库的功能。因为HDFS是一个文件系统,所以Sqoop需要以分隔符标识的文本为输入,需要将它们转换为相应的SQL命令才能将数据插入到数据库。
对于Hadoop系统来说,通过使用Cascading API中的cascading.jdbc 和 cascading-dbmigrate 也能实现类似的功能。
与streaming数据源的集成
关系型数据库以及流式数据源(比如web服务器日志,传感器输出)组成了海量数据系统的最常见的数据来源。Cloudera的Flume项目就是旨在提供流式数据源与Hadoop之间集成的方便工具。Flume收集来自于集群机器上的数据,将它们不断的注入到HDFS中。Facebook的Scribe服务器也提供类似的功能。
商业性的SMAQ解决方案
一些MPP数据库具有内建的MapReduce功能支持。MPP数据库具有一个由并行运行的独立节点组成的分布式架构。它们的主要功能是数据仓库和分析,可以使用SQL。
Greenplum:基于开源的PostreSQL DBMS,运行在分布式硬件组成的集群上。MapReduce作为SQL的补充,可以进行在Greenplum上的更快速更大规模的数据分析,减少了几个数量级的查询时间。Greenplum MapReduce允许使用由数据库存储和外部数据源组成的混合数据。MapReduce操作可以使用Perl或者Python函数进行描述。
Aster Data 的nCluster 数据仓库系统也提供MapReduce支持。MapReduce操作可以通过使用Aster Data的SQL-MapReduce 技术调用。SQL-MapReduce 技术可以使SQL查询和通过各种语言(C#, C++, Java, R or Python)的源代码定义的MapReduce job组合在一块。
其他的一些数据仓库解决方案选择提供与Hadoop的连接器,而不是在内部集成MapReduce功能。
Vertica :是一个提供了Hadoop连接器的列存式数据库。
Netezza :最近由IBM收购。与Cloudera合作提高了它与Hadoop之间的互操作性。尽管它解决了类似的问题,但是实际上它已经不在我们的SMAQ模型定义之内,因为它既不开源也不运行在普通硬件上。
尽管可以全部使用开源软件来创建一个基于Hadoop的系统,但是集成这样的一个系统仍然需要一些努力。Cloudera的目的就是使得Hadoop更能适应用企业化的应用,而且在它们的Cloudera Distribution for Hadoop (CDH)中已经提供一个统一的Hadoop发行版。
查询
通过上面的java代码可以看出使用程序语言定义MapReduce job的map和reduce过程并不是那么的直观和方便。为了解决这个问题,SMAQ系统引人了一个更高层的查询层来简化MapReduce操作和结果查询。

很多使用Hadoop的组织为了使操作更加方便,已经对Hadoop的API进行了内部的封装。有些已经成为开源项目或者商业性产品。
查询层通常并不仅仅提供用于描述计算过程的特性,而且支持对数据的存取以及简化在MapReduce集群上的执行流程。
Pig
由yahoo开发,目前是Hadoop项目的一部分。Pig提供了一个称为Pig Latin的高级查询语言来描述和运行MapReduce job。它的目的是让Hadoop更容易被那些熟悉SQL的开发人员访问,除了一个Java API,它还提供一个交互式的接口。Pig目前已经集成在Cassandra 和HBase数据库中。 下面是使用Pig写的上面的wordcount的例子,包括了数据的加载和存储过程($0代表记录的第一个字段)。
input = LOAD 'input/sentences.txt' USING TextLoader();
words = FOREACH input GENERATE FLATTEN(TOKENIZE($0));
grouped = GROUP words BY $0;
counts = FOREACH grouped GENERATE group, COUNT(words);
ordered = ORDER counts BY $0;
STORE ordered INTO 'output/wordCount' USING PigStorage();
