Axis2:AXIOM
Apache Axis2 Web 服务框架构建于新的 AXIOM XML 文档模型之上,可以进行高效的 SOAP 消息处理。与常规的文档模型不同,AXIOM 仅在被访问时才会在内存中构建文档表示。了解为什么这种按需构造的方法对于 SOAP 处理来说非常合适,以及为什么 XOP/MTOM 附件、数据绑定和性能非常适于这种情况。<!-- START RESERVED FOR FUTURE USE INCLUDE FILES--><!-- include java script once we verify teams wants to use this and it will work on dbcs and cyrillic characters --> <!-- END RESERVED FOR FUTURE USE INCLUDE FILES-->
Apache Axis2 1.1 已经发布,它为那些长期运行 Apache Web 服务框架系列的忠实用户提供了令人兴奋的新特性。我们将在后续的文章中讨论关于 Axis2 的内容,本文将深入研究 AXIs 对象模型 (AXIOM) XML 文档模型,这是 Axis2 的核心。AXIOM 是 Axis2 中一个主要的创新,并且是 Axis2 能够比原来的 Axis 提供更好性能的原因之一。本文将向您介绍 AXIOM 的工作原理、Axis2 的各个部分如何构建于 AXIOM 之上,以及 AXIOM 与其他的 Java™ 文档对象模型的性能比较。
文档模型通常用于对 XML 进行处理,并且在 Java 开发中有许多不同的文档模型可供使用,包括原始 W3C DOM 规范的各种实现、JDOM、dom4j、XOM 等等。每种模型都声称与其他模型相比具有某些优点,要么是在性能、灵活性方面,要么是在严格遵守 XML 标准的程度方面,并且每种模型都拥有忠实的支持者。那么,Axis2 为什么需要一种新的模型呢?答案在于 SOAP 消息的结构,尤其是如何在基本的 SOAP 框架中添加相应的扩展。
SOAP 本身仅仅只是 XML 应用程序负载的简单包装。清单 1 提供了一个示例,其中只有那些具有 soapenv 前缀的元素才真正是 SOAP 中定义的。文档中大部分是应用程序数据,这些数据组成了 soapenv:Body 元素的内容。
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Header/>
<soapenv:Body>
<matchQuakes xmlns="http://seismic.sosnoski.com/types">
<min-date>2001-01-06T11:10:43.446Z</min-date>
<max-date>2001-10-24T19:49:13.812Z</max-date>
<min-long>-150.94307</min-long>
<max-long>-22.594208</max-long>
<min-lat>-11.44651</min-lat>
<max-lat>55.089058</max-lat>
</matchQuakes>
</soapenv:Body>
</soapenv:Envelope>
|
尽管基本的 SOAP 包装非常简单,但是通过使用称为 Header 的可选组件,它提供了不受限制的扩展能力。Header 为添加各种各样的元数据提供了合适的位置,这些元数据与应用程序数据在一起,不会被应用程序看到(可以 在 Header 中包括应用程序数据,但是这样做并不是很合理,您应该将应用程序数据放在消息的正文部分)。构建于 SOAP 之上的扩展(如整个 WS-* 系列),可以使用 Header 实现相应的目标,而不会对应用程序造成任何影响。这允许将扩展作为外接程序使用,可以在部署时选择某个应用程序所需的特定扩展功能,而无需在代码中对其进 行处理。
清单 2 显示了与清单 1 SOAP 示例相同的应用程序数据,但其中包括 WS-Addressing 信息。尽管原始的 SOAP 消息只能用于 HTTP 传输(因为 HTTP 提供了双向的连接,使得响应可以立即发送回客户端),但清单 2 中的版本可以用于其他协议,因为 SOAP 请求消息中直接包括了响应元数据。在对清单 2 的消息进行处理的过程中,甚至可以进行存储转发操作,因为这些元数据同时提供了请求目标和响应目标信息。
