Ubuntu下Bind DNS域名服务器的安装
预备:相关概念扫盲
DNS,
Domain Name System,即域名解析系统,用于实现“域名”与“ip”地址之间的相互解析。
正向解析(正解):将Domain解析为ip。
反向解析(反解):将ip解析为域名。
Zome(区域):一个正解或反解的设定为一个zone。
hadoop@ubuntu:~$ sudo apt-get install bind9
安装完成后,会在/etc/bind目录下生成如下的配置文件
root@ubuntu:/etc/bind# ls -l
total 52
-rw-r--r-- 1 root root 2389 Feb 18 05:45 bind.keys
-rw-r--r-- 1 root root 237 Feb 18 05:45 db.0
-rw-r--r-- 1 root root 271 Feb 18 05:45 db.127
-rw-r--r-- 1 root root 237 Feb 18 05:45 db.255
-rw-r--r-- 1 root root 353 Feb 18 05:45 db.empty
-rw-r--r-- 1 root root 270 Feb 18 05:45 db.local
-rw-r--r-- 1 root root 3048 Feb 18 05:45 db.root
-rw-r--r-- 1 root bind 463 Feb 18 05:45 named.conf
-rw-r--r-- 1 root bind 490 Feb 18 05:45 named.conf.default-zones
-rw-r--r-- 1 root bind 165 Feb 18 05:45 named.conf.local
-rw-r--r-- 1 root bind 890 Apr 3 23:55 named.conf.options
-rw-r----- 1 bind bind 77 Apr 3 23:55 rndc.key
-rw-r--r-- 1 root root 1317 Feb 18 05:45 zones.rfc1918
重要配置文件解释:
named.conf:name参数的设置,配置服务器使用的域数据库信息源。该文件内容如下:
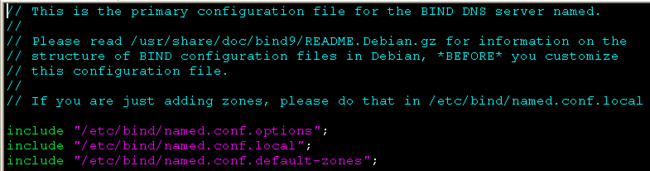
可以看到该文件主要指定了几个named相关配置文件的位置。
named.conf.options:全局选项配置,通常不用修改。
named.conf.local:用于用户配置dns时,添加Zone的配置信息
named.conf.default-zones:正解和反解Zone的配置,该文件的主要格式如下:
zone "localhost" {
type master;
file "/etc/bind/db.local";
};
zone "127.in-addr.arpa" {
type master;
file "/etc/bind/db.127";
};
其中,localhost zone表示正解zone,其中的type表示定义域名服务器的类型,可为如下值:
master:主域名服务器
slave:辅助域名服务器
hint:互联网中的根域名服务器
其中,file选项用于指定zone配置文件的位置。
db.local:localhost正向zone文件,用于将localhost解析为127.0.0.1。该文件的内容如下:
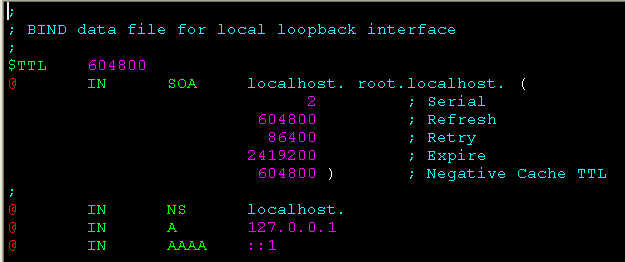
其中,几个重要的配置说明:
SOA:主要用户主服务器和从服务器之间的dns数据库资料的同步。该行“@”表示该文件对应的zone,后面指定的是这个zone的 授权主机和 管理者的邮箱。由于“@”在DNS记录中是一个保留字符,所以SOA中用“.”来代替“@”,所以管理者邮箱为“root@localhost”。
Serial:主服务器的序列号,当从服务器发现主服务器的序列号比自身的大时,就会进行DNS数据库的同步。
Refresh:从服务器请求DNS数据库同步的时间间隔。
Retry:当从服务器进行同步失败,再次进行重试的时间间隔。
Expire:记录的逾期时间,当从服务器一直无法与主服务器取得联系,那么过了该时间后,资料将标识为过期。
NS:表示localhost这个域的主机是localhost
A:标明了IP地址与域名之间的对应关系。
db.127:localhost反向区文件,用于将127.0.0.1解析为localhost。
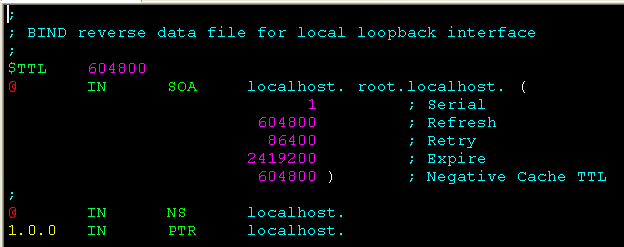
其中的PTR表示的是反向解析。
