Velocity笔记(上)
Velocity笔记(上)
杂七杂八的看了一些velocity的资料,把所见所得做个简单不系统的笔记写下来,算是增强记忆。
动态语言的特性:
动态语言需要一个解释器,而这个解释器一般在服务器中。
MVC
Model:系统和应用的状态表示,一般是类或者其他数据结构。可以改变系统状态的Actions和method。典型的javabean。设计初衷就是为了数据和显示的分离
View:显示结果数据的组成部分,随着model的不同以及状态改变,view也要相应的做出变化。
Controller:用户和应用之间交互的桥梁。Controller捕获用户的输入,并利用既定逻辑决定将这些命令输入路由到哪一个model进行处理。
只使用jsp技术叫做model 1
加入servlet后叫做model 2
什么是Velocity
Velocity is a template language designed to give Web designers an easy way to
present dynamic information to users of a Web site or application.
Velocity有个集合叫做context,说白了就是controller和model层的封装,提供了网页模板。
实现了velocity的代码将利用从context中的对象里获取的数据替换模板中的脚本元素。
Velocity的使用简单代码:

一个简单的语言描述过程就是:将velocity初始化并在context中put进去对象,然后template加载某个vm模板,然后用template将这个vm和context进行merge,就生成了view页面了。
Context可以把其他类型的数据put进来,velocity会自动的调用这些对象的toString方法。
下面重点说说context。
Context介绍
Context本质上是一个介于java代码层和velocity模板层之间的一个数据桥梁。Java开发人员将各种各样的数据对象放到context中,页面模板设计人员从context取得这些对象的reference。Velocity中定义了VelocityContext来提供基本实现。这个实现与java中的hashtable类似,最有用和常用的方法就是
Public Object put(String key, Object value);
Public Object get(String key);
如果理解了context的容器特性,那么什么东西能放进去呢?context首先支持放一些迭代对象(Iterative Objects),比如对象数组Object[], java.util.Collection, java.util.Map, java.util.Iterator, java.util.Enumeration, 以及任意的有public Iterator iterator()方法的public class。其次context还支持put静态类(static class),比如context.put(“Math”, Math.class)。当然,在velocity运行时模板 产生的对象也可以放到context中。
Velocity的三种reference
变量variable:对应java对象的一种字符串化的表示,它返回的值是调用了java的toString方法后的结果。
方法method:调用所引用对象的某个方法,该方法必须是public类的一个public方法。如果该方法有返回值,那么velocity在调用完方法后会同样的对返回值进行toString包装。对参数的要求是velocity要求所有的方法参数也必须是string的。
属性property:类似方法,除了访问java类的属性外,还等价于get***方法。
$!前缀是quiet notation符号,用这个前缀产生的引用在引用对象不存在的时候,会返回“”字符串而不是不存在的对象的名字的字符串。
“"”是转义字符,可以转义$符号和其他符号
Velocity指令
#stop:用于debug,当engine遇到这个指令,就会停止执行,并将控制权返回给调用程序。
#include:用于包含外部文件,将外部文件的内容直接加入程序中。
#parse:与include类似,但是不同之处在于,include引入的是静态的文件,而parse会动态的加载模板,也就是说,parse会解析vm文件,然后再加入到源文件中去。
#set:就是一个很强大的赋值指令,不管被赋值的变量是否已经存在或赋值,新的set指令会完全覆盖。指令格式就是#set(ref=value)。几个值得注意的set用法如下

List和range的用法可以等同的看做是java里的ArrayList。
对boolean值的set,set支持短路short circuit,具体代码见下:

#end:声明一个程序块的结束,必须以#if或者#foreach或者#macro开始。
#if:就是普通的if,只不过在#if中,条件表达式里用true表示真,用false表示假,没有null表达式。测试null的话直接用#if($condition)指令即可。常用的逻辑操作符(&&||!)都可以使用,比较操作符也与java相同。
#else:接着#if的使用指令,逻辑分支,同java等其他语言的逻辑一样。有一点需要注意,没有#else的#if需要#end,有了#else,那么#end加在#else后即可,#if后不需要再加#end。如:

#elseif:就是多分支情况下的else if合写。对#end的要求同#else。

#foreach:直接用例子解释:

当然需要补充一点的是,这个循环访问的list的生成不仅可以在页面中定义,如上例,也可以在context中产生,比如在put的时候就把java的array或者实现了集合类的map,collection等put进去。当然,直接foreach一个map,那么就是访问的map的value,想访问它的key的话需要调用该map的keySet方法得到set。Foreach的内置循环增量叫做$velocityCount。
#macro:就是velocity里对于c语言中的宏的概念,注意不是函数,功能虽然类似,但是macro是在运行时之前就确定好的,因此用#parse解析无效。语法就是#macro(name $param1 $param2)这样的样式,其中name是宏的名字,后面的param是参数。调用时候的参数的个数一定要与声明的匹配,velocity不提供默认参数和重载实现。参数类型可以是字符串,数字常量,boolean,range操作符,数组列表和velocity引用。
想定义一个全部vm通用的宏,那么要把它放在VM_global_library.vm里。
Velocimacro properties
Velocimacro.library:声明组成velocimacro library的文件名。默认是VM_global_library.vm
Velocimacro.permissions.allow.inline:如果设置这个属性为false,那么内联的macro声明将不被引擎执行。默认是true的。
Velocimacro.permissions.allow.inline.to.replace.global:声明一个内联的macro是否可以override一个library提供的macro。默认是false。
Velocimacro. permissions.allow.inline.local.scope:声明模板是否可以提供私有的关于velocimacro的命名空间。一旦被设置为true,那么内联的macro只可以被本模板看到。默认是false。
Velocimacro.context.localscope:声明在使用velocimacro时#set指令所影响的velocity的context的行为(好蹩脚)。就是说,一旦设置这个属性为true,velocimacro只接受本地的context。调用者注入到context中的对象将不被看到。默认是false。
Velocimacro.library.autoreload:声明一个修改后的velocimacro library是否在macro被调用时自动reload。默认是false。
Velocimacro.messages.on:声明是否由引擎产生额外的log信息,默认是true。
递归和嵌套macro都是允许的,但是递归的方法是不推荐的。
下面是讲velocity是如何开始作用的:
通过调用Velocity.init()这个静态方法,我们初始化了runtime。这个调用的结果就是运行时的引擎通过读取org/apache/velocity/runtime/defaults/velocity.properties文件被初始化。Velocity提供了3种定制技术去定制runtime configuration。
第一种技术:自定义一个properties文件,然后通过init的带参数方法初始化velocity引擎。
第二种技术:在运行时构建一个java的Properties对象,然后通过set方法注入属性,在程序代码中传递给init参数。
第三种技术:为了更细粒度的控制velocity引擎的初始化,一些细节的实现就是可以利用velocity自己的一些静态方法在init之前去修改属性文件。比如Velocity.setProperty(String propertyName, String value)。
更多的属性:
Directive类的
Directive.foreach.counter.name:声明了foreach循环中的循环变量名字,默认是velocityCount。
Directive.foreach.counter.initial.value:声明了循环时循环变量的初始值,默认是1,虽然C系语言的初始值都为0.
Directive.include.output.errormsg.start:声明了在include调用时输入错误参数所显示的出错提示文本的开头,默认是“<!—include error:”。
Directive.include.output.errormsg.end:同上,代表了结尾,默认值是“see error log -->”
Directive.parse.max.depth:这个声明了parse命令的最大嵌套深度。默认是10.
Encoding类的
Input.encoding:声明被模板引擎处理的模板的编码,默认是ISO-8859-1.
Output.encoding:声明关联到输出流的编码,默认是ISO-8859-1。
Logging类的
Runtime.log:声明velocity的log文件所在的路径,默认是velocity.log。
Runtime.log.logsystem:声明velocity的log任务系统,设置的值需要实现org.apache.velocity.runtime.log.LogSystem接口。无默认值。