清单 2. 使用 WS-Addressing 的 SOAP 示例
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:wsa="http://www.w3.org/2005/08/addressing">
<soapenv:Header>
<wsa:To>http://localhost:8800/axis2/services/SeisAxis2XBean</wsa:To>
<wsa:ReplyTo>
<wsa:Address>http://www.w3.org/2005/08/addressing/anonymous</wsa:Address>
</wsa:ReplyTo>
<wsa:MessageID>urn:uuid:97AE2B17231A8584D811537402403691</wsa:MessageID>
</soapenv:Header>
<soapenv:Body>
<matchQuakes xmlns="http://seismic.sosnoski.com/types">
<min-date>2000-03-28T13:13:08.953Z</min-date>
<max-date>2001-03-11T02:26:54.283Z</max-date>
<min-long>-81.532234</min-long>
<max-long>65.25895</max-long>
<min-lat>-14.234512</min-lat>
<max-lat>57.174187</max-lat>
</matchQuakes>
</soapenv:Body>
</soapenv:Envelope>
|
因 为 SOAP Header 的关键思想是允许在消息中添加任何元数据,所以 SOAP 框架必须能够接受某些扩展需要添加的任何内容。一般来说,处理任意的 XML 的最简单方法是使用某种形式的文档模型。这正是文档模型的任务所在,即不对该 XML 的形式进行任何假设,如实地表示 XML。
但 是对于处理在不同应用程序之间进行数据交换时所使用的 XML 来说,文档模型并不是一种非常高效的方法。通常,应用程序数据具有预定义的结构,并且大多数开发人员更倾向于以数据对象而不是原始的 XML 的形式对这些数据进行处理。数据对象和 XML 之间的转换任务由数据绑定负责完成。与使用文档模型相比,数据绑定为开发人员带来了更大的方便,同时,它在性能和内存使用方面的效率也更高。
所 以,大多数应用程序希望使用数据绑定来处理 SOAP 消息的应用程序负载,但是对于处理 Header 中的元数据,使用文档模型的方法更合适。理想的方法是在 SOAP 框架中同时使用这两种技术,但普通的文档模型不支持这种用法。它们希望处理整个文档,或者至少是文档中一个完整的子树。它们无法处理文档中所选的部分,但 这是处理 SOAP 的最合适的方式。
除 了 AXIOM 之外,Axis2 还对 Axis 进行了另一个改进。原始的 Axis 使用标准的推式 (SAX) 解析器进行 XML 处理,而 Axis2 使用拉式 (StAX) 解析器。在使用推方式的情况下,由解析器来控制解析操作,需要向解析器提供要解析的文档和处理程序。然后,在对输入文档进行处理的时候,它使用代码中的处 理程序作为回调。处理程序代码可以使用这些回调中传递的信息,但是不能影响解析过程(除了引发一个异常)。相反,在使用拉方式的情况下,解析器实际上是一 个高效的迭代器,可以根据需要对文档中的不同部分进行遍历。
推方式和拉方式分别具有各自的用途,但是对于处理包含逻辑上独立的不同部分的 XML(如 SOAP),使用拉方式更有优势。。使用拉式解析器,处理文档某一部分的代码仅解析它所需的部分,然后由解析器进行接下来的文档处理。
AXIOM 构建于 StAX 拉式解析器接口的基础之上。AXIOM 提供了一种可以按需扩展的虚拟文档模型,仅构建客户端应用程序所请求的树结构文档模型表示。这种虚拟的文档模型工作于 XML 文档的元素级。当解析器报告元素开始标记时创建元素表示,但是该元素的初始形式仅仅只是一个壳,其中保存了对解析器的引用。如果应用程序需要获取元素内容 的细节信息,它只需要通过调用接口(如 org.apache.axiom.om.OMContainer.getChildren() 方法)的方法,就可以请求相应的信息。然后,在对这个方法调用的响应中,解析器将构建该元素的子内容。