实践例子:
假设现在,我们有三台主机来构建hadoop集群,三台主机之间的域名与ip的对于关系如下:
namenode.hadoop 192.168.3.150
slave1.hadoop 192.168.3.151
slave2.hadoop 192.168.3.152
根据上面的域名与ip之间的对应关系,这里假设我们将192.168.3.150也即我们namenode节点设置为域名服务器,我们需要通过如下三步来构建该dns服务器:
① 首先添加正向区域"hadoop"和反向区域“3.168.192.in-addr.arpa”相对应的文件。
② 在"hadoop"区域中添加A记录:namenode对于150,slave1对应151,slave2对应152。
③ 在
“3.168.192.in-addr.arpa”区域中添加151对于namenode,151对应slave1,152对应slave2。
一、修改所有机器的/etc/network/interfaces文件,设置各自静态的ip和指定dns-server。如下为slave1节点的该文件的配置信息:
# interfaces(5) file used by ifup(8) and ifdown(8)
auto lo
iface lo inet loopback
auto eth0
iface eth0 inet static
address 192.168.3.151
netmask 255.255.255.0
gateway 192.168.3.1
dns-nameservers 192.168.3.150
说明:网上说指定dns可以通过设置
/etc/resolv.conf文件,但是发现该文件在系统重启后,由恢复为系统默认设置了,虽然网上又有人说可以将dns服务器信息加在
/etc/resolvconf/resolv.conf.d/base文件后,重启后就不会改变了,但是我尝试了,还是不行。
二、编辑/etc/bind/named.conf.local文件,该文件的内容如下:
zone "hadoop" {
type master;
file "/etc/bind/db.hadoop";
};
zone "3.168.192.in-addr.arpa" {
type master;
file "/etc/bind/db.192.168.3";
};
三、创建并编辑db.hadoop文件,该文件的内容如下:
;
; BIND data file for local loopback interface
;
$TTL 604800
@ IN SOA namenode.hadoop. root.namenode.hadoop. (
2 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS namenode.hadoop.
namenode IN A 192.168.3.150
slave1 IN A 192.168.3.151
slave2 IN A 192.168.3.152
四、创建并编辑
db.192.168.3文件,该文件内容如下:
;
; BIND reverse data file for local loopback interface
;
$TTL 604800
@ IN SOA namenode.hadoop. root.namenode.hadoop. (
1 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS namenode.hadoop.
150 IN PTR namenode.
151 IN PTR slave1.
152 IN PTR slave2.
五、重启系统并使用nslookup命令测试
首先我们在namenode机器(192.168.3.150)上测试:
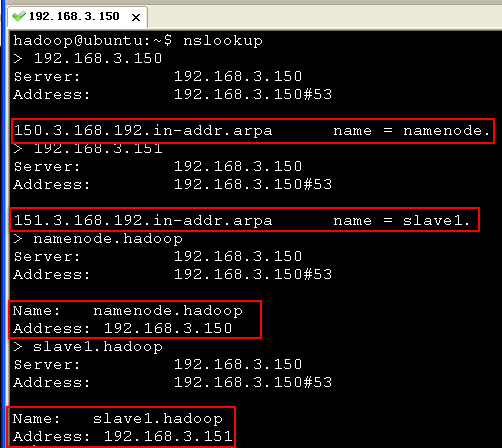
然后,我们在slave1机器(192.168.3.151)上测试:
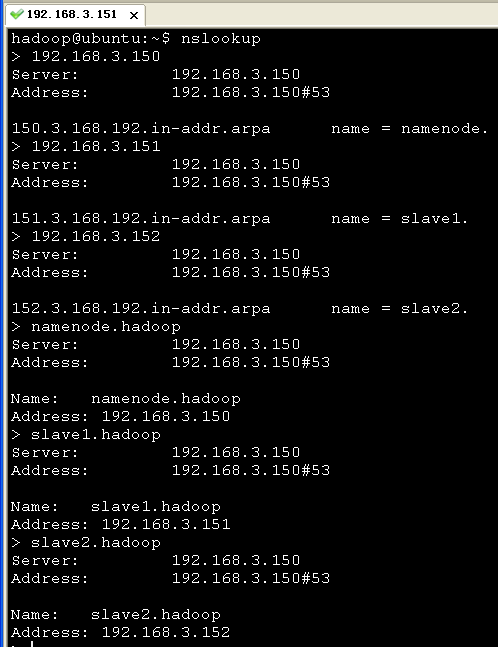
说明:我们的bind9软件只需仅安装在作为dns服务器的一台机器上,其他机器不需要安装.
利用DNS在搭建Hadoop集群就更方面了,利用host文件来管理域名到ip地址之间的映射关系,当我们的集群需要增加一台机器时,需要修改所有机器的host文件,而利用DNS的话,我们只需要修改dns服务器下/etc/bind/db.hadoop和/etc/bind/db.3.168.192以及新增机器
/etc/network/interfaces文件即可。
来自为知笔记(Wiz)
附件列表