Java序列化(Serializable)与反序列化
序列化是干什么的
简单说就是为了保存在内存中的各种对象的状态(也就是实例变量,不是方法),并且可以把保存的对象状态再读出来。虽然你可以用你自己的各种各样的方法来保 存object states,但是Java给你提供一种应该比你自己好的保存对象状态的机制,那就是序列化。
什么情况下需要序列化
- 当你想把的内存中的对象状态保存到一个文件中或者数据库中时候;
- 当你想用套接字在网络上传送对象的时候;
- 当你想通过RMI传输对象的时候;
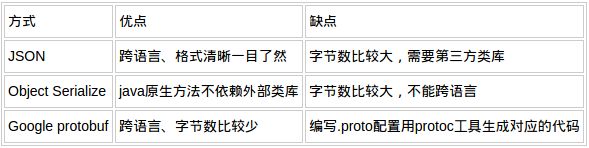
序列化的几种方式
在Java中socket传输数据时,数据类型往往比较难选择。可能要考虑带宽、跨语言、版本的兼容等问题。比较常见的做法有两种:一是把对象包装成JSON字符串传输,二是采用java对象的序列化和反序列化。随着Google工具protoBuf的开源,protobuf也是个不错的选择。对JSON,Object Serialize,ProtoBuf 做个对比。
Object Serialize
public interface Serializable类通过实现 java.io.Serializable 接口以启用其序列化功能。未实现此接口的类将无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。序列化接口没有方法或字段,仅用于标识可序列化的语义。
要允许不可序列化类的子类型序列化,可以假定该子类型负责保存和还原超类型的公用 (public)、受保护的 (protected) 和(如果可访问)包 (package) 字段的状态。仅在子类型扩展的类(父类)有一个可访问的无参数构造方法来初始化该类的状态时,才可以假定子类型有此责任。如果不是这种情况,则声明一个类为可序列化类是错误的。该错误将在运行时检测到。
在反序列化过程中,将使用该类的公用或受保护的无参数构造方法初始化不可序列化类的字段。可序列化的子类必须能够访问无参数的构造方法。可序列化子类的字段将从该流中还原。
Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。
serialVersionUID 用来表明类的不同版本间的兼容性。有两种生成方式:
- 一个是默认的1L,比如:private static final long serialVersionUID = 1L;
- 一个是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段,比如: private static final long serialVersionUID = xxxxL;
下面来讨论Java类中为什么需要重载 serialVersionUID 属性?
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
- 把Java对象转换为字节序列的过程称为对象的序列化。
- 把字节序列恢复为Java对象的过程称为对象的反序列化。
对象的序列化主要有两种用途:(1)把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中; (2)在网络上传送对象的字节序列;
java.io.ObjectOutputStream代表对象输出流,它的writeObject(Object obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
java.io.ObjectInputStream代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
只有实现了Serializable和Externalizable接口的类的对象才能被序列化。Externalizable接口继承自Serializable接口,实现Externalizable接口的类完全由自身来控制序列化的行为,而仅实现Serializable接口的类可以采用默认的序列化方式 。
凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量:private static final long serialVersionUID;
序列化运行时使用一个称为 serialVersionUID 的版本号与每个可序列化类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。如果接收者加载的该对象的类的 serialVersionUID 与对应的发送者的类的版本号不同,则反序列化将会导致 InvalidClassException。可序列化类可以通过声明名为serialVersionUID的字段(该字段必须是静态 (static)、最终 (final) 的 long 型字段)显式声明其自己的 serialVersionUID:
ANY-ACCESS-MODIFIER static final long serialVersionUID = 42L;