因 为解析器按照文档顺序(与 XML 文档文本中项目的出现顺序相同)传递数据,所以 AXIOM 所实现的按需构造需要某种灵活的处理方法。例如,通常有多个元素处于不完整的(正在构建的过程中)状态,但是这些元素都必须位于继承结构的一条直线中。如 果从根元素在顶端的标准 XML 树关系图的角度来看,不完整的元素将始终位于该树右侧的直线中。随着应用程序请求更多的数据,该树逐渐向右扩充,并且首先完成顶端的元素。
| |
就 所提供的 API 而言,所有的 XML 文档模型都具有很多相同之处(这并不奇怪,因为它们都需要处理相同的基础数据),但是与其他的文档模型相比,它们又各有千秋。原始的 W3C 文档对象模型 (DOM) 设计提供跨语言和跨平台的兼容性,所以构建于各种接口之上,并且在其自身的版本中避免使用 Java 特定的集合。JDOM 使用了具体类而不是接口,并且在这种 API 中集成了标准的 Java 集合类,许多 Java 开发人员认为它比 DOM 更友好。dom4j 将类似 DOM 的接口和 Java 集合类组合到一起,这种非常灵活的 API 提供了很多强大的功能,但却在一定的程度上增加了复杂性。
AXIOM 与其他文档模型有许多相似之处。它还具有一些与其按需构建的处理过程相关的显著特征,以及支持其用于 Web 服务的专门特性。
从整体上看,AXIOM 的 API 可能最接近于 DOM,但是它又具有自己的特点。例如,访问方法以使用 java.util.Iterator 实例为基础对不同的部分(如通过 org.apache.axiom.om.OMContainer.getChildren() 以及相关方法所返回的部分)进行访问,而没有使用任何形式的列表。没有将不同的部分索引为列表,导航使用 org.apache.axiom.om.OMNode.getNextOMSibling() 和 org.apache.axiom.om.OMNode.getPreviousOMSibling() 方法,以便按顺序遍历文档树中同一个级别的节点(在这方面,它类似于 DOM)。这种访问和导航方法的结构与按需构建树的工作方式非常吻合,因为这意味着 AXIOM 可以允许您移动到开始元素的第一个子项,而无需首先处理所有的 子元素。
与 DOM 和 dom4j 一样,AXIOM 使用接口定义了用于访问和操作树表示的 API。AXIOM 分发版中包括这些接口的几种不同的专门实现。其中一种实现(在 org.apache.axiom.om.impl.dom 包中)是双重功能的,使用相同的实现类同时支持 AXIOM 和 DOM 接口。因为需要使用数据的 DOM 视图的 Web 服务外接程序的数目较多,所以这种实现可能很有价值。有关更一般的用法,org.apache.axiom.om.impl.llom 包提供了一种基于对象链表的实现(包名中的“ll”表示链表 (linked list))。还对基本的 org.apache.axiom.om 接口和 org.apache.axiom.soap 包树中的实现进行了扩展,后者专门用于处理 SOAP 消息。
为 了简要地了解实际应用中的 AXIOM API,我们将对一些示例进行研究,这些示例来自于对 AXIOM 与其他的文档模型进行性能测试对比的代码。清单 3 中提供了第一个示例,这个示例基于为输入文档构建 AXIOM 表示的代码。与使用 DOM 和 dom4j 一样,在使用 AXIOM 进行任何工作之前,您需要获得一个构建模型组件对象的工厂。通过使用 org.apache.axiom.org.OMFactory 接口的 org.apache.axiom.om.impl.llom.factory.OMLinkedListImplFactory 实现,清单 3 中的代码选择了 AXIOM 接口的基本链表实现。这个工厂接口包括用于从各种来源直接构建文档的方法、用于创建 XML 文档表示的不同部分的方法。清单 3 使用了相应的方法从输入流构建文档。build() 方法返回的对象实际上是 org.apache.axiom.om.OMDocument 的实例,尽管在这段代码中没有指明。
import org.apache.axiom.om.*;
import org.apache.axiom.om.impl.builder.StAXOMBuilder;
import org.apache.axiom.om.impl.llom.factory.OMLinkedListImplFactory;
...
