第二章:引言
1. 来自bit.ly的1.use.gov数据
2011年,URL缩短服务bit.ly跟美国政府网站usa.gov合作,提供了一份从生成.gov或.mil短链接的用户那里收集来的匿名数据.
我们看到的文本数据如下:
In [1]:
path = '/Users/lgt/pydata-book/ch02/usagov_bitly_data2012-03-16-1331923249.txt'
open(path).readline()
Out[1]:
'{ "a": "Mozilla\\/5.0 (Windows NT 6.1; WOW64) AppleWebKit\\/535.11 (KHTML, like Gecko) Chrome\\/17.0.963.78 Safari\\/535.11", "c": "US", "nk": 1, "tz": "America\\/New_York", "gr": "MA", "g": "A6qOVH", "h": "wfLQtf", "l": "orofrog", "al": "en-US,en;q=0.8", "hh": "1.usa.gov", "r": "http:\\/\\/www.facebook.com\\/l\\/7AQEFzjSi\\/1.usa.gov\\/wfLQtf", "u": "http:\\/\\/www.ncbi.nlm.nih.gov\\/pubmed\\/22415991", "t": 1331923247, "hc": 1331822918, "cy": "Danvers", "ll": [ 42.576698, -70.954903 ] }\n' 我们通过json模块将JSON字符串转换为Python字典对象:
In [2]:
import json
records = [json.loads(line) for line in open(path)]
records[0]
Out[2]:
{u'a': u'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.78 Safari/535.11',
u'al': u'en-US,en;q=0.8',
u'c': u'US',
u'cy': u'Danvers',
u'g': u'A6qOVH',
u'gr': u'MA',
u'h': u'wfLQtf',
u'hc': 1331822918,
u'hh': u'1.usa.gov',
u'l': u'orofrog',
u'll': [42.576698, -70.954903],
u'nk': 1,
u'r': u'http://www.facebook.com/l/7AQEFzjSi/1.usa.gov/wfLQtf',
u't': 1331923247,
u'tz': u'America/New_York',
u'u': u'http://www.ncbi.nlm.nih.gov/pubmed/22415991'}
用纯Python代码对时区进行计数
假设我们想要知道该数据集中最常出现的是哪个时区(即tz字段),我们可以编写如下代码:
In [4]: time_zones = [rec['tz'] for rec in records if 'tz' in rec] time_zones[:10] Out[4]: [u'America/New_York', u'America/Denver', u'America/New_York', u'America/Sao_Paulo', u'America/New_York', u'America/New_York', u'Europe/Warsaw', u'', u'', u'']我们可以编写如下代码对数据进行计数:
def get_count(sequence):
counts = {}
for x in sequence:
if x in counts:
counts[x] += 1
else:
counts[x] = 1
return counts
def top_counts(count_dict, n = 10):
value_key_pairs = [(count, tz) for tz, count in count_dict.items()]
value_key_pairs.sort()
return value_key_pairs[-n:] 其中,get_count用来计数,而top_counts用来得到前10位的时区及计数值.
In [6]: counts = get_count(time_zones) counts['America/New_York'] Out[6]: 1251 In [7]: len(time_zones) Out[7]: 3440 In [8]: top_counts(counts) Out[8]: [(33, u'America/Sao_Paulo'), (35, u'Europe/Madrid'), (36, u'Pacific/Honolulu'), (37, u'Asia/Tokyo'), (74, u'Europe/London'), (191, u'America/Denver'), (382, u'America/Los_Angeles'), (400, u'America/Chicago'), (521, u''), (1251, u'America/New_York')]
用pandas对时区进行计数
DataFrame是pandas中最重要的数据结构,它用于将数据表示为一个表格.

