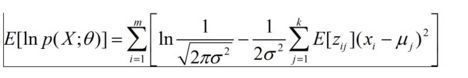|
所谓EM算法,指的是就是Expect-Maximum算法,是一种非常有用的算法。假设这么一个问题,我们有一堆样本集合X,我们已知该样本总体的分布类型(比如是高斯分布),但是我们不知道这个分布的参数具体是多少,我们希望有方法能够根据这些观测到的样本集合来估计出这个分布的参数。怎么办呢?于是就有了极大似然估计,该方法思路很简单,计算出这些样本出现的分布概率公式,该公式肯定包含了这些参数作为公式的因子。我们的目标是使得该样本出现的概率最大,那么剩下的问题就是一个数学问题了,选择合适的参数值使得这个公式的值最大,比如求导等等。极大似然估计的的思路很直接,选择一个目标函数,使该目标函数最大。 如果我们在对上述问题再加一点难度,除了分布参数我们不知道,另外还有一些隐藏的变量我们也不知道,或者说观测到得数据不完整,在这种情况下,包含了隐藏变量的目标函数往往没有解析解,因此无法估算出这些参数变量。那我们又该怎么估计出这些参数和这些缺失的隐藏变量呢?解决的方法就是EM算法。关于EM算法,52npl上有一篇博客做了比较深刻的说明,请参阅。这里对其说明进行一些评注,便于大家理解。 EM算法的目标是找出有隐性变量的概率模型的最大可能性解,它分为2个步骤,E-step和M-step,E-step根据最初假设的模型参数值或者上一步的模型参数计算出隐性变量的后验概率,其实就是隐性变量的期望,M-step根据这个E-step的后验概率重新计算出模型参数,然后再重复这两个步骤,直至目标函数收敛。 观测到的变量组成的向量我们表示成X,所有隐性变量组成的向量为Z,模型的参数表示成(一个或多个参数)。在分类问题中,Z就表示的是可能的潜在分类,X就是需要分类的数据,我们得目标是找出模型的参数和隐性变量来使得X出现的概率最大,也就是 由于很多模型的概率都带有指数,所以在 假设
公式(1) 最后一步是基于琴生不等式,所谓琴生不等式
需要注意的是,中国大陆数学界某些机构关于函数凹凸性定义和国外的定义是相反的。Convex Function在某些国内的数学书中指凹函数。Concave Function指凸函数。但在中国大陆涉及经济学的很多书中,凹凸性的提法和国外的提法是一致的,也就是和数学教材是反的。举个例子,同济大学高等数学教材对函数的凹凸性定义与本文相反,本条目的凹凸性是指其上方图是凹集或凸集,而同济大学高等数学教材则是指其下方图是凹集或凸集,两者定义正好相反。 在本文中,ln是一个凹函数。 根据公式(1),我们看到了 第一步:E-step 其目的是计算出 根据琴声不等式,我们得知
c为常数。我们已知 公式2变化一下如下
第二步:M-step 在E-step中,我们得到了 M-step本质上就是求ln EM算法概要如下
EM算法通过不断提高目标函数 做了这么多分析,举两个例子,可能会更容易理解。先看第一个例子,来自文献[3]:
混合高斯模型 数据X是一个实例集合,它由k个不同的正态分布混合而成的分布生成,这里涉及k个不同的正态分布的混合,而且我们还不知道哪个变量实例由哪个分布生成的。因此这是一个涉及隐藏变量的典型例子。可以把每个实例完整描述成 算法伊始,我们首先假设一个模型参数初始值,接下来就是计算我们的目标函数
公式2
接下来就是E-step.我们的目标是选择一个概率分布 这里E[Zij]=实例Xi由第j个高斯分布生成的概率
那此时我们目标函数
接下来就是M-step,在
然后算法就利用估算出的参数 因子分析 所谓因子分析,就是指从变量群中提取公共因子的方法,该因子是用来描述隐藏在观测变量中的一些更基本的,但又无法直接测量到的隐性变量。EM算法也可以用来解决这样的问题,从而能够估算出隐藏的公共因子及该模型的参数。文献4的博客给出了一个很好的说明,讲得比较清楚。这里主要是引用这篇文章的内容,加入一些自己的评论,使其更便于理解。 举个因子分析的例子,有m个n维特征向量的样本集,每个样本实例表示为
其中
因子遵循多元正态分布,
下面来分析EM算法的使用,首先明确我们的目标,我们的目标是根据样本实例集估算出参数值 回想EM算法,那么对应因子分析,其E-step如下: 我们将观测到得实例变量X和隐藏变量Z组成一个联合的变量Y,该联合变量Y也符合多元高斯分布。为什么Y也符合多元高斯分布呢?很简单,首先Z是一个多元高斯分布,而X是多元高斯分布变量Z的一个线性变化,所以X也是一个多元高斯分布(参见文献[5],多元正态分布的线性变化仍然是),那么X,Z组合成的变量Y也符合高斯分布。其公式代表如下:
参见文献[5],你会发现多元正态分布的另外一个特性,多元正态分布的条件分布仍然是多元正态分布 该特性表述如下:
对应我们的例子,就有
这个过程中利用了z和
那么就可以得到Y的分布:
套用上述的特性-性质6,就有
这就是我们的目标。E-step就到此为止。再看M-step,M-step的目标函数如下
分别对3个参数求该目标函数的偏导,得到3个偏导公式,让其都为0,组成一个方程组。该方程组的解就是我们待沽参数。 具体的公式推导参见文献[4],文献[4]给出了比较详细的推导,如果对多元高斯分布了解的比较深入的话,该推导应该不难读懂。 个人觉得文献[3]中关于EM的讲述有一些瑕疵,讲得不是很清楚,但是文中的例子倒是可以作为参考。文献[4],[5]对此讲述的比较清楚,是个非常不错的参考,值得一读。
参考文献: [1]理解EM算法 52nlp [2]http://zh.wikipedia.org/wiki/%E5%87%B8%E5%87%BD%E6%95%B0 [3]数据挖掘原理与算法-毛国君 [4]http://www.cnblogs.com/jerrylead/archive/2011/05/11/2043317.html [5]多维高斯分布讲解http://www.docin.com/p-121202383.html [6] EM算法http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html [7] The Top Ten Algorithms in Data Mining |
EM Alogrithm
EM算法