private XMLInputFactory m_parserFactory = XMLInputFactory.newInstance();
private OMFactory m_factory = new OMLinkedListImplFactory();
...
protected Object build(InputStream in) {
Object doc = null;
try {
XMLStreamReader reader = m_parserFactory.createXMLStreamReader(in);
StAXOMBuilder builder = new StAXOMBuilder(m_axiomFactory, reader);
doc = builder.getDocument();
} catch (Exception ex) {
ex.printStackTrace(System.out);
System.exit(0);
}
return doc;
}
|
清单 3 使用了 org.apache.axiom.om.impl.builder.StAXOMBuilder 类通过解析输入流来构建文档表示。这段代码在返回之前仅创建了 StAX 解析器实例和基本文档结构,并使得解析器定位到文档的根元素,如果需要,稍后再构建文档表示的其他部分。并不一定 必须使用 StAX 解析器来构建 AXIOM。事实上,org.apache.axiom.om.impl.builder.SAXOMBuilder 是基于 SAX 推式解析器的构建程序的部分实现。但如果您使用其他方法来构建它,那么就无法利用按需构造所带来的优点。
清单 4 提供了用于遍历文档表示中的元素并累计摘要信息(元素的计数,属性值文本的计数和总长度,以及文本内容的计数和总长度)的代码。底部的 walk() 方法接受需要进行汇总的文档以及摘要数据结构作为参数,而顶部的 walkElement() 方法则处理一个元素(递归地调用自己以便对子元素进行处理)。
/**
* Walk subtree for element. This recursively walks through the document
* nodes under an element, accumulating summary information.
*
* @param element element to be walked
* @param summary document summary information
*/
protected void walkElement(OMElement element, DocumentSummary summary) {
// include attribute values in summary
for (Iterator iter = element.getAllAttributes(); iter.hasNext();) {
OMAttribute attr = (OMAttribute)iter.next();
summary.addAttribute(attr.getAttributeValue().length());
}
// loop through children
for (Iterator iter = element.getChildren(); iter.hasNext();) {
// handle child by type
OMNode child = (OMNode)iter.next();
int type = child.getType();
if (type == OMNode.TEXT_NODE) {
summary.addContent(((OMText)child).getText().length());
} else if (type == OMNode.ELEMENT_NODE) {
summary.addElements(1);
walkElement((OMElement)child, summary);
}
}
}
/**
* Walk and summarize document. This method walks through the nodes
* of the document, accumulating summary information.
*
* @param doc document representation to be walked
* @param summary output document summary information
*/
protected void walk(Object doc, DocumentSummary summary) {
summary.addElements(1);
walkElement(((OMDocument)doc).getOMDocumentElement(), summary);
}
|
最后,清单 5 给出了用于将该文档表示转换为输出流的代码。作为 OMNode 接口的一部分,AXIOM 定义了许多输出方法,包括针对各种不同的目标(如输出流、普通字符写入程序、或 StAX 流写入程序),带和不带格式信息,带和不带在写入之后访问文档表示的功能(如果尚未构建,这需要构建完整的表示)。通过从元素中获得 StAX 解析器,OMElement 接口定义了另一种访问文档信息的方法。这种使用解析器从文档表示中提取 XML 的能力提供了很好的对称性,当按需构建 AXIOM 表示时,这种方式非常合适(因为可以直接返回用于构建该表示的解析器)。
/**
* Output a document as XML text.
