摘要:HashMap与ConcurrentHashMap的源码实现分析、它们之间的区别。
HashMap抛ConcurrentModificationException的原因。为什么HashMap不是线程安全的。ConcurrentHashMap是如何提升并发性能的。可能影响性能的地方。
导语:HashMap与ConcurrentHashMap是使用非常广泛的容器类,学习其源码,我认为是Java初学者的必修课,不仅可以学习其优秀的设计和代码风格,还可以对线程安全有更深的理解。本文对关键操作进行图解说明,以帮助初学者理解,对着代码看会更清楚。
Map<K, V>: 键值对Entry<K, V>的集合。基本的操作put(k, v)、get(k)。
HashMap<K, V>: Map<K, V>的一种实现,用数组存储Entry,通过K的hash值定位Entry的位置。同一位置会出现多个Entry,称为hash冲突,用next连接形成单向链表。
初始化构造函数有两个参数:初始容量initialCapacity(16)、加载因子loadFactor(0.75)
initialCapacity决定数组的初始大小,loadFactor决定HashMap容量达到多少时resize数组。
为什么要resize呢,因为随着put的entry增加,hash到同一位置的entry也增多,链表变长,影响性能。resize是将数组的大小*2,所有entry重新找位置,涉及大量变更。所以如果HashMap的entry个数大致确定,且很大的话,指定initialCapacity可以减少resize,稍稍提升性能。loadFactor的设定依赖hash冲突的严重性,设置小一点可以稍微缓解hash冲突,一般不需要调整。
如果指定initialCapacity,会自动扩充到最接近的2的n次方,目的是在hash定位时可以用与操作替代取模操作,提升性能。(假设数据大小为n,即用hash&(n-1)替代hash%n)
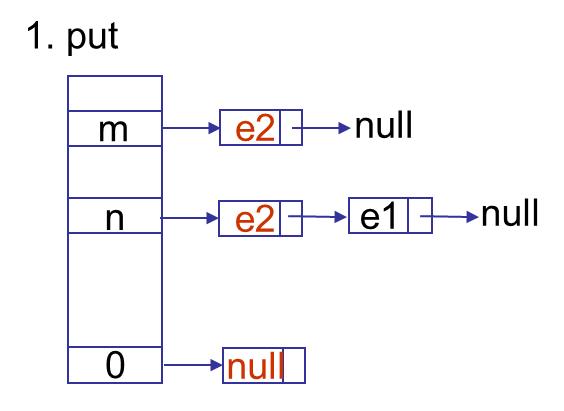
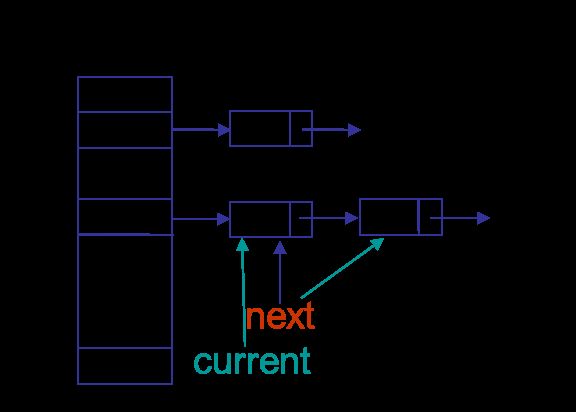
get操作很简单,如果K为null,直接去位置0找。否则通过K的hash值找到在数组中的位置,逐个比较,直到找到hash值相同且K相等的entry返回。我们来看put操作,先类似get的方式找,找到则更新V返回。未找到,需要添加,下图是添加e2的三种情况:位置m为空,位置n已经有值,K为null放在位置0。
在hash定位时,会对K的hash值再做一次hash,使Entry尽可能地均衡分布,避免链表过长,影响性能。
remove先查找定位到e,将e的pre的next指向e的next,即(e.prev.next=e.next),由于没有prev指针,在查找的过程中记录prev。
下面说下迭代遍历操作用到的关键类HashIterator。在初始化时,从数据0始找到第一个不为null的位置n,设置next=arr[n],即next=e1,current=null。在调用nextEntry时,设置current=next,返回current。继续设置next,next=e1.next,即next=e2。如果e1.next为空,则再查找下一个不为null的位置m。
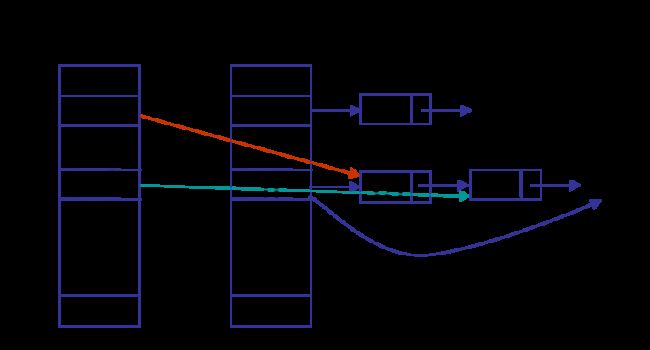
resize操作,从0开始,将entry逐个移到新扩容的数据,相当于remove+put操作。
说说HashMap的线程安全问题,首先说HashMap不是线程安全,但它有一种fast-fail机制,能保证在迭代过程发生结构化变更时,会抛出ConcurrentModificationException。
什么是结构化变更,前面的修改操作中你会看到一个计数器modCount,add和remove操作都会modCount++,在迭代遍历时,初始化保存expectedModCount = modCount,每次nextEntry操作会检查modCount是否变化。
那HashMap为什么不是线程安全的呢,其实只要看看ConcurrentHashMap相对HashMap在各操作上做了哪些线程安全的考虑,就能很好的理解。
首先,看看Entry的改变:
HashMap的Entry:
V value;
Entry<K,V> next;
ConcurrentHashMap中的HashEntry:
volatile V value;
final HashEntry<K,V> next;
V定义成volatile,这样保证V在修改后对其他线程立即可见,但volatile不保证修改V操作的原子性,所以在读到V为null时,还需要加锁再读一次readValueUnderLock。
next定义为final,这样next在初始化后不可修改,在编译时就保证next不会被修改。这样也使得add和remove操作更加复杂,不能像上面HashMap直接修改next。
其次,在put和remove等任何写操作时,都加锁访问。因为多线程情况下,连HashMap的size++都不是线程安全,它是一个读取-修改-写入的组合操作。
还有很多细节处,这里不一一细述,读者可以认真考量每一行代码。
扩展阅读:
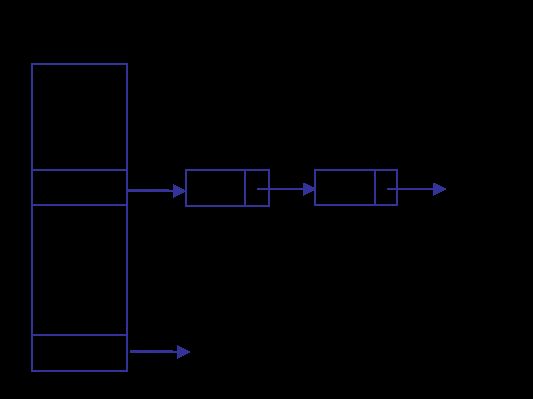
那么,因为加锁同时只能有一个线程访问,ConcurrentHashMap如何提高并发访问的性能呢?ConcurrentHashMap很好的诠释了减少锁的粒度的并发优化思路,将整个map分成多Segment,在同一时刻只锁定一个段(大多时候是这样,在计算size()失败后,会锁定全部段,所以尽量少调用size()方法)。通过concurrencyLevel可以指定Segment[]的大小,默认是16,增大它可以获得更好的并发性能。先通过hash定位段,再定位在段中的位置。它看起来是这样:
还有一个小差异点,ConcurrentHashMap不支持K为null。

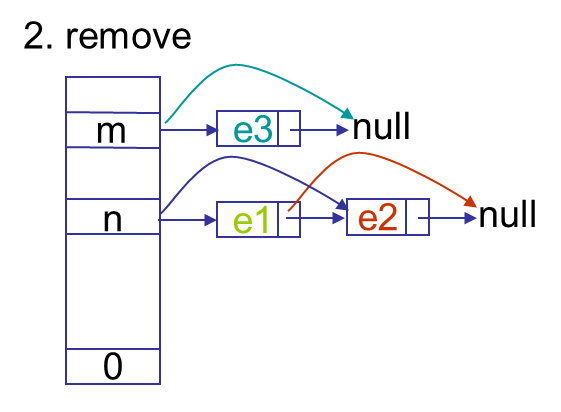
get除了checkNull外,与hashmap大同小异,说说remove。假设要删除e3,对e3后面的entry不需要重建,由于next是final,e3前面的entry都需要重建。先重建e1,e1.next=e3.next,再重建e2,e2.next=e1,最后arr[n]=e2。这样e3前面的entry在链表中的顺序会倒过来。
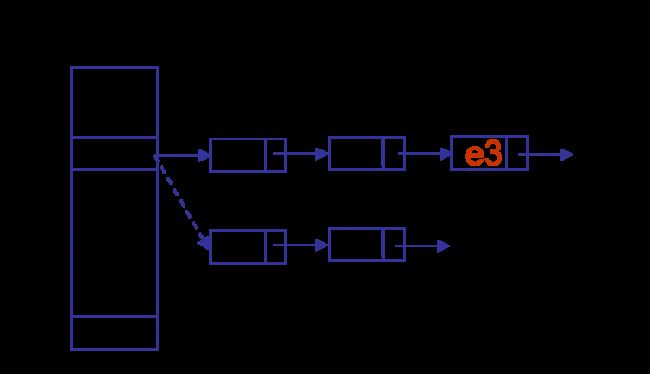
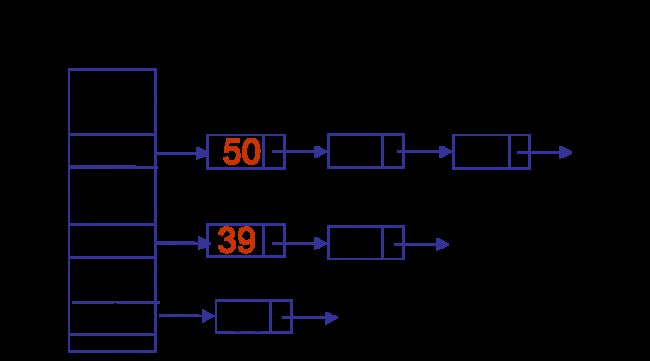
另外值得一提的是rehash的改进,从后找到第一个需要重建的entry,在它之前的全部重建,在它之后的可以不用重建。据作者说only 1/6 need clone。如下,仅39和50需要重建。