hadoop学习一:HDFS
HDFS和KFS都是GFS的开源实现,而HDFS是Hadoop的子项目,用Java实现,为Hadoop上层应用提供高吞吐量的可扩展的大文件存储服务。KFS是web级一个用如存储log data、Map/Reduce数据的分布式文件系统,也是基于google文件系统项目简历,用C++实现。
http://www.cnblogs.com/chinacloud/archive/2010/12/03/1895369.html
一、HDFS的基本概念
HDFS为分布式计算存储提供底层支持。HDFS的设计思想:构建一个非常庞大的分布式文件系统。在集群中节点失效是正常的,节点的数量在Hadoop中不是固定的。单一的文件命名空间,保证数据的一致性,写入一次多次读取。典型的64MB数据块大小,每个数据块在多个DN(DataNode)有复制客户端通过NN(NameNode)得到数据块的位置,直接访问DN获取数据。

1.1数据块(block)
- HDFS(Hadoop Distributed File System)默认的最基本的存储单位是64M的数据块。
- 不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
- 从上图中看,一个文件被分成一个或多个Block,存储在一组Datanode上。
- Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求,Namenode的统一调度下进行数据块的创建、删除和复制。
1.2NameNode功能
管理文件系统的命名空间,映射一个文件到一批数据块,映射数据块到DN节点上。集群配置管理,数据块的管理和复制。处理事务日志:记录文件创建、删除等。因为NameNode的全部元数据存储在内存中,所以NN的内存大小决定整个集群的存储量。
NN内存中保存的数据:
1、文件列表
2、每个文件的块列表
3、每个DN中块列表
4、文件属性:生成时间、复制参数,文件许可(ACL)
1.3 Secondary Namenode功能
Secondary Namenode辅助NN处理Fsimage(文件系统镜像)和事物日志的Server,它从NN拷贝FsImage和事务日志到临时目录,合并FsImage和事务日志生成一个新的FsImage,上传新的FsImage到NN上,NN更新FsImage并清理原来的事务日志。
1.4 DataNode功能
在本地文件系统存储数据块,存储数据块的元数据,用于CRC校验。响应客户端对数据块和元数据的请求,周期性的向NN报告这个DN存储的所有数据块信息。客户端要存储数据时从NN获取存储数据块的DN位置列表,客户端发送数据块到第一个DN上,第一个DN收到数据通过管道流的方式把数据块发送到另外的DN 上。当数据块被所有的节点写入后,客户端继续发送下一个数据块。DN每3秒钟发送一个心跳到NN,如果NN没有收到心跳在重新尝试后宣告这个DN失效。当 NN察觉到DN节点失效了,选择一个新的节点复制丢失的数据块。
数据块的放置位置和数据正确性:
在典型的配置里,数据块一个放在当前的节点,一个放在远程的机架上的一个节点,一个放在相同机架上的一个节点,多于3个的数据块随意选择放置。客户端选择最近的一个节点读取数据。Hadoop使用CRC32效验数据的正确性,客户端每512个byte计算一次效验,DN负责存储效验数据。客户端从DN获取数据和效验数据,如果效验出错,客户端尝试另外节点上复制的数据。
HDFS如何存储?
流水线复制:当客户端向HDFS文件写入数据的时候,一开始是写到本地临时文件中。假设该文件的副本系数设置为3,当本地临时文件累积到一个数据块的大小时,客户端会从Namenode获取一个Datanode列表用于存放副本。然后客户端开始向第一个Datanode传输数据,第一个Datanode一小部分一小部分(4 KB)地接收数据,将每一部分写入本地仓库,并同时传输该部分到列表中第二个Datanode节点。第二个Datanode也是这样,一小部分一小部分地接收数据,写入本地仓库,并同时传给第三个Datanode。最后,第三个Datanode接收数据并存储在本地。因此,Datanode能流水线式地从前一个节点接收数据,并在同时转发给下一个节点,数据以流水线的方式从前一个Datanode复制到下一个。
1.2.1元数据文件夹结构
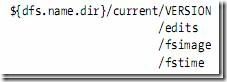
VERSION文件是java properties文件,保存了HDFS的版本号。
- layoutVersion是一个负整数,保存了HDFS的持续化在硬盘上的数据结构的格式版本号。
- namespaceID是文件系统的唯一标识符,是在文件系统初次格式化时声称的
- cTime此处为0
- storageType表示此文件夹中保存的是元数据节点的数据结构
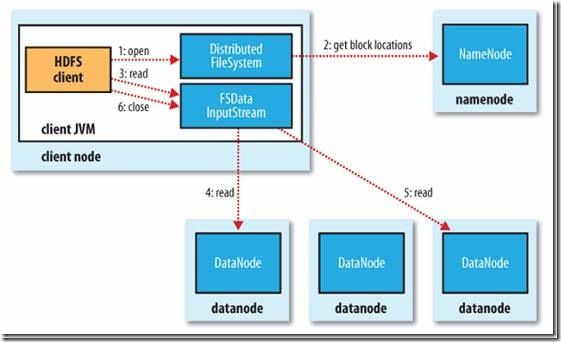
2.1读文件的过程
客户端(Client)用FileSystem的open()函数打开文件。
DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息。
对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据。
客户端调用stream的read()函数开始读取数据。
DFSInputStream连接保存此文件第一个数据块的最近的数据节点。
Data从数据节点读到客户端(client)
当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
失败的数据节点将被记录,以后不再连接。
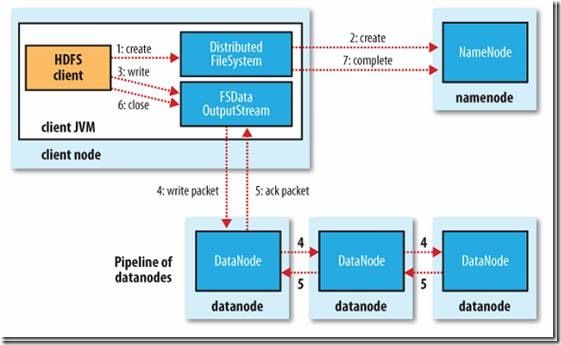
2.2、写文件的过程
客户端调用create()来创建文件
DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。
元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
DistributedFileSystem返回DFSOutputStream,客户端用于写数据。
客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。
Data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。
Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
如果数据节点在写入的过程中失败:
关闭pipeline,将ack queue中的数据块放入data queue的开始。
当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。
失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。
元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
2.3 文件系统命名空间影响文件及修改日志

http://www.cnblogs.com/forfuture1978/archive/2010/11/10/1874222.html
待完成
HDFS 存储测试
测试环境:
服务器:Linux
masters:192.168.4.128
slaves:192.168.4.128、192.168.4.42