Solr基本介绍
- 目的
为了实现用户数据的空间位置的搜索,以及其他用户数据内容的全文检索。并且要支持高可用性。根据要求查到solr满足我们的需求,详细如下(基于SolrCloud)
- 搜索方面:支持全文检索和空间搜索,并且支持返回值类型全面(XML/XSLT, JSON, Python, Ruby, PHP, Velocity, CSV, binary),还有排序,分页等查询支持。
- 在可靠性方面支持:基于ZooKeeper的配置,自动分布式索引和分片。发送数据到任意节点,solr会自动转送到正确的片。使用事务日志保证即使在数据还未索引到磁盘上的时候,也能不会丢失更新的数据,查询失败的自动故障转移,不会出现单点问题
- 性能方面:支持推送数据近实时的建立索引
2.初步安装
首先在官网下载solr,地址如下http://www.apache.org/dyn/closer.cgi/lucene/solr/4.3.1,本文以4.3.1为例,下载完成后解压缩后内容如下
![]()
本文只讲初步试用,所以进入example目录中
![]()
在运行前,需要保证机器上安装有jdk1.6以上版本,官方文档上说oracle,openjdk和ibm的jdk都可以,不知道官方包使用哪个JDK编译的,如果怕有问题,可以自己下载源码然后进行编译。参考http://wiki.apache.org/solr/HowToCompileSolr。
在example目录下执行 java -jar start.jar启动solr服务。简要说明一下,solr可以在任意java servlet容器中启动,例子工程中包含了一个小的jetty容器。此时solr服务会启动起来,默认端口为8983,然后你就可以通过http://localhost:8983/solr/ 访问solr服务了
3.管理界面
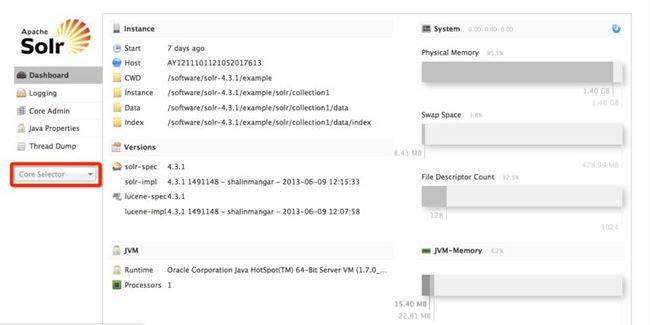
进入solr服务后的界面如上图所示,基本上都是显示了一些基本信息,例如服务启动时间,服务主机名,相关程序和数据的存放位置等。右边还有一些运行时信息显示。
说下基本概念,collection是一个目录的路径,用来存储索引等相关数据,可以在solr.xml中配置。下图是默认配置信息

4.Schema
当你更新索引的时候提交的数据需要通过schema文件中配置的字段进行匹配,如果提交的数据中在schema中没有,则会报错。在schema.xml中配置了针对。
文件位于/solr/example/solr/collection1/conf,路径下
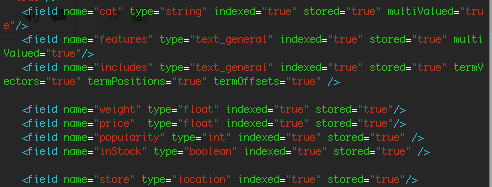
上图是例子工程中的schema,对field中的属性做下说明:
name:必须要有的字段,field的名字
type:必须要有的字段,field的类型
indexed:如果需要针对此字段进行搜索和排序的话,这个值应该是true
stored:如果需要检索这个字段的话,此值应该是true
docValues:只支持由StrField UUIDField的
Trie树,这三类型的数据,并且可能需要默认值。例子参考下
<field name="popularity" type="int" indexed="true" stored="true" docValues="true" default="0" />
<field name="manu_exact" type="string" indexed="false" stored="false" docValues="true" default="" />
default:默认值,如果插入的时候此值为空,则默认插入默认值。和数据库的默认值一个意思。
OmitNorms:建议专家才设置次属性。原始类型数据(int,float,boolean,string)此值默认为true,此值省略部分操作,提升性能。
等等等。。。
下图是例子工程中的部分fieldtype配置:

这些内容是配置的对指定类型的数据如何处理,如果是中文分词的话加入如下配置,并且把IKAnalyzer的jar包放入solr的lib目录下:
<fieldType name="text_ik" class="solr.TextField" >
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer" />
</fieldType>
关于solr的分析器、断词工具和标记筛选器的资料参考http://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters.
Schema文件中还需要有个唯一约束的字段,默认是id,如下图所示
![]()
5.基本查询
Solr 接受 HTTP GET 和 HTTP POST 查询消息。solr的主要查询参数为,具体参考http://wiki.apache.org/solr/CommonQueryParameters#q
- q:
Q是主要的查询参数,基本查询内容的条件都在这里。因为solr是基于lucene的,但是solr和lucene的q参数有些许差异,具体参考http://wiki.apache.org/solr/SolrQuerySyntax 。
- sort
此参数用来排序,详细信息参考下图。

- start
此参数是用来分页用的,从查询结果中的第几条开始现实,默认是0
- rows
最大返回结果数
- fq
次参数是查询结果的过滤条件,他的缓存和主查询的缓存是分开的,这样可以增加复杂查询的效率。关于缓存的信息参考http://wiki.apache.org/solr/SolrCaching
- fl
控制返回值的哪些哪些字段给返回,类似于select A,B from table 中的A、B。默认值是*