RingBuffer的特别之处_disruptor
RingBuffer的特别之处_disruptor
为什么要说RingBuffer?
Although reactor it is part of the foundation of the Spring IO platform, the core Reactor libraries have no dependency on Spring. Reactor core is a self-contained library whose only external dependencies are SLF4J and the fantastic(极好的) LMAX Disruptor RingBuffer library.
Built on Reactor’s core are other, optional components to facilitate developing applications against common patterns. Some of Reactor’s built-in, first-class support includes:
LMAX Disruptor support via the high-speed Processor abstraction, which provides a Reactor API over the RingBuffer.
以下转自:http://ifeve.com/dissecting-disruptor-whats-so-special/
首先介绍RingBuffer。我对Disruptor的最初印象就是RingBuffer。但是后来我意识到尽管ringbuffer是整个模式(Disruptor)的核心,但是Disruptor对ringbuffer的访问控制策略才是真正的关键点所在。
RingBuffer到底是什么?
嗯,正如名字所说的一样,它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的buffer。
(好吧,这是我通过画图板手画的,我试着画草图,希望我的强迫症不会让我画完美的圆和直线)
基本来说,ringbuffer拥有一个序号,这个序号指向数组中下一个可用的元素。
(校对注:如下图右边的图片表示序号,这个序号指向数组的索引4的位置。)
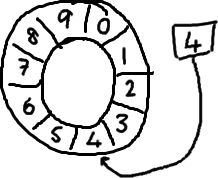
随着你不停地填充这个buffer(可能也会有相应的读取),这个序号会一直增长,直到绕过这个环。
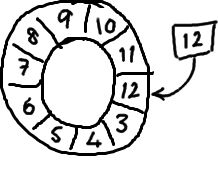
要找到数组中当前序号指向的元素,可以通过mod操作:
sequence mod array length = array index
以上面的ringbuffer为例(java的mod语法):12 % 10 = 2。很简单吧。
事实上,上图中的ringbuffer只有10个槽完全是个意外。如果槽的个数是2的N次方更有利于基于二进制的计算机进行计算。
那又怎么样?
如果你看了维基百科里面的关于环形buffer的词条,你就会发现,我们的实现方式,与其最大的区别在于:没有尾指针。我们只维护了一个指向下一个可用位置的序号。这种实现是经过深思熟虑的—我们选择用环形buffer的最初原因就是想要提供可靠的消息传递。我们需要将已经被服务发送过的消息保存起来,这样当另外一个服务通过nak (校对注:拒绝应答信号)告诉我们没有成功收到消息时,我们能够重新发送给他们。
听起来,环形buffer(或者说循环队列)非常适合这个场景。它维护了一个指向尾部的序号,当收到nak(校对注:拒绝应答信号)请求,可以重发从那一点到当前序号之间的所有消息:
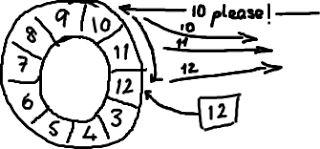
我们实现的ring buffer和大家常用的队列之间的区别是,我们不删除buffer中的数据,也就是说这些数据一直存放在buffer中,直到新的数据覆盖他们。这就是和维基百科版本相比,我们不需要尾指针的原因。ringbuffer本身并不控制是否需要重叠(决定是否重叠是生产者-消费者行为模式的一部分–如果你等不急我写blog来说明它们,那么可以自行检出Disruptor项目)。
它为什么如此优秀?
之所以ringbuffer采用这种数据结构,是因为它在可靠消息传递方面有很好的性能。这就够了,不过它还有一些其他的优点。
首先,因为它是数组,所以要比链表快,而且有一个容易预测的访问模式。(译者注:数组内元素的内存地址的连续性存储的)。这是对CPU缓存友好的—也就是说,在硬件级别,数组中的元素是会被预加载的,因此在ringbuffer当中,cpu无需时不时去主存加载数组中的下一个元素。
其次,你可以为数组预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。
缺少的部分
我并没有在本文中介绍如何避免ringbuffer产生重叠,以及如何对ringbuffer进行读写操作。你可能注意到了我将ringbuffer和链表那样的数据结构进行比较,因为我并认为链表是实际问题的标准答案。
当你将Disruptor和基于队列之类的实现进行比较时,事情将变得很有趣。队列通常注重维护队列的头尾元素,添加和删除元素等。所有的这些我都没有在ringbuffer里提到,这是因为ringbuffer不负责这些事情,我们把这些操作都移到了数据结构(ringbuffer)的外部
=================END=================