Trello架构分享
Trello架构学习
1.Trello简介
Trello是由著名的软件工程师 Joel Spolsky开发的一个团队协作平台,在TechCrunch Disrupt大会上正式发布。在不到3小时的时间内,Trello已经积累了5000多用户。 Trello上的工作都围绕“木板(board)”进行,同一小组的用户可以在这里创建待办事项列表(to do list)、创建任务,并分配给同事,当同事完成工作后可以把任务状态标记为完成,类似于producteev。你可以为每个项目创建一张卡片,里面包括活动、附件、更新、沟通内容等信息。你可以把同事拖拽到这些卡片中,然后把卡片拖到列表里。 和其他的项目管理系统都是以开发者为中心的,过于复杂,对普通用户缺乏吸引力。Trello则为各种流程设计,既可以当做公司的协作工具,也可以当做个人的列表管理工具。
2.CoffeeScript
CoffeeScript (GitHub repo) 是一个使用纯Ruby编写的新编程语言,创建者 Jeremy Ashkenas戏称它是- JavaScript的不那么铺张(买弄)的小兄弟。因为CoffeeScript会将Ruby编译成JavaScript,而且大部分结构都相似,但不同的是,CoffeeScript拥有更严格的语法。
3.client
Trello的服务器上实际上没有运行html代码。Trello的客户端是单个的经过精简和压缩的js文件(2k)(包括第三方库和编译过的CoffeeScript以及Mustache模板,压缩过的css代码和内联图片)。所有的这些都在250k以下。而且通过Amazon cloudfront内容分发网络提供的服务,所以在大多数地方都能提供低延迟的服务。在高带宽的情况下半秒内就能在浏览器中加载client。与此同时,放弃了使用ajax获取加载页的数据文本,运用websocket予以代替。
3.1Backbone.js
主要提供了3个东西:1、models(模型) 2、collections(集合) 3、views(视图)
Backbone.js文件本身很小,压缩后只有5.3KB,作为一个框架级别的核心JS文件,这个数字很可怕。除此之外,这个JS还必须依赖于另一个JS文件:underscore.js(包含许多工具方法,集合操作,js模板等等)。
用Backbone.Model表示应用中所有数据,models中的数据可以创建、校验、销毁和保存到服务端。当models中值被改变时自动触发一个"change"事件、所有用于展示models数据的views都会侦听到这个事件,然后进行重新渲染。
Backbone.Collection和我们平时接触的JAVA集合类相似,具有增加元素,删除元素,获取长度,排序,比较等一系列工具方法,说白了就是一个保存models的集合类。
Backbone使用views渲染那些从服务器下载下来的Models,然后提供了如下简易的方法。
1)通过views生成的html查看DOM事件,并且将这些事件与Models建立相关,这些模型会和服务器端重新同步
2)观察Models的变化,重新渲染Models的html块,以此来展示Models的变化。通过自己开发的客户端Models缓 存处理模型的更新和Models的重用。
官方主页:http://documentcloud.github.com/backbone/
3.2 Html5 pushState
页面加载完成后,不希望在页面间的切换上花费任何时间。因此运用了html5 pushState在页面间移动。这样就能给与地址栏适当的和一致的链接。要做的仅仅是将载入数据并且交付给适当的Backbone controller处理。
3.3 MUSTACHE
运用了mustache模板(一个逻辑很少的模板语言)来代替显示model的html。mustache使我们能够不用将将客户端逻辑代码与模板代码混合的情况下复用模板代码。
4.pushing and polling(推送和轮询)
实时更新不是一个新的话题,但是对于一个协同工具是相当重要的。
4.1 socket.io and websocket
客户端和服务端之间建立websocket链接,这样子服务端就能实时推送给在特定通道监听的浏览器。运用socket.io和服务端库,在占用cpu资源很少的情况下,同时维持好几千个websocket链接。
4.2 ajax polling
当客户断不支持websocket时,当一个用户活跃时,每几秒进行少量的ajax请求更新;当一个用户空闲时,每10秒进行轮询。由于我们的服务器配置,能够在使用很小开销的情况下,提供https请求并且保持TCP链接打开。
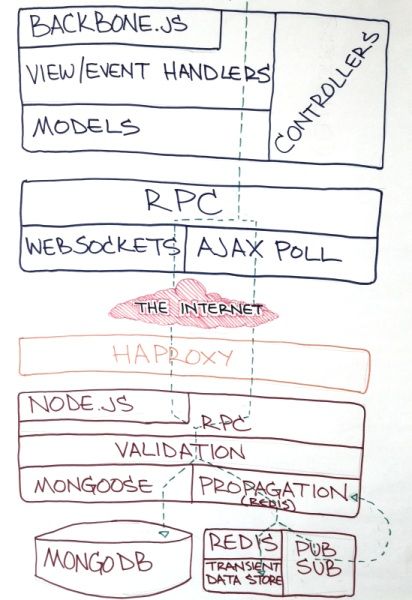
图1 原先的客户端架构
但是其间遇到了一个问题,在调整轮询活跃和空闲用户状态间隔后,解决了出现的怪异的问题。
5. server
5.1 node.js
trello服务端主要用node.js实现。trello需要的是即时更新,这就意味着要保持许多链接处于打开状态,因此消息驱动和非阻塞是一个好的选择。node.js也是一个让人惊讶的单页面app开发的原型工具。原型版的trello服务端仅仅是一个函数库。用来操作node.js单个进程的内存的Models队列。客户端仅仅是通过轻量级的websocket的封装调用这些函数。
我们增加了如下,是系统更为完善:
1)一个真实的DB和Schema(node-mongodb-natice and mongoose)
2)web基础技术,routes和cookies(Express 和 Connect)
3)多个服务器进程和零停机重启(cluster)
4)进程间切换和数据共享通过使用Redis(node_Redis)
使用了一个异步库async library,CoffeeScript,使我们的代码简洁并在可控制的范围内。
5.2 HAPROXY
用haproxy做为服务器间的负载均衡。
5.3 Redis
trello使用redis在服务器进程间共享生命周期较短的数据,这些数据不会持久化到磁盘。例如,session的活跃水平;临时地OpenID键。如果redis存储的这些数据全部或者部分丢失,那么应用程序能够自动恢复。我们在allkeys-lru配置下运行redis并且设置了比实际需要多5倍的空间。redis自动撤销在不久的将来没有被使用的数据,并且在需要时创建他们。
我们最有意思的应用是短轮询回调为了发送变化的数据到models下载到浏览器端。当一个server端的对象改变,我们发送一个josn消息,通过合适的websocket通知所有客户端浏览器,并且为受影响的model也存储该消息在一个固定长度的list,并且注意有多少消息存储在该list。这样,当一个clinet通过ajax轮询是否在服务端有对象改变时,在多数情况下我们能够得到整个服务器的响应在权限检查和检查单redis的值。Redis能够在一秒内做上千次这样的检查,所以它不会大幅削弱单个cpu的计算能力。
redis也是我们的发布和订阅服务器。我们用它发布对象的更改消息,来自服务器进程启动向其他服务器进程的请求。一旦你有一个redis服务器,你会开始在各种情况下使用他。
5.4 MongoDB
MongoDB弥补了许多我们对于传统数据库的需求。我们想让trello变得很快。我们所知道的最酷的,对于性能很着迷的团队就在我们隔壁StackExchange。在和他们的开发主管聊天时,了解到,即使用了sql-server作为数据存储,他们还是运用了很多反规格化的数据,为了获取更高的性能。
为了高速的读、写,我们放弃了关系型数据库的特征。并且有了反规格化的支持,我们能够在一个文档中存储一个card的数据,同时也能检索文档的子域和建立索引。
在用户增长很快的情况下有一个能够在读写方面合理的滥用,是一件很庆幸的事情。MongoDB能够很容易的进行复制、备份和恢复。
使用MongoDB松散文档存储的另一个好处是在同一个数据库下,运行不同版本的Trello,无须进行数据迁移。
文章翻译自:http://blog.fogcreek.com/the-trello-tech-stack/
中间有些省略了。可以和原文对照着看。