如果可序列化类未显式声明 serialVersionUID,则序列化运行时将基于该类的各个方面计算该类的默认 serialVersionUID 值,如“Java™ 对象序列化规范”中所述。不过,强烈建议 所有可序列化类都显式声明 serialVersionUID 值,原因是计算默认的 serialVersionUID 对类的详细信息具有较高的敏感性,根据编译器实现的不同可能千差万别,这样在反序列化过程中可能会导致意外的 InvalidClassException。因此,为保证 serialVersionUID 值跨不同 java 编译器实现的一致性,序列化类必须声明一个明确的 serialVersionUID 值。还强烈建议使用 private 修饰符显示声明 serialVersionUID(如果可能),原因是这种声明仅应用于直接声明类 – serialVersionUID 字段作为继承成员没有用处。数组类不能声明一个明确的 serialVersionUID,因此它们总是具有默认的计算值,但是数组类没有匹配 serialVersionUID 值的要求。
类的serialVersionUID的默认值完全依赖于Java编译器的实现,对于同一个类,用不同的Java编译器编译,有可能会导致不同的serialVersionUID,也有可能相同。为了提高serialVersionUID的独立性和确定性,强烈建议在一个可序列化类中显示的定义serialVersionUID,为它赋予明确的值。显式地定义serialVersionUID有两种用途:
- 在某些场合,希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有相同的serialVersionUID;在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的serialVersionUID。
- 当你序列化了一个类实例后,希望更改一个字段或添加一个字段,不设置serialVersionUID,所做的任何更改都将导致无法反序化旧有实例,并在反序列化时抛出一个异常。如果你添加了serialVersionUID,在反序列旧有实例时,新添加或更改的字段值将设为初始化值(对象为null,基本类型为相应的初始默认值),字段被删除将不设置。
相关注意事项:
a)序列化时,只对对象的状态进行保存,而不管对象的方法;
b)当一个父类实现序列化,子类自动实现序列化,不需要显式实现Serializable接口;
c)当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化;
详细描述:
序列化的过程就是对象写入字节流和从字节流中读取对象。将对象状态转换成字节流之后,可以用java.io包中的各种字节流类将其保存到文件中,管道到另一 线程中或通过网络连接将对象数据发送到另一主机。对象序列化功能非常简单、强大,在RMI、Socket、JMS、EJB都有应用。对象序列化问题在网络 编程中并不是最激动人心的课题,但却相当重要,具有许多实用意义。
- 对象序列化可以实现分布式对象。主要应用例如:RMI要利用对象序列化运行远程主机上的服务,就像在本地机上运行对象时一样。
- java 对象序列化不仅保留一个对象的数据,而且递归保存对象引用的每个对象的数据。可以将整个对象层次写入字节流中,可以保存在文件中或在网络连接上传递。利用 对象序列化可以进行对象的“深复制”,即复制对象本身及引用的对象本身。序列化一个对象可能得到整个对象序列。
从上面的叙述中,我们知道了对象序列化是java编程中的必备武器,那么让我们从基础开始,好好学习一下它的机制和用法。
java序列化比较简单,通常不需要编写保存和恢复对象状态的定制代码。实现java.io.Serializable接口的类对象可以转换成字节流或从 字节流恢复,不需要在类中增加任何代码。只有极少数情况下才需要定制代码保存或恢复对象状态。这里要注意:不是每个类都可序列化,有些类是不能序列化的, 例如涉及线程的类与特定JVM有非常复杂的关系。
序列化机制:
序列化分为两大部分:序列化和反序列化。序列化是这个过程的第一部分,将数据分解成字节流,以便存储在文件中或在网络上传输。反序列化就是打开字节流并重构对象。对象序列化不仅要将基本数据类型转换成字节 表示,有时还要恢复数据。恢复数据要求有恢复数据的对象实例。ObjectOutputStream中的序列化过程与字节流连接,包括对象类型和版本信 息。反序列化时,JVM用头信息生成对象实例,然后将对象字节流中的数据复制到对象数据成员中。
处理对象流:序列化过程和反序列化过程
java.io包有两个序列化对象的类。ObjectOutputStream负责将对象写入字节流,ObjectInputStream从字节流重构对象。
我们先了解ObjectOutputStream类吧。ObjectOutputStream类扩展DataOutput接口。writeObject() 方法是最重要的方法,用于对象序列化。如果对象包含其他对象的引用,则writeObject()方法递归序列化这些对象。每个 ObjectOutputStream维护序列化的对象引用表,防止发送同一对象的多个拷贝。(这点很重要)由于writeObject()可以序列化整 组交叉引用的对象,因此同一ObjectOutputStream实例可能不小心被请求序列化同一对象。这时,进行反引用序列化,而不是再次写入对象字节流。
// 序列化 today’s date 到一个文件中.