Runtime.log.logsystem.class:声明velocity运行时用于处理logging服务的类名,包含一系列用逗号隔开的列表。默认值是runtime.log.logsystem.class property is org.apache.velocity.
runtime.log.AvalonLogSystem,org.apache.velocity.runtime.log.SimpleLog4J
logSystem. Logging may be disabled by providing a value of org.apache.velocity.
runtime.log.NullLogSystem
runtime.log.error.stacktrace:
runtime.log.warn.stacktrace:
runtime.log.info.stacktrace:这三个分别用来声明运行时引擎在记录错误、警告和信息消息时是否开启stacktrace。默认值都是false。
Runtime.log.invalid.references:声明非法引用在模板中发现时是否记录的标记,默认是true。
Resource Management类的
Resource.manager.class:声明处理velocity资源管理任务的类,该类必须实现org.apache.velocity.runtime.resource.ResourceManager接口。默认值是org.apache.velocity.runtime.resource.ResourceManagerImpl。
Resource.manager.cache.class:声明了资源管理缓存请求的类,该类必须实现org.apache.velocity.runtime.resource.ResourceCache接口。默认是org.apache.velocity.runtime.resource.ResourceCacheImpl。
Resource.manager.logwhenfound:声明了资源管理在第一次定位资源时是否记录log。默认是true。
Resource.loader:关联一个名字给指定的resource loader。
<loader>.resource.loader.description:声明了resource loader的文字描述。
<loader>.resource.loader.class:声明了用于初始化加载关联资源类型的类,该类需要继承org.apache.velocity.runtime.resource.loader.ResourceLoader类,并且提供特定功能的资源类型。Velocity.properties提供了一个org.apache.velocity.runtime.resource.loader.FileResourceLoader的类。
<loader>.resource.loader.path:声明了一个根目录用来存放相关类型的资源。Velocity.properties提供了.作为根目录。
<loader>.resource.loader.cache:声明loader是否要缓存特定资源。一般建议true。
<loader>.resource.loader.modificationCheckInterval:声明了检查缓存资源是否有修改的时间间隔,以秒为单位。默认是2.
其他类的
Runtime.initerpolate.string.literals:声明了模板引擎是否要插入字符串常量,默认是true。
Parser.pool.size:声明了启动时runtime创建的parser pool的大小,默认是20.
Resource loaders资源加载
一个velocity的resource简单说就是一个提供给模板引擎的输入。包括正规模板、velocimacro的library、由include指令引入的普通文本。一个resource loader就是一个知道如何从这些特定的resource中提取资源的实体。一般用到的就是file resource loader,当然velocity还提供了3种其他loader类型:JAR, Classpath和DataSource。
Events事件
为了提供模板处理时的更好控制,velocity提供了事件处理等级,支持用户干预。
有三种事件类型:
第一, 在#set指令中为引用赋NULL的时候。
第二, Java方法调用velocity方法或属性引用出现异常的时候。
第三, 每次velocity引用对应的值插入输出流的时候。
Velocity提供了NullSetEventHandler, MethodExceptionEventHandler和ReferenceInsertionEventHandler接口去处理这些事件。
Context chaining
简单讲就是一层层的包装context(直觉让我想起façade模式),如果有重复的话,最外层的覆盖最里层的,但是本层的context对于重复的key还是可以保持可访问。实现方式是通过VelocityContext的重载构造方法。
Velocity和XML
velocity支持对xml的处理,只要加入类似这样的代码即可

