基本排序算法小结
一、插入排序
1 排序思想
将待排序的记录Ri,插入到已排好序的记录表R1, R2 ,…., Ri-1中,得到一个新的、记录数增加1的有序表。 直到所有的记录都插入完为止。复杂度为O(n2) 。
设待排序的记录顺序存放在数组R[1…n]中,在排序的某一时刻,将记录序列分成两部分:
◆ R[1…i-1]:已排好序的有序部分;
◆ R[i…n]:未排好序的无序部分。
显然,在刚开始排序时,R[1]是已经排好序的。
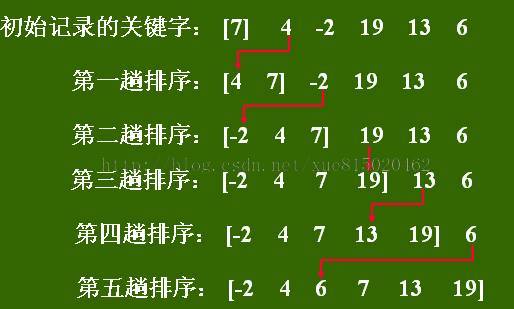
例:设有关键字序列为:7, 4, -2, 19, 13, 6,直接插入排序的过程如下图所示:
代码如下:
//直接插入排序
void straight_insert_sort(int *L,intlength)
{
inti, j,temp ;
for(i=1; i<=length; i++)
{
temp=L[i];
j=i-1; /* 设置哨兵 */
while(temp<L[j])
{ L[j+1]=L[j];
j--;
} /* 查找插入位置 */
L[j+1]=temp; /* 插入到相应位置 */
}
}
二、 选择排序
最简单的排序算法,过程如下:选出数组中最小的元素,将它与数组中第一个元素交换。然后找出次小的元素,将它与数组中第二个元素交换,一直持续下去,直到整个数组排序结束。之所叫选择排序,是因为它不断选出剩余元素中的最小元素来实现。
实现代码如下:
void selection(Item a[],int l,int r)
{
int i,j;
for(i=l;i<r;i++)
{
intmin=i;//最小元素索引
for(j=i+1;j<=r;j++)
{
if(less(a[j]),a[min])
{
min=j;//更新最小元素的索引值
}
}
exch(a[i],a[min]);//交换
}
}
选择排序的执行时间由比较操作的数目决定,所使用的次数大概是
:比较操作次数N*N/2,交换操作次数是 N次。而且选择排序的时间消耗与当前序列的排序状态无关。
三、 希尔排序
希尔排序时插入排序的扩展,他通过允许非相邻的元素进行交换来提高执行效率。希尔排序的本质:h-排序,是每第h个元素产生一个排序好的文件。h-排序的文件时h个独立的已排序好的文件,相互交叉在一起。对h值较大的h排序文件,可以移动相距较远的元素,比较容易的使h值较小时进行h排序,通过直到1的h值的排序,产生有序文件。
void hell(int *data,int left,int right)
{
intlen=right-left+1;
intd=len;
while(d>1)
{
d=(d+1)/2;
for(int i=left;i<right+1-d;i++)
{
if(data[i+d]<data[i])
{
inttmp=data[i+d];
data[i+d]=data[i];
data[i]=tmp;
}
}
}
}
希尔排序要选择一个比较好的步长序列。
四、 冒泡排序
冒泡排序很简单:遍历文件,如果紧邻的两个元素顺序不对,就将两者交换,重复这个操作,直到整个序列排好序。对于l~r-1的i值,内部循环j通过从右到左遍历元素,对连续的元素执行比较—交换操作,实现将a[i],…a[r]中最小的元素放大a[i]中。在所有的比较操作中,最小的元素都要移动,冒到最前端。
void maopao(Item a[],int l,int r)
{
inti,j;
for(i=l;i<r;i++)
{
for(j=r;j>i;j--)
{
if(less(a[j],a[j-1]))
{
Itemtemp=a[j];
a[j]=a[j-1];
a[j-1]=temp;
}
}
}
}
在最坏情况和平均情况下,冒泡排序执行大约N*N/2次比较操作和N*N/2次交换操作。
五、快速排序
快速排序算法是一种分治排序算法,它将数组划分为两部分,然后分别对这两部分进行排序。它将重排序数组,使之满足一下三个条件:
1,对于某个i,a[i]在最终的位置上
2,a[l]…a[i-1]中的元素都比a[i]小
3,a[i+1] …a[r]中的元素都比a[i]大
通过划分后完成本轮排序,然后递归地处理子文件。
如果数组中有一个或者0个元素,就什么都不做。否则,调用以下算法实现快速排序:
int partition(Itema[],int l,int r)
{
int i=l-1,j=r;
Item v=a[r];
for (;;)
{
while (less(a[++i],v))
{
;
}
while (less(v,a[--j]))
{
if (j==1)
{
break;
}
}
if (i>=j)
{
break;
}
exch(a[i],a[j]);
}
exch(a[i],a[r]);
return i;
}
变量v保存了划分元素a[r],i和j分别是左扫描指针和右扫描指针。划分循环使得i增加j减小,while循环保持一个不变的性质---------i左侧没有元素比v大,j右侧没有元素比v小。一旦两个指针相遇,我们就交换啊a[i]和a[r],,这样v左侧的元素都小于v,v右侧的元素都大于等于v,结束划分过程。
划分是一个不确定的过程,当两个指针相遇,就通过break语句结束。测试j==1用来防止划分元素是文件总的最小元素。
voidquichsort(Item a[],int l,int r)
{
int i;
if (r<=l)
{
return;
}
i=partition(a,l,r);
quichsort(a,l,i-1);
quichsort(a,i+1,r);
}
注:快速排序是一个递归划分过程,我们对一个文件进行划分,划分原则是将一些元素放在它最终的位置上,对数组进行排序使比划分元素小的元素都在划分元素的左边,比划分元素大的元素都在划分元素的右边,然后分别对左右两部分进行递归处理。然后,从数组的左端进行扫描,直到找到一个大于划分元素的元素,同时从数据的右端开始扫描,直到找到一个小于划分元素的元素。使扫描停止的这个两个元素,显然在最终的划分数组中的位置相反,于是交换二者。继续这一过程,我们就可以保证比划分元素小的元素都在划分元素的左边,比划分元素大的元素都在划分元素的右边。