*
* @param doc document representation to be output
* @param out XML document output stream
*/
protected void output(Object doc, OutputStream out) {
try {
((OMDocument)doc).serializeAndConsume(out);
} catch (Exception ex) {
ex.printStackTrace(System.err);
System.exit(0);
}
}
|
AXIOM 为修改现有的文档部分提供了一些基本的方法(如 OMElement.setText() 可用于将元素的内容设置为一个文本值)。如果您正从头开始写入文档,那么需要直接创建组件的新实例。因为 AXIOM API 是基于接口的,所以它使用各种工厂来创建不同部分的具体实现。
有关 AXIOM API 的更详细信息,请参见参考资料部分提供的 AXIOM 教程和 JavaDoc 链接。
AXIOM 的最有趣的特性之一是,它对 SOAP 附件最新版本中所使用的 W3C XOP 和 MTOM 标准提供了内置的支持。这两种标准协同工作,其中 XOP(XML 二进制优化打包,XML-binary Optimized Packaging)提供了一种方式,使得 XML 文档在逻辑上可以包含任意二进制数据的大对象,而 MTOM(SOAP 消息传输优化机制,SOAP Message Transmission Optimization Mechanism)则将 XOP 技术应用于 SOAP 消息。XOP 和 MTOM 都是新一代 Web 服务框架的关键特性,因为它们最终提供了可互操作的附件支持以及解决本领域中当前问题的能力。
XOP 使用 Base64 编码的字符数据内容。通过对原始数据中的每六位使用一个 ASCII 字符来表示,Base64 编码可以将任意的数据值转换为可打印的 ASCII 字符。因为二进制数据通常不能嵌入到 XML 中(XML 只能处理字符,不能处理原始的字节,甚至有一些字符编码也不允许出现在 XML 中),Base64 编码非常适合于在 XML 消息中嵌入二进制数据。
XOP 使用 XOP 命名空间中特殊的“Include”元素来替换 Base64 文本。Include 元素给出了标识单独实体(在该 XML 文档之外)的 URI,该实体是希望包括在 XML 文档中的实际数据。通常,这个 URI 将在与 XML 文档相同的传输中标识一个单独的块(尽管可以不这样做,但这样提供的潜在优势可通过中间层或存储文档来交换文档)。使用对原始数据的引用来替换 Base64 文本,可以在一定程度上减小文档大小(对于普通字符编码,最多可以减少百分之二十五的大小),并实现更快的处理速度,而无需承担对 Base64 数据进行编码和解码所带来的开销。
MTOM 构建于 XOP 之上,首先定义了一个抽象的模型,表示如何将 XOP 用于 SOAP 消息,然后对该模型进行特殊化使其专门用于 MIME Multipart/Related 打包,最后将其应用于 HTTP 传输。通过这些处理,它提供了一种标准的方式,通过广泛使用的 HTTP 传输将 XOP 应用于 SOAP 消息。
AXIOM 通过 org.apache.AXIOM.om.OMText 接口以及该接口的实现来支持 XOP/MTOM。OMText 定义了相应的方法以支持代表二进制数据的文本项目(以 javax.activation.DataHandler 的形式表示,这是 Java Web 服务框架中用于附件支持的广泛使用的 Java Activation API 的一部分),以及一个“优化”标志用来表示是否可以使用 XOP 对该项目进行处理。org.apache.AXIOM.om.impl.llom.OMTextImpl 实现添加了一个与 MTOM 兼容的内容 ID,在创建或自动生成类的实例时,如果尚未设置,可以对其进行相应的设置。
清单 6 通过一个示例介绍了如何在 AXIOM 中使用 XOP/MTOM 来构建消息。这段代码取自一个性能测试示例,该示例使用 Java 序列化将结果数据结构转换为一个字节数组,然后返回这个数组作为附件。
public OMElement matchQuakes(OMElement req) {
Query query = new Query();
Iterator iter = req.getChildElements();
try {
...
// retrieve the matching quakes
Response response = QuakeBase.getInstance().handleQuery(query);
// serialize response to byte array
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(response);
byte[]byts = bos.toByteArray();
// generate response structure with reference to data
ByteArrayDataSource ds = new ByteArrayDataSource(byts);
OMFactory fac = OMAbstractFactory.getOMFactory();
OMNamespace ns =
fac.createOMNamespace("http://seismic.sosnoski.com/types", "qk");
OMElement resp = fac.createOMElement("response", ns);
OMText data = fac.createOMText(new DataHandler(ds), true);
resp.addChild(data);
return resp;
} catch (ParseException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
|
尽管清单 6 中的代码生成了可以使用 XOP/MTOM 发送的响应,但在 Axis2 的当前版本中,在缺省情况下 XOP/MTOM 支持处于禁用状态。要启用它,需要在 Axis2 axis2.xml 文件或服务的 services.xml 文件中包括参数 <parameter name="enableMTOM">true</parameter> 。作为即将介绍的性能比较中的一部分,我们将提供这个示例的完整代码,但现在我们将以一个实际使用 XOP/MTOM 的示例作为结束。
清单 7 显示了由清单 6 的服务所生成的响应消息的结构,启用或没有启用 XOP/MTOM(在第一个示例中不包含 MIME Header 和实际的二进制附件,而在第二个示例中删除了大部分的数据)。
<?xml version='1.0' encoding='UTF-8'?>
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Header />
<soapenv:Body>
<qk:response xmlns:qk="http://seismic.sosnoski.com/types"
xmlns:tns="http://ws.apache.org/axis2">
<xop:Include href="cid:1.urn:uuid:[email protected]"
xmlns:xop="http://www.w3.org/2004/08/xop/include" />
</qk:response>
</soapenv:Body>
</soapenv:Envelope>
[actual binary data follows as separate MIME part with referenced content id]
<?xml version='1.0' encoding='UTF-8'?>
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Header />
<soapenv:Body>
<qk:response xmlns:qk="http://seismic.sosnoski.com/types"
xmlns:tns="http://ws.apache.org/axis2">rO0ABXNyACdjb20uc29zb...</qk:response>
</soapenv:Body>
</soapenv:Envelope>
|
大 多数 Web 服务开发人员需要以 Java 对象而不是 XML 文档(或者甚至文档模型,如 AXIOM)的形式使用数据。上一代框架,如 Axis 和 JAX-RPC,实现了自己的数据绑定,以便在 XML 和 Java 对象之间进行转换,但这是一种非常有限的解决方案。Web 服务框架中的数据绑定实现通常无法与专门的数据绑定框架相比,所以希望更好地控制 XML 处理过程的用户不得不将该框架与低效的转换代码结合在一起。因为这些问题,Axis2 重新进行了设计,以支持使用各种数据绑定框架作为数据绑定“插件”。
这种数据绑定支持使用对 Axis2 中包含的 WSDL2Java 工具的自定义扩展。该工具基于 WSDL 服务描述为客户端或服务器端消息接收者以存根的形式生成 Axis2 连接代码。客户端存根可作为代理进行服务的调用,它定义了实现服务操作的方法调用。服务器端消息接收者可作为客户端的代理,调用实际的用户定义的服务方 法。当在 WSDL2Java 命令行中请求数据绑定时,该工具将调用指定的数据绑定框架扩展,在存根或消息接收者中生成在 OMElement 和 Java 对象之间进行转换的代码。在使用存根的情况下,在方法调用中传递 Java 对象(或原始值),并将经过转换的 XML 作为请求发送到服务器。然后将返回的 XML 重新转换为 Java 对象,再将后者作为方法调用的结果返回。服务器端的消息接收者以相反的方式进行转换。
在入站或分解端(将接收到的 XML 转换为 Java 对象),处理过程比较简单。需要转换为 Java 对象的 XML 文档负载可以通过 OMElement 的形式获得,并且数据绑定框架只需要处理该元素中的数据。OMElement 以 StAX javax.xml.stream.XMLStreamReader 的形式提供了对元素数据的访问,当前大多数的数据绑定框架可以直接使用 javax.xml.stream.XMLStreamReader 作为输入。
出 站或封送端(将 Java 对象转换为传输的 XML)的处理稍微复杂一些。AXIOM 的关键思想是,除非在绝对必要的情况下,否则将避免构建完整的 XML 数据表示。要在封送时支持这个原则,必须有一种方式使得可以仅在需要的时候调用数据绑定框架。AXIOM 通过使用 org.apache.AXIOM.om.OMDataSource 作为数据绑定转换的包装来处理这个问题。OMDataSource 定义了相应的方法,以便使用 AXIOM 所支持的任何方法写出包装的内容(到 java.io.OutputStream 、java.io.Writer 或 StAX javax.xml.stream.XMLStreamWriter ),以及为包装的内容返回解析器实例的另一种方法。OMElement 实现可以使用 OMDataSource 的实例按需提供数据,而 OMFactory 接口提供了创建这种类型的元素的方法。
| |
我 们将对性能进行简要的分析,以此总结关于 AXIOM 的内容。在撰写这篇文章的时候,AXIOM 1.1 已经发布,这意味着本文中描述的接口应该比较稳定。另一方面,随着实际实现代码的修改,性能总在发生着变化。与其他的文档模型相比,我们并不期望 AXIOM 在性能上有什么重大的改进,但是其中的一些具体细节可能有些差异。
为了将 AXIOM 与其他的文档模型进行比较,我们对以前的文档模型研究(请参见参考资料部分)中的代码进行了更新,添加了 AXIOM 和另一种新的文档模型 (XOM),对代码进行转换使其使用 StAX 解析器标准,而不是较早的 SAX 标准,并切换到使用 Java 5 中引入的改进的 System.nanoTime() 计时方法。性能测试代码首先将测试中使用到的文档读入到内存中,然后对文档进行一系列的操作。首先,使用解析器构建文档表示的某个数量的副本,并保存每个 结果文档对象。接下来,对每个文档对象进行遍历,这意味着代码将扫描整个文档表示(包括所有的属性、值和文本内容)。最后,将所有的文档对象写入到输出 流。对每项单独的操作,记录其时间,并在测试结束后计算其平均值。
因为 AXIOM(尤其是用于 Axis2 中时)主要关注于处理 SOAP 消息,所以我们使用了三个不同的 SOAP 消息测试用例来检查性能。第一个测试用例是一个 Web 服务性能测试的示例响应,该服务提供了某个时间段和经/纬度范围内的地震信息(“quakes”文档,18 KB)。这个文档包含许多重复的元素和一些嵌套的情况,并大量使用了属性。第二个测试用例是来自 Microsoft WCF 可互操作性测试的一个较大的示例,由单个重复的结构组成,并且在取值上有一些细微的变化(“persons”文档,202 KB)。这个文档具有带文本内容的子元素,但是没有使用属性。第三个测试用例是由 30 个较小的 SOAP 消息文档组成的集合,这些消息来自于一些较早的可互操作性测试(总大小为 19 KB)。从测试文档中删除了所有用来进行格式化的空格,以建立真正的生产服务(通常关闭格式化,以减少消息的大小)交换使用的 XML 文档表示。