接着在displayxml.vm这样写:

然后就可以咯。
如何输出XML与输出HTML是一致的。
结合velocity和servlet
其实很简单,写一个类,继承VelocityServlet。不需要普通的doGet和doPost方法,取而代之的是一个handleRequest方法,该方法传递3个参数,HttpServletRequest, HttpServletResponse和Context。前两个参数与普通的servlet一样,最后一个参数就对应了velocity模板引擎的context。该方法返回一个Template。基础代码如下:

HttpServletRequest和HttpServletResponse在context中同样存在,名字分别是req和res,我们可以写这样的代码去访问和读取request和response:
#set($username = $req.getParameter(‘username’))
VelocityServlet非常强大,除了简单的handleRequest方法外,还包括了一系列方法:
Properties loadConfiguration(ServletConfig):允许添加额外的servlet属性。
Context createContext(HttpServletRequest, HttpServletResponse):允许开发者创建自己的context,这个context可以进行似有的merge。
void setContentType( HttpServletRequest,HttpServletResponse):设置内容类型,默认的是text/html格式。
void mergeTemplate(Template, Context, HttpServletResponse):自行控制合并模板的方法,可以绕过handleRequest
void requestCleanup(HttpServletRequest, HttpServletResponse,Context):自行合并后的清理操作。
protected void error(HttpServletRequest, HttpServletResponse, Exception):错误处理。
Velocity和turbine的结合
可以说turbine是velocity的最好舞台,它天然的结合了velocity。
Turbine的三个特性:
1. 基于servlet作为控制器
2. 强调安全继承
3. 独立于web使用。
Turbine的MVC经典组合就是EJB作为模型,servlet写控制器,而velocity是显示。
先看看turbine的架构:
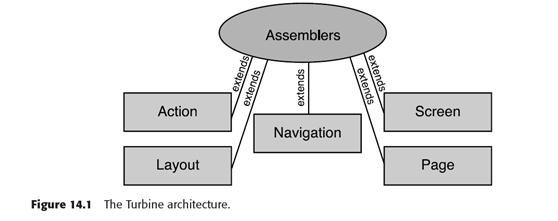
5大模块,都在assembler下面。其中
Action:完成特定任务的代码。
Navigation:用来显示导航链接和控制的velocity模板。
Screen:velocity模板和java类的组合,用来显示layout模块内的核心内容。
Layout:velocity模板,用来描述页面如何工作。
Page:一个包含了所有这些模块的概念级别的对象。
先来看看action模块:
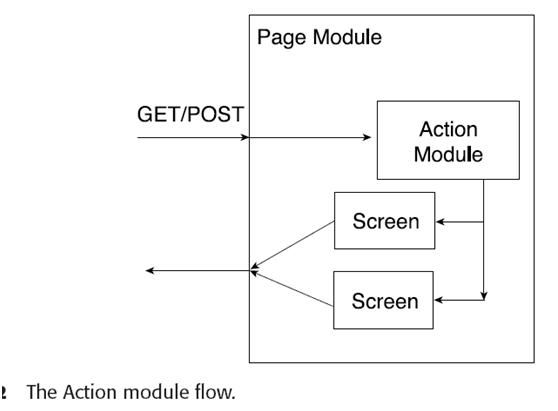
这个图是action和其他模块之间的一个流动视图。当有一个get或者post请求时,page模块将执行action模块,由action模块判断由哪个screen来显示信息。
Navigation模块:
说白了就是webx中的control,控制页面的上下左右各个部分,表达不同的所谓navigation schemes。这个模块是被layout执行的。
Screen模块:
Navigation模块展示了页面的各个边缘组成,那么screen就负责显示页面的核心内容。
Layout模块:
Layout如其名,就是通过布局来控制哪里安排navigation,哪里显示screen。
Page模块:
Page是整个web应用的外壳,请求也是先到达page的。Page更像一个容器,用来管理和联系整个的各个模块。
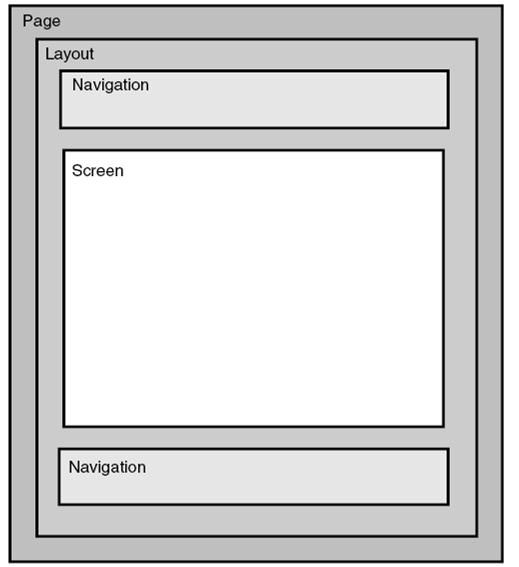
这个图显示了各个模块的包装关系。
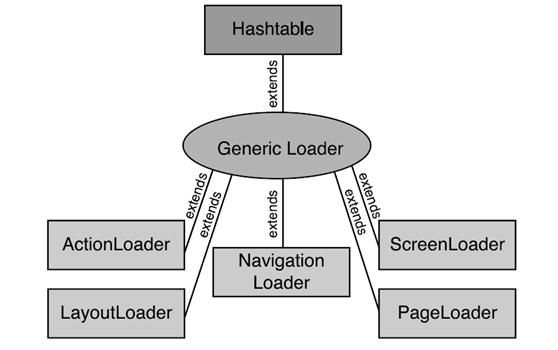
Turbine定义了5个loader去加载这5个模块,loader的结构图如下:
未完待续~~