FileOutputStream f = new FileOutputStream(“tmp”); //创建一个包含恢复对象(即对象进行反序列化信息)的”tmp”数据文件
ObjectOutputStream s = new ObjectOutputStream(f);
s.writeObject(“Today”); //写入字符串对象;
s.writeObject(new Date()); //写入瞬态对象;
s.flush();
现在,让我们来了解ObjectInputStream这个类。它与ObjectOutputStream相似。它扩展DataInput接口。 ObjectInputStream中的方法镜像DataInputStream中读取Java基本数据类型的公开方法。readObject()方法从 字节流中反序列化对象。每次调用readObject()方法都返回流中下一个Object。对象字节流并不传输类的字节码,而是包括类名及其签名。 readObject()收到对象时,JVM装入头中指定的类。如果找不到这个类,则readObject()抛出 ClassNotFoundException,如果需要传输对象数据和字节码,则可以用RMI框架。ObjectInputStream的其余方法用于定制反序列化过程。
//从文件中反序列化 string 对象和 date 对象
FileInputStream in = new FileInputStream(“tmp”);
ObjectInputStream s = new ObjectInputStream(in);
String today = (String)s.readObject(); //恢复对象;
Date date = (Date)s.readObject();
定制序列化过程:
序列化通常可以自动完成,但有时可能要对这个过程进行控制。java可以将类声明为serializable,但仍可手工控制声明为static或transient的数据成员。
public class SimpleSerializableClass implements Serializable{
String sToday=”Today:”;
transient Date dtToday=new Date();
}
序列化时,类的所有数据成员应可序列化除了声明为transient或static的成员。将变量声明为transient告诉JVM我们会负责将变元序列 化。将数据成员声明为transient后,序列化过程就无法将其加进对象字节流中,没有从transient数据成员发送的数据。后面数据反序列化时, 要重建数据成员(因为它是类定义的一部分),但不包含任何数据,因为这个数据成员不向流中写入任何数据。记住,对象流不序列化static或 transient。我们的类要用writeObject()与readObject()方法以处理这些数据成员。使用writeObject()与 readObject()方法时,还要注意按写入的顺序读取这些数据成员。
//重写writeObject()方法以便处理transient的成员。
public void writeObject(ObjectOutputStream outputStream) throws IOException{
outputStream.defaultWriteObject();//使定制的writeObject()方法可以利用自动序列化中内置的逻辑。
outputStream.writeObject(oSocket.getInetAddress());
outputStream.writeInt(oSocket.getPort());
}
//重写readObject()方法以便接收transient的成员。
private void readObject(ObjectInputStream inputStream) throws IOException,ClassNotFoundException{
inputStream.defaultReadObject();//defaultReadObject()补充自动序列化
InetAddress oAddress=(InetAddress)inputStream.readObject();
int iPort =inputStream.readInt();
oSocket = new Socket(oAddress,iPort);
iID=getID();
dtToday =new Date();
}
完全定制序列化过程:
如果一个类要完全负责自己的序列化,则实现Externalizable接口而不是Serializable接口。Externalizable接口定义包 括两个方法writeExternal()与readExternal()。利用这些方法可以控制对象数据成员如何写入字节流.类实现 Externalizable时,头写入对象流中,然后类完全负责序列化和恢复数据成员,除了头以外,根本没有自动序列化。这里要注意了。声明类实现 Externalizable接口会有重大的安全风险。writeExternal()与readExternal()方法声明为public,恶意类可 以用这些方法读取和写入对象数据。如果对象包含敏感信息,则要格外小心。这包括使用安全套接或加密整个字节流。到此为至,我们学习了序列化的基础部分知识。
以下来源于J2EE API:
对象的默认序列化机制写入的内容是:对象的类,类签名,以及非瞬态和非静态字段的值。其他对象的引用(瞬态和静态字段除外)也会导致写入那些对象。可使用引用共享机制对单个对象的多个引用进行编码,这样即可将对象的图形还原为最初写入它们时的形状。
例如,要写入可通过 ObjectInputStream 中的示例读取的对象,请执行以下操作:
FileOutputStream fos = new FileOutputStream(“t.tmp”);
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeInt(12345);
oos.writeObject(“Today”);
oos.writeObject(new Date());
oos.close();
在序列化和反序列化过程中需要特殊处理的类必须实现具有下列准确签名的特殊方法:
private void writeObject(java.io.ObjectOutputStream stream) throws IOException;