如果我们想看时区的前十条数据,我们编写如下代码:
In [10]: frame['tz'][:10] Out[10]: 0 America/New_York 1 America/Denver 2 America/New_York 3 America/Sao_Paulo 4 America/New_York 5 America/New_York 6 Europe/Warsaw 7 8 9 Name: tz, dtype: object这里frame的输出形式是摘要视图,主要用于较大的DataFrame对象,我们可以使用Series的value_counts方法来统计计数:
In [11]:
tz_counts = frame['tz'].value_counts()
tz_counts[:10]
Out[11]:
America/New_York 1251
521
America/Chicago 400
America/Los_Angeles 382
America/Denver 191
Europe/London 74
Asia/Tokyo 37
Pacific/Honolulu 36
Europe/Madrid 35
America/Sao_Paulo 33
dtype: int64 然后,我们利用绘图库(matplotlib)为这段数据生成一张图片,所以我们得为未知或缺失的时区填上一个替代值.fillna函数可以替换缺失值(NA),然后再修改空字符串即可:
In [12]:
clean_tz = frame['tz'].fillna('Missing')
clean_tz[clean_tz == ''] = 'Unknown'
tz_counts = clean_tz.value_counts()
tz_counts[:10]
Out[12]:
America/New_York 1251
Unknown 521
America/Chicago 400
America/Los_Angeles 382
America/Denver 191
Missing 120
Europe/London 74
Asia/Tokyo 37
Pacific/Honolulu 36
Europe/Madrid 35
dtype: int64 我们使用plot方法即可得到一张水平条形图:

我们现在要处理字段"a"所包含的信息.我们先用列表表达式得到想要的数据:
In [26]: results = Series([x.split()[0] for x in frame.a.dropna()]) results[:5] Out[26]: 0 Mozilla/5.0 1 GoogleMaps/RochesterNY 2 Mozilla/4.0 3 Mozilla/5.0 4 Mozilla/5.0 dtype: object In [27]: results.value_counts()[:8] Out[27]: Mozilla/5.0 2594 Mozilla/4.0 601 GoogleMaps/RochesterNY 121 Opera/9.80 34 TEST_INTERNET_AGENT 24 GoogleProducer 21 Mozilla/6.0 5 BlackBerry8520/5.0.0.681 4 dtype: int64现在,我们想按照Windows和非Windows用户对时区统计信息进行分解,我们首先删除空数据,然后进行统计:
In [28]:
cframe = frame[frame.a.notnull()]
operating_system = np.where(cframe['a'].str.contains('Windows'), 'Windows', 'Not Windows')
operating_system[:5]
Out[28]:
array(['Windows', 'Not Windows', 'Windows', 'Not Windows', 'Windows'],
dtype='|S11') 接下来就可以根据时区和新得到的操作系统列表对数据进行分组,然后通过size进行计数,并通过unstack进行重新显示:

最后,我们来选取最常出现的时区.为了达到这个目的,我根据agg_counts中的行数构造了一个间接索引数组:
In [33]:
indexer = agg_counts.sum(1).argsort()
indexer[:10]
Out[33]:
tz
24
Africa/Cairo 20
Africa/Casablanca 21
Africa/Ceuta 92
Africa/Johannesburg 87
Africa/Lusaka 53
America/Anchorage 54
America/Argentina/Buenos_Aires 57
America/Argentina/Cordoba 26
America/Argentina/Mendoza 55
dtype: int64
备注:这段代码看不懂!
然后通过take按照这个顺序截取了最后10行:

我们可以生成如下的图:

2. MovieLens 1M数据集
MovieLens 1M数据集合含有来自6000名用户对4000部电影的100万条评分数据.它分为三个表:评分,用户信息和电影信息.将该数据从zip文件中解压出来之后,可以通过pandas.read_table将各个表分别读到一个pandas DataFrame对象中:
import pandas as pd path = '/Users/lgt/pydata-book/ch02/movielens/' unames = ['user_id', 'gender', 'age', 'occupation', 'zip'] users = pd.read_table(path + 'users.dat', sep='::', header=None, names=unames) rnames = ['user_id', 'movie_id', 'rating', 'timestamp'] ratings = pd.read_table(path + 'ratings.dat', sep='::', header=None, names=rnames) mnames = ['movie_id', 'title', 'genres'] movies = pd.read_table(path + 'movies.dat', sep='::', header=None, names=mnames)我们可以验证数据是否正确读取:
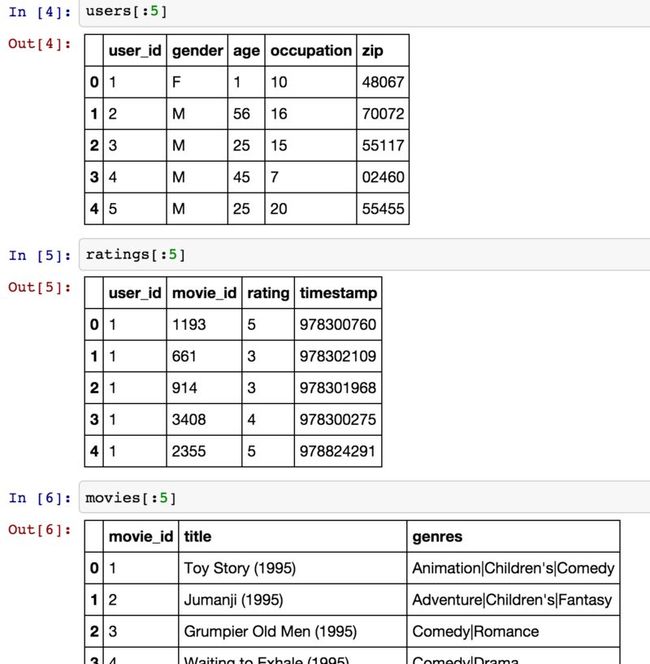
假设我们想要根据性别和年龄计算某部电影的平均得分,如果将所有数据都合并到一个表中的话问题就简单多了.

为了按性别计算每部电影的平均得分,我们可以使用pivot_table方法:

该操作产生了另一个DataFrame,其内容为电影平均分,行标为电影名称,列标为性别.现在我们打算过滤评分不够250条的电影:
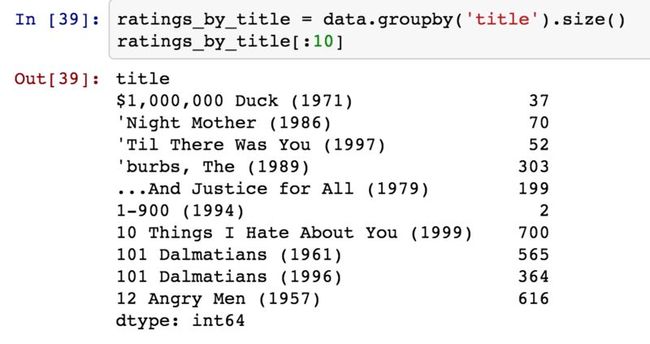
我们通过比较来得出评分数据大于250条的电影:

我们可以按F列进行降序排列来了解女性观众喜欢的电影:

计算评分分歧
假设我们想要找到男性和女性观众分歧最大的电影,一个办法是给mean_ratings加上一个用于存放平均分之差的列,并对其进行排序:

以上是分歧最大且女性观众更喜欢的电影,我们进行反排序即得到男性喜欢的电影:

如果只是想要找出分歧最大的电影,则可以计算得分数据的方差或标准差:
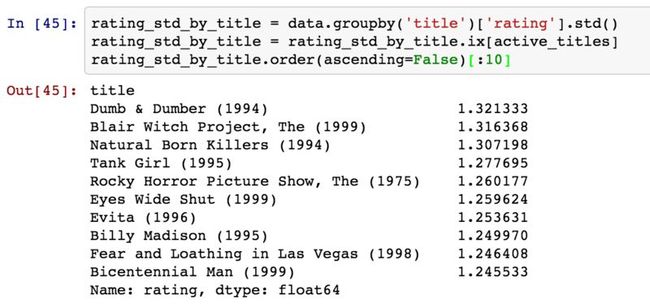
3. 1880--2010年间全美婴儿姓名
SSA提供了从1880-2010年全美婴儿姓名.由于每个txt数据文件都以非常标准的逗号分隔,则我们可以用pandas.read_csv将其加载到DataFrame中:

这些文件中仅含有当年出现超过5次的名字.我们可以统计该年度总的出生人数:
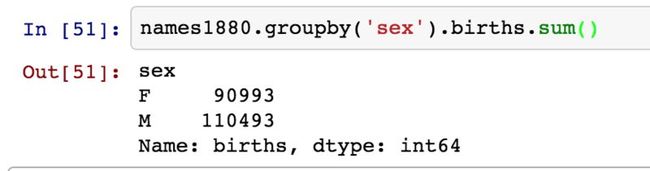
由于该数据集按年度分割成多个文件,我们可以把它们汇总起来:
years = range(1880, 2011)
pieces = []
columns = ['name', 'sex', 'births']
path = '/Users/lgt/pydata-book/ch02/names/'
for year in years:
filePath = path + 'yob%d.txt' % year
frame = pd.read_csv(filePath, names=columns)
frame['year'] = year
pieces.append(frame)
names = pd.concat(pieces, ignore_index=True) 这里需要注意几件事情:1.concat默认是按行将多个DataFrame组合到一起的.2.必须制定ingore_index=True,因为我们不希望保留read_csv所返回的原始行号.
我们可以因此简单的计算出美国从1880--2010总共出生的人数:

有了这些数据后,我们可以利用groupby或pivot_table在year和sex级别上对其进行聚合了:
我们来画出:性别和年度统计的总出生数
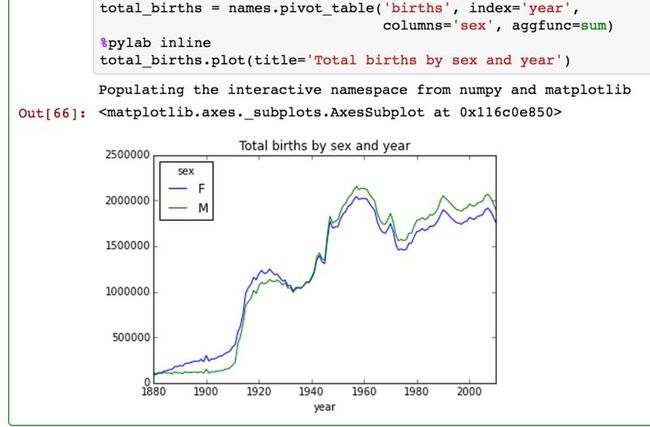
下面我们来插入一个prop列,用于存放指定名字的婴儿数相对于总出生数的比例.prop值为0.02代表100名婴儿中又2名取了当前的名字.因此,我们先按year和sex分组,然后再将新列加到各个分组上:
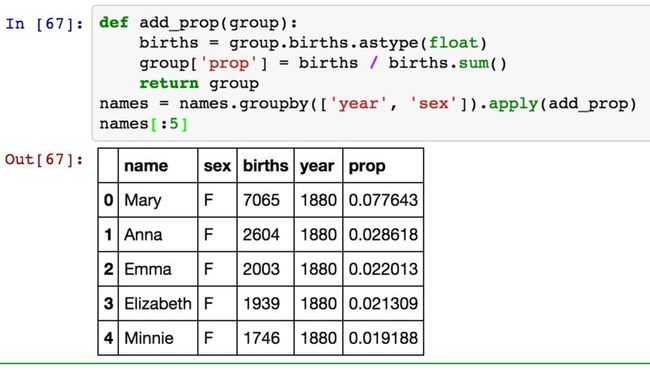
在执行这样的分组时,一般都应该进行一些有效性的检查,例如所有的prop的总和为1.因为是浮点型数据,所以我们使用np.allclose来检查这个分组是否足够接近1:
In [68]: np.allclose(names.groupby(['year', 'sex']).prop.sum(), 1) Out[68]: True现在我们取出sex/year组合的前1000个名字:
def get_top1000(group):
return group.sort_index(by='births', ascending=False)[:1000]
grouped = names.groupby(['year', 'sex'])
top1000 = grouped.apply(get_top1000)
分析命名趋势
我们首先将前1000个名字分为男女两部分:
boys = top1000[top1000.sex == 'M']
girls = top1000[top1000.sex == 'F']
total_births= top1000.pivot_table('births', index='year', columns='name', aggfunc=sum) 然后我们分析几个名字的曲线图:

从图中可以看出这四个名字在美国已经失宠,但事实并非如此.
评估命名多样性的增长
上图所反映出的情况有可能是父母愿意给小孩起常见的名字越来越少,这个假设可以从数据中得到验证,一个办法是计算最流行的1000各名字所占用的比例:

从图中可以看出,名字的多样性确实出现了增长.另一个方法是计算占总出生人数前50%的不同名字的数量,我们只考虑2010年男孩的名字:
In [79]:
df = boys[boys.year==2010]
prop_cumsum = df.sort_index(by='prop', ascending=False).prop.cumsum()
prop_cumsum[:10]
Out[79]:
year sex
2010 M 1676644 0.011523
1676645 0.020934
1676646 0.029959
1676647 0.038930
1676648 0.047817
1676649 0.056579
1676650 0.065155
1676651 0.073414
1676652 0.081528
1676653 0.089621
Name: prop, dtype: float64 我们先计算prop的累计和cumsum,然后再通过search sorted方法找出0.5应该被插入在哪个位置才能保证不破坏顺序:
In [80]: prop_cumsum.searchsorted(0.5) Out[80]: array([116])我们以1900年做比较:
In [81]: df = boys[boys.year==1900] prop_cumsum = df.sort_index(by='prop', ascending=False).prop.cumsum() prop_cumsum.searchsorted(0.5) Out[81]: array([24])现在就可以对所有的year/sex组合执行这个计算了:
def get_quantile_count(group, q=0.5):
group = group.sort_index(by='prop', ascending=False)
return group.prop.cumsum().searchsorted(q) + 1
diversity = top1000.groupby(['year','sex']).apply(get_quantile_count)
diversity = diversity.unstack('sex')
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
%pylab inline
diversity.plot(title='Number of popular names in top 50%') 但是报错了...说存在空白数据导致plot无法绘制......
'最后一个字母'的变革
为了研究这个变革,我们首先将全部出生数据在年度,性别以及末字母上进行了聚合:
get_last_letter = lambda x: x[-1]
last_letters = names.name.map(get_last_letter)
last_letters.name = 'last_letter'
table = names.pivot_table('births', index=last_letters,
columns=['sex', 'year'], aggfunc=sum)
我们选出具有代表性的三年:
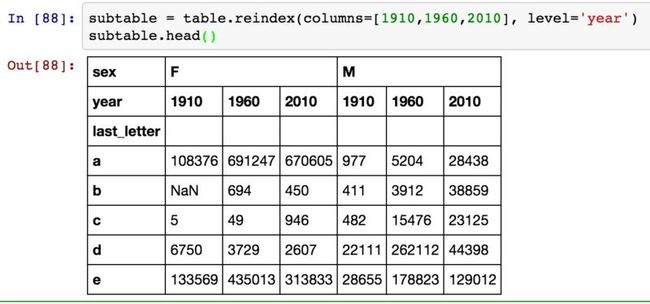
接下来我们需要按总出生数对该表进行规范化处理,以便计算出各性别各末字母占总出生人数的比例:

我们选取几个字母进行查看趋势:
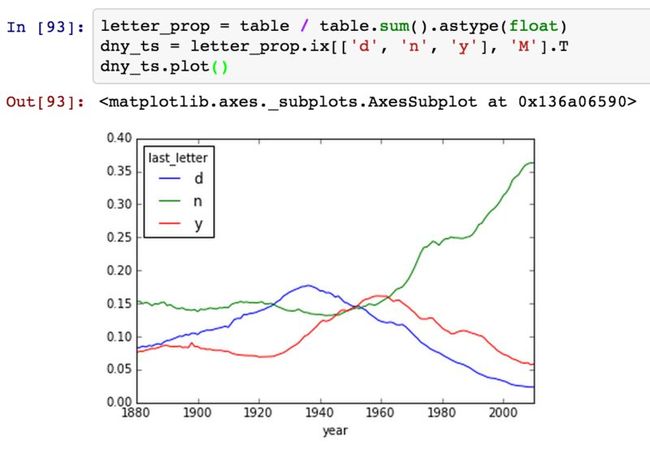
变成女孩名字的男孩名字(以及相反的情况)
例如流行于男孩的名字慢慢变成了女孩的名字,我们以lesl为例:
all_names = top1000.name.unique() mask = np.array(['lesl' in x.lower() for x in all_names]) lesley_like = all_names[mask]我们先进行过滤操作:

然后进行聚合绘制操作:
