mahout源码KMeansDriver分析之五KmeansDriver(完结篇)
好吧,我上篇博客的仿造CIReducer的代码的确是有误的,错在哪?map输出的中心点是两个不错,但是其key是不一样的,所以要送到不同的reduce函数中(注意这里是函数,而非reducer,如果是同一个key则要送到同一个reduce中),所以不是一个for循环就搞定的,应该要key的个数个for循环才行。那就是说reducer中的reduce函数一次只能接受一个中心点了(针对一直使用的数据来说),好吧但是在reduce函数中只是有一个赋值语句呀,并没有更改这个中心点的center属性呀所以只会进入 if(first==null)中而已(如果有多个map的话可能会进入else中)。那么是在哪里更改center属性值的呢?往下看,
List<Cluster> models = new ArrayList<Cluster>();
models.add(first.getValue());
classifier = new ClusterClassifier(models, policy);
classifier.close();看到close-->AbstractClusteringPolicy.close()-->AbstractCluster.computeParameters():
public void computeParameters() {
if (getS0() == 0) {
return;
}
setNumObservations((long) getS0());
setTotalObservations(getTotalObservations() + getNumObservations());
setCenter(getS1().divide(getS0()));
// compute the component stds
if (getS0() > 1) {
setRadius(getS2().times(getS0()).minus(getS1().times(getS1())).assign(new SquareRootFunction()).divide(getS0()));
}
setS0(0);
setS1(center.like());
setS2(center.like());
}好吧,这里有改center属性的方法了。
怎么知道以上猜测全部正确呢?
编写下面的类进行测试(这里主要是mahout的源码,只是里面加入了相关信息的显示而已),或者直接下载 kmeans.jarjar包也行。
Driver:
package mahout.fansy.kmeans1;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
//import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.mahout.clustering.Cluster;
//import org.apache.mahout.clustering.classify.ClusterClassifier;
import org.apache.mahout.clustering.iterator.ClusterIterator;
import org.apache.mahout.clustering.iterator.ClusterWritable;
//import org.apache.mahout.clustering.iterator.ClusteringPolicy;
public class CIDriver {
/**
* @param args
* @throws InterruptedException
* @throws IOException
* @throws ClassNotFoundException
*/
public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {
if(args.length!=3){
System.err.println("Usage:<inPath> <priorPath> <outPath>");
System.exit(-1);
}
Path inPath=new Path(args[0]);
Path priorPath=new Path(args[1]);
Path outPath=new Path(args[2]);
runMR(inPath,priorPath,outPath);
}
public static void runMR(Path inPath, Path priorPath, Path outPath)
throws IOException, InterruptedException, ClassNotFoundException {
// ClusteringPolicy policy = ClusterClassifier.readPolicy(priorPath);
Path clustersOut = null;
Configuration conf=new Configuration();
conf.set("mapred.job.tracker", "hadoop:9001");
conf.set(ClusterIterator.PRIOR_PATH_KEY, priorPath.toString());
String jobName = "Cluster Iterator running iteration " + 1 + " over priorPath: " + priorPath;
System.out.println(jobName);
Job job = new Job(conf, jobName);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(ClusterWritable.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(ClusterWritable.class);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setMapperClass(CIMapper.class);
job.setReducerClass(CIReducer.class);
FileInputFormat.addInputPath(job, inPath);
clustersOut = new Path(outPath, Cluster.CLUSTERS_DIR + 1);
priorPath = clustersOut;
FileOutputFormat.setOutputPath(job, clustersOut);
job.setJarByClass(ClusterIterator.class);
if (!job.waitForCompletion(true)) {
throw new InterruptedException("Cluster Iteration " + 1 + " failed processing " + priorPath);
}
/*
ClusterClassifier.writePolicy(policy, clustersOut);
FileSystem fs = FileSystem.get(outPath.toUri(), conf);
iteration++;
if (isConverged(clustersOut, conf, fs)) {
break;
}
*/
/*
Path finalClustersIn = new Path(outPath, Cluster.CLUSTERS_DIR + (iteration - 1) + Cluster.FINAL_ITERATION_SUFFIX);
FileSystem.get(clustersOut.toUri(), conf).rename(clustersOut, finalClustersIn);
*/
}
}
Mapper:
package mahout.fansy.kmeans1;
import java.io.IOException;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.mahout.clustering.AbstractCluster;
import org.apache.mahout.clustering.Cluster;
import org.apache.mahout.clustering.GetAbstractClusterS_Fan;
import org.apache.mahout.clustering.classify.ClusterClassifier;
import org.apache.mahout.clustering.iterator.ClusterIterator;
import org.apache.mahout.clustering.iterator.ClusterWritable;
import org.apache.mahout.clustering.iterator.ClusteringPolicy;
import org.apache.mahout.clustering.iterator.DistanceMeasureCluster;
import org.apache.mahout.math.Vector;
import org.apache.mahout.math.Vector.Element;
import org.apache.mahout.math.VectorWritable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class CIMapper extends Mapper<WritableComparable<?>,VectorWritable,IntWritable,ClusterWritable> {
private ClusterClassifier classifier;
private ClusteringPolicy policy;
private static final Logger log=LoggerFactory.getLogger(CIMapper.class);
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
String priorClustersPath = conf.get(ClusterIterator.PRIOR_PATH_KEY);
classifier = new ClusterClassifier();
classifier.readFromSeqFiles(conf, new Path(priorClustersPath));
policy = classifier.getPolicy();
policy.update(classifier);
// 查看setup函数的具体操作
log.info("setup : classifier.getModels().get(0).toString():"+classifier.getModels().get(0).toString());
log.info("setup : classifier.getModels().get(1).toString():"+classifier.getModels().get(1).toString());
super.setup(context);
}
@Override
protected void map(WritableComparable<?> key, VectorWritable value, Context context) throws IOException,
InterruptedException {
Vector probabilities = classifier.classify(value.get());
Vector selections = policy.select(probabilities);
for (Iterator<Element> it = selections.iterateNonZero(); it.hasNext();) {
Element el = it.next();
classifier.train(el.index(), value.get(), el.get());
}
/**
* 在对应的包中编写一个类把原来protected的方法变为public
*/
GetAbstractClusterS_Fan gs0= new GetAbstractClusterS_Fan( (AbstractCluster)(DistanceMeasureCluster) classifier.getModels().get(0));
GetAbstractClusterS_Fan gs1= new GetAbstractClusterS_Fan( (AbstractCluster)(DistanceMeasureCluster) classifier.getModels().get(1));
log.info("map : classifier.getModels().get(0).toString():"+classifier.getModels().get(0).toString()+",s0:"+gs0.getS0()+",s1:"+gs0.getS1().asFormatString());
log.info("map : classifier.getModels().get(1).toString():"+classifier.getModels().get(1).toString()+","+gs1.getS0()+",s1:"+gs1.getS1().asFormatString());
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
List<Cluster> clusters = classifier.getModels();
ClusterWritable cw = new ClusterWritable();
for (int index = 0; index < clusters.size(); index++) {
cw.setValue(clusters.get(index));
log.info("cleanup : index:"+index+", clusterwritable : "+cw.getValue().toString());
context.write(new IntWritable(index), cw);
}
super.cleanup(context);
}
}
Reducer:
package mahout.fansy.kmeans1;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.mahout.clustering.Cluster;
import org.apache.mahout.clustering.classify.ClusterClassifier;
import org.apache.mahout.clustering.iterator.ClusterIterator;
import org.apache.mahout.clustering.iterator.ClusterWritable;
import org.apache.mahout.clustering.iterator.ClusteringPolicy;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class CIReducer extends Reducer<IntWritable,ClusterWritable,IntWritable,ClusterWritable> {
private ClusterClassifier classifier;
private ClusteringPolicy policy;
private static final Logger log=LoggerFactory.getLogger(CIReducer.class);
@Override
protected void reduce(IntWritable key, Iterable<ClusterWritable> values, Context context) throws IOException,
InterruptedException {
Iterator<ClusterWritable> iter = values.iterator();
ClusterWritable first = null;
log.info("**********************before while *****************");
while (iter.hasNext()) {
ClusterWritable cw = iter.next();
if (first == null) {
first = cw;
log.info("reduce : first ==null:first:"+first.getValue().toString());
} else {
first.getValue().observe(cw.getValue());
log.info("reduce : first !=null:first:"+first.getValue().toString());
}
}
log.info("**********************after while *****************");
List<Cluster> models = new ArrayList<Cluster>();
models.add(first.getValue());
classifier = new ClusterClassifier(models, policy);
classifier.close();
log.info("last ------------------reduce : first !=null:first:"+first.getValue().toString());
context.write(key, first);
}
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
String priorClustersPath = conf.get(ClusterIterator.PRIOR_PATH_KEY);
classifier = new ClusterClassifier();
classifier.readFromSeqFiles(conf, new Path(priorClustersPath));
policy = classifier.getPolicy();
policy.update(classifier);
log.info("r setup : classifier.getModels().get(0).toString():"+classifier.getModels().get(0).toString());
log.info("r setup : classifier.getModels().get(1).toString():"+classifier.getModels().get(1).toString());
super.setup(context);
}
}
因为在Mapper中要访问KCluster中的S0和S1属性,所以在org.apache.mahout.clustering包中编写了一个类,用于把AbstractCluster类中的getS0和getS1()方法放出来。如下:
package org.apache.mahout.clustering;
import org.apache.mahout.math.Vector;
public class GetAbstractClusterS_Fan {
private AbstractCluster aCluster;
public GetAbstractClusterS_Fan(){
}
public GetAbstractClusterS_Fan(AbstractCluster aCluster_){
this.aCluster=aCluster_;
}
/**
* get s0 value
* @return
*/
public double getS0(){
return this.aCluster.getS0();
}
/**
* get s1 vector value
* @return
*/
public Vector getS1(){
return this.aCluster.getS1();
}
/**
* get s2 vector value
* @return
*/
public Vector getS2(){
return this.aCluster.getS2();
}
}
然后运行就可以在web页面查看log信息了,如下:mapper:
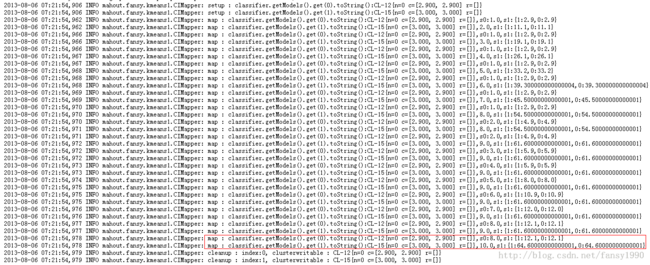
如上红色框中可以看到map输出的中心点的center属性没有改变,但是它的s0和s1属性都是改变的;下面是reducer:

红色框中即为reduce的输出了,可以看出新的中心点的center值为s1除以s0;和上面分析说最后close方法运行设置center值的方法是一样的。
分享,快乐,成长
转载请注明出处:http://blog.csdn.net/fansy1990