writeObject 方法负责写入特定类的对象状态,以便相应的 readObject 方法可以还原它。该方法本身不必与属于对象的超类或子类的状态有关。状态是通过使用 writeObject 方法或使用 DataOutput 支持的用于基本数据类型的方法将各个字段写入 ObjectOutputStream 来保存的。
private void readObject(java.io.ObjectInputStream stream) throws IOException, ClassNotFoundException;
readObject 方法负责从流中读取并还原类字段。它可以调用 in.defaultReadObject 来调用默认机制,以还原对象的非静态和非瞬态字段。defaultReadObject 方法使用流中的信息来分配流中通过当前对象中相应命名字段保存的对象的字段。这用于处理类发展后需要添加新字段的情形。
序列化操作不写出没有实现 java.io.Serializable 接口的任何对象的字段。不可序列化的 Object 的子类可以是可序列化的。在此情况下,不可序列化的类必须有一个无参数构造方法,以便允许初始化其字段。在此情况下,子类负责保存和还原不可序列化的类的 状态。经常出现的情况是,该类的字段是可访问的(public、package 或 protected),或者存在可用来还原状态的 get 和 set 方法。
实现 writeObject 和 readObject 方法可以阻止对象的序列化,这时抛出 NotSerializableException。ObjectOutputStream 导致发生异常并中止序列化进程。
实现 Externalizable 接口允许对象假定可以完全控制对象的序列化形式的内容和格式。调用 Externalizable 接口的方法(writeExternal 和 readExternal)来保存和恢复对象的状态。通过类实现时,它们可以使用 ObjectOutput 和 ObjectInput 的所有方法读写它们自己的状态。对象负责处理出现的任何版本控制。
Enum 常量的序列化不同于普通的 serializable 或 externalizable 对象。enum 常量的序列化形式只包含其名称;常量的字段值不被传送。为了序列化 enum 常量,ObjectOutputStream 需要写入由常量的名称方法返回的字符串。与其他 serializable 或 externalizable 对象一样,enum 常量可以作为序列化流中后续出现的 back 引用的目标。用于序列化 enum 常量的进程不可定制;在序列化期间,由 enum 类型定义的所有类特定的 writeObject 和 writeReplace 方法都将被忽略。类似地,任何 serialPersistentFields 或 serialVersionUID 字段声明也将被忽略,所有 enum 类型都有一个 0L 的固定的 serialVersionUID。
基本数据(不包括 serializable 字段和 externalizable 数据)以块数据记录的形式写入 ObjectOutputStream 中。块数据记录由头部和数据组成。块数据部分包括标记和跟在部分后面的字节数。连续的基本写入数据被合并在一个块数据记录中。块数据记录的分块因子为 1024 字节。每个块数据记录都将填满 1024 字节,或者在终止块数据模式时被写入。调用 ObjectOutputStream 方法 writeObject、defaultWriteObject 和 writeFields 最初只是终止所有现有块数据记录。
将对象写入流时需要指定要使用的替代对象的可序列化类,应使用准确的签名来实现此特殊方法:
ANY-ACCESS-MODIFIER Object writeReplace() throws ObjectStreamException;
此 writeReplace 方法将由序列化调用,前提是如果此方法存在,而且它可以通过被序列化对象的类中定义的一个方法访问。因此,该方法可以拥有私有 (private)、受保护的 (protected) 和包私有 (package-private) 访问。子类对此方法的访问遵循 java 访问规则。
在从流中读取类的一个实例时需要指定替代的类应使用的准确签名来实现此特殊方法。
ANY-ACCESS-MODIFIER Object readResolve() throws ObjectStreamException;
此 readResolve 方法遵循与 writeReplace 相同的调用规则和访问规则。
序列化类的所有子类本身都是可序列化的。这个序列化接口没有任何方法和域,仅用于标识序列化的语意。允许非序列化类的子类型序列化,子类型可以假定负责保存和恢复父类型的公有的、保护的和(如果可访问)包的域的状态。只要该类(即父类)有一个无参构造子,可初始化它的状态,那么子类型就可承担上述职责;如果该类没有无参构造函数,在这种情况下申明一个可序列化的类是一个错误。此错误将在运行时被检测。
JSON化
UserVo src = new UserVo();
src.setName("Yaoming");
src.setAge(30);
src.setPhone(13789878978L);
UserVo f1 = new UserVo();
f1.setName("tmac");
f1.setAge(32);
f1.setPhone(138999898989L);
UserVo f2 = new UserVo();
f2.setName("liuwei");
f2.setAge(29);
f2.setPhone(138999899989L);
List<UserVo> friends = new ArrayList<UserVo>();
friends.add(f1);
friends.add(f2);
src.setFriends(friends);
// 采用Google的gson-2.2.2.jar 进行转义:
Gson gson = new Gson();
String json = gson.toJson(src);
得到的字符串:(字节数为153)
{“name”:“Yaoming”,“age”:30,“phone”:13789878978,“friends”:[{“name”:“tmac”,“age”:32,“phone”:138999898989},{“name”:“liuwei”,“age”:29,“phone”:138999899989}]}