Pig是非常具有表达力的,它允许开发者通过UDFs(User Defined Functions )书写一些定制化的功能。这些UDF使用java语言书写。尽管它比MapReduce API更容易理解和使用,但是它要求用户去学习一门新的语言。某些程度上它与SQL有些类似,但是它又与SQL具有很大的不同,因为那些熟悉SQL的人们很难将它们的知识在这里重用。
Hive
正如前面所述,Hive是一个建立在Hadoop之上的开源的数据仓库。由Facebook创建,它提供了一个非常类似于SQL的查询语言,而且提供一个支持简单内建查询的web接口。因此它很适合于那些熟悉SQL的非开发者用户。
与Pig和Cascading的需要进行编译相比,Hive的一个长处是提供即席查询。对于那些已经成熟的商务智能系统来说,Hive是一个更自然的起点,因为它提供了一个对于非技术用户更加友好的接口。Cloudera的Hadoop发行版里集成了Hive,而且通过HUE项目提供了一个更高级的用户接口,使得用户可以提交查询并且监控MapReduce job的执行。
Cascading, the API Approach
Cascading提供了一个对Hadoop的MapReduce API的包装以使它更容易被java应用程序使用。它只是一个为了让MapReduce集成到更大的系统中时更简单的一个包装层。Cascading包括如下几个特性:
旨在简化MapReduce job定义的数据处理API
一个控制MapReduce job在Hadoop集群上运行的API
访问基于Jvm的脚本语言,比如Jython, Groovy, or JRuby.
与HDFS之外的数据源的集成,包括Amazon S3,web服务器
提供MapReduce过程测试的验证机制
Cascading的关键特性是它允许开发者将MapReduce job以流的形式进行组装,通过将选定的一些pipes连接起来。因此很适用于将Hadoop集成到一个更大的系统中。 Cascading本身并不提供高级查询语言,由它而衍生出的一个叫Cascalog的开源项目完成了这项工作。Cascalog通过使用Clojure JVM语言实现了一个类似于Datalog的查询语言。尽管很强大,Cascalog仍然只是一个小范围内使用的语言,因为它既不像Hive那样提供一个类SQL,也不像Pig那样是过程性的。下面是使用Cascalog完成的wordcout的例子:
(defmapcatop split [sentence]
(seq (.split sentence "\\s +")))
(?<- (stdout) [?word ?count]
(sentence ?s) (split ?s :> ?word)
(c/count ?count))
使用Solr进行搜索
大规模数据系统的一个重要组件就是数据查询和摘要。数据库层比如HBase提供了对数据的简单访问,但是并不具备复杂的搜索能力。为了解决搜索问题。开源的搜索和索引平台Solr通常与NoSQL数据库组合使用。Solr使用Luence搜索技术提供一个自包含的搜索服务器产品。比如,考虑一个社交网络数据库,MapReduce可以使用一些合理的参数用来计算个人的影响力,这个数值会被写回到数据库。之后使用Solr进行索引,就允许在这个社交网络上进行一些操作,比如找到最有影响力的人。
最初在CENT开发,现在作为Apache项目的Solr,已经从一个单一的文本搜索引擎演化为支持导航和结果聚类。此外,Solr还可以管理存储在分布式服务器上的海量数据。这使得它成为在海量数据上进行搜索的理想解决方案,以及构建商业智能系统的重要组件。
总结
MapReduce尤其是Hadoop实现提供了在普通服务器上进行分布式计算的强有力的方式。再加上分布式存储以及用户友好的查询机制,它们形成的SMAQ架构使得海量数据处理通过小型团队甚至个人开发也能实现。
现在对数据进行深入的分析或者创建依赖于复杂计算的数据产品已经变得很廉价。其结果已经深远的影响了数据分析和数据仓库领域的格局,降低了该领域的进入门槛,培养了新一代的产品,服务和组织方式。这种趋势在Mike Loukides的"What is Data Science? "报告中有更深入的诠释。
Linux的出现仅仅通过一台摆在桌面上的linux服务器带给那些创新的开发者们以力量。SMAQ拥有同样大的潜力来提高数据中心的效率,促进组织边缘的创新,开启廉价创建数据驱动业务的新时代。