下 面的图表显示了对每个文档进行 50 次处理所需的平均时间。测试环境为 Compaq 笔记本系统,1600 MHz ML-30 AMD Turion 处理器和 1.5 GB RAM,在 Mandriva 2006 Linux 上运行 Sun 的 1.5.0_07-b03 JVM。我们测试了 AXIOM 1.0、dom4j 1.6.1、JDOM 1.0、Xerces2 2.7.0 和 Nux 1.6 分发版中的 XOM。为 dom4j、JDOM 和 Xerces2 使用 StAX 解析器的自定义构建程序,而对 XOM 则使用 Nux StAX 解析器构建程序。所有的测试都使用了 Woodstox StAX 解析器 2.9.3。
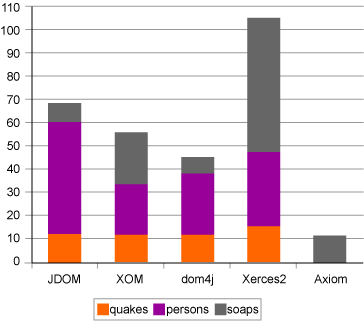
图 1 显示了测试序列中前两个步骤所需的平均时间的总和,即使用解析器构建文档,并遍历文档表示以检查其中的内容。如果单独研究第一个步骤(这里没有显示时 间),AXIOM 要比其他的文档模型好得多,至少对于前面两个文档来说是这样的。然而,这仅表示 AXIOM 正如预料的那样工作,直到需要时才真正构建完整的文档。我们希望使用在内存中构建完整的表示所需的时间来进行公平的比较,这正是图表中将这两个时间加在一 起的原因。

如图 1 所示,从整体上看,除了 Xerces2 之外,AXIOM 比所测试的任何其他文档模型都要慢一些。
在 处理较小的文档组成的集合(“soaps”)时,有一些文档模型出现了性能问题。Xerces2 在这种情况下最糟糕,但是 AXIOM 也出现了较大的开销,这可能是该图表中反映出来的最麻烦的问题。在许多 Web 服务中,较小的消息是很常见的,而 AXIOM 应该可以高效地处理这些消息。因为 AXIOM 设计为按需展开文档树,所以对于两个较大的文档,在时间上并不存在很大的问题,至少与其他的文档模型非常接近。

图 2 显示了使用每种模型将文档写入到输出流中的平均时间。这里,Xerces2 的性能要高出一大截(但这并不足以弥补它在构建步骤中糟糕的性能,这两张图表的比例并不一样),而 AXIOM 最差。同样的,AXIOM 对于较小的文档尤其糟糕。

最 后,图 3 显示了每种框架在表示文档时所使用的内存大小。dom4j 又是最好的,而 AXIOM 则比其他的差了一大截。AXIOM 在内存使用方面的糟糕性能,在一定程度上是由于在所构建的文档中引用了解析器,以便在使用文档实例的过程中保存解析器实例。这也是 AXIOM 在处理较小文档时尤其糟糕的原因中的一部分。然而,AXIOM 作为文档组件所使用的对象也比其他文档模型的对象大的多,这种差别可能正是 AXIOM 对两个较大的测试文档使用过多内存空间的原因(其中,固定大小的解析器开销和其他数据结构只占总的内存使用中的一小部分)。
如果将前两个图表的时间累加起来,dom4j 的总体性能最好,而 Xerces2 的性能最差(AXIOM 比它稍微好一点)。在内存使用方面,dom4j 又是最好的,而 AXIOM 在这方面是毫无争议的失败者。是不是为 AXIOM 感到遗憾呢?
如果始终构建完整的树表示,那才是应该 遗憾的,但请记住,AXIOM 的关键思想是在通常情况下并不需要完整的表示。图 4 显示了在 AXIOM 中初始文档构建的时间,并与其他文档模型构建文档表示所需的时间进行了比较。在这个测试中,AXIOM 比其他的文档模型快得多(对于两个较大的文档,甚至快得无法记录时间)。同样的比较也可以应用于内存方面。最后的结论是,如果只需要处理文档模型中的某些 部分(如按文档顺序的“第一”部分),AXIOM 提供了优秀的性能。
| |
本 文深入研究了 Axis2 中的 AXIOM 文档对象模型。AXIOM 中包含了一些有趣的思想,尤其是构建完整表示的按需构建方法。当您需要完整地展开表示时,它无法与其他的 Java 文档模型相比。尤其是对于较小的文档,其性能比较糟糕,但是它为 Web 服务处理所提供的灵活性完全可以抵销这些问题。
现在,您已经了解了 Axis2 如何使用 AXIOM 处理 SOAP 消息表示,包括如何与数据绑定框架相互传递 XML。下一篇文章将从用户的角度来研究 Axis2 如何支持不同的数据绑定框架,包括使用三种框架的代码示例。