Json的优点:明文结构一目了然,可以跨语言,属性的增加减少对解析端影响较小。缺点:字节数过多,依赖于不同的第三方类库。
Google ProtoBuf
protocol buffers 是google内部得一种传输协议,目前项目已经开源(http://code.google.com/p/protobuf/)。它定义了一种紧凑得可扩展得二进制协议格式,适合网络传输,并且针对多个语言有不同得版本可供选择。
以protobuf-2.5.0rc1为例,准备工作:
下载源码,解压,编译,安装:
tar zxvf protobuf-2.5.0rc1.tar.gz
./configure
./make
./make install
测试:
MacBook-Air:~ ming$ protoc --version
libprotoc 2.5.0
安装成功!进入源码得java目录,用mvn工具编译生成所需得jar包,protobuf-java-2.5.0rc1.jar
(1)编写.proto文件,命名UserVo.proto:
package serialize;
option java_package = "serialize";
option java_outer_classname="UserVoProtos";
message UserVo{
optional string name = 1;
optional int32 age = 2;
optional int64 phone = 3;
repeated serialize.UserVo friends = 4;
}
(2)在命令行利用protoc 工具生成builder类:
protoc -IPATH=.proto文件所在得目录 --java_out=java文件的输出路径 .proto的名称
(3)编写序列化代码:
UserVoProtos.UserVo.Builder builder = UserVoProtos.UserVo.newBuilder();
builder.setName("Yaoming");
builder.setAge(30);
builder.setPhone(13789878978L);
UserVoProtos.UserVo.Builder builder1 = UserVoProtos.UserVo.newBuilder();
builder1.setName("tmac");
builder1.setAge(32);
builder1.setPhone(138999898989L);
UserVoProtos.UserVo.Builder builder2 = UserVoProtos.UserVo.newBuilder();
builder2.setName("liuwei");
builder2.setAge(29);
builder2.setPhone(138999899989L);
builder.addFriends(builder1);
builder.addFriends(builder2);
UserVoProtos.UserVo vo = builder.build();
byte[] v = vo.toByteArray();
字节数为53
(4)反序列化:
UserVoProtos.UserVo uvo = UserVoProtos.UserVo.parseFrom(dstb);
System.out.println(uvo.getFriends(0).getName());
google protobuf 优点:字节数很小,适合网络传输节省io,跨语言 。缺点:需要依赖于工具生成代码。
工作机制
proto文件是对数据的一个描述,包括字段名称,类型,字节中的位置。protoc工具读取proto文件生成对应builder代码的类库。protoc xxxxx –java_out=xxxxxx 生成java类库。builder类根据自己的算法把数据序列化成字节流,或者把字节流根据反射的原理反序列化成对象。
官方的示例:https://developers.google.com/protocol-buffers/docs/javatutorial。
proto文件中的字段类型和java中的对应关系: 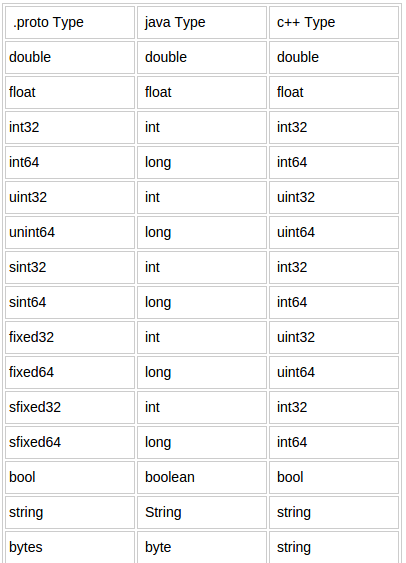
protobuf 在序列化和反序列化的时候,是依赖于.proto文件生成的builder类完成,字段的变化如果不表现在.proto文件中就不会影响反序列化,比较适合字段变化的情况。做个测试:
把UserVo序列化到文件中:
UserVoProtos.UserVo vo = builder.build();
byte[] v = vo.toByteArray();
FileOutputStream fos = new FileOutputStream(dataFile);
fos.write(vo.toByteArray());
fos.close();
为UserVo增加字段,对应的.proto文件:
package serialize;
option java_package = "serialize";
option java_outer_classname="UserVoProtos";
message UserVo{
optional string name = 1;
optional int32 age = 2;
optional int64 phone = 3;
repeated serialize.UserVo friends = 4;
optional string address = 5;
}
从文件中反序列化回来:
FileInputStream fis = new FileInputStream(dataFile);
byte[] dstb = new byte[fis.available()];
for(int i=0;i<dstb.length;i++){
dstb[i] = (byte)fis.read();
}
fis.close();
UserVoProtos.UserVo uvo = UserVoProtos.UserVo.parseFrom(dstb);
System.out.println(uvo.getFriends(0).getName());
三种方式对比传输同样的数据,google protobuf只有53个字节是最少的。结论: