日志分析(一)框架选择
概要
日志分析,有两个主要模块日志收集以及分析统计。日志收集主要实现日志数据源的获取。分析统计是对数据源的聚合和统计分析。
日志收集又分为离线收集和热数据收集:离线收集的日志收集服务器与日志分析系统完全隔离,服务器日志以文本的格式输出到指定文件,然后通过logstash或者flume等文本收集系统进行传输,从而形成对应的日志数据源。
分析统计主要根据日志的数据源新进聚合和处理,聚合的过程主要是分布式日志的数据聚拢,因为聚拢的策略一般是遵循fifo准则和fcfs算法,保证时间优先进行日志聚合。因为目前日志分析在一定程度上要求实时性,对日志数据源的处理,又多了些预处理、流计算等模式进行数据的实时处理运算,以实现日志数据最终存储或者内存的格式即查询或者图形化展示需要的内容。
热门应用的介绍
1、logstash
elk 是logstash,elasticsearch,kibana 的缩写,这个架构组合非常适合做日志分析,其就是离线式日志实时分析的代表,而且有目前已知的最强大的社区支持。logstash shipper利用file input读取日志文件,filter组件进行正则日志筛选,然后通过 broker 进行聚合,日志通过es out已有的组件输出到 elasticsearch。kibana根据elasticsearch的索引进行实时查询。成功案例参照 新浪 、芒果TV等,github上有4000+ stars,它好在有一套完整的日志收集(logstash)、日志存储(elasticsearch)、日志展示分析(kibana),搭建起来非常方便。
详细介绍:http://kibana.logstash.es/content/index.html

logstash可以多线程共享 SizedQueue、java协议写ES等等优点就不罗列了,其缺点大概有以下:logstash 的一系列问题,比如Input/syslog性能极差,Filter/geoip性能较差,Filter/grok费CPU,Output/elasticsearch的retry逻辑跟stud的SizedQueue重复等等。针对版本可以做相应代码优化以实现版本问题。
ps www.elastic.co的一句 :If a newbie has a bad time, it's a bug.
2、flume
flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。类似的有。
官网:http://flume.apache.org/
简介:http://my.oschina.net/u/2284716/blog/542991
3、kafka
kafka数据处理管道。
原文:http://kafka.apache.org/design.html
翻译的:http://www.oschina.net/translate/kafka-design?lang=chs&page=1
4、druid
druid 是实时试探性查询的分析数据存储工具,可以理解成一种数据缓存化的聚合存储,为olap而生。
以下是针对druid和目前较多 数据存储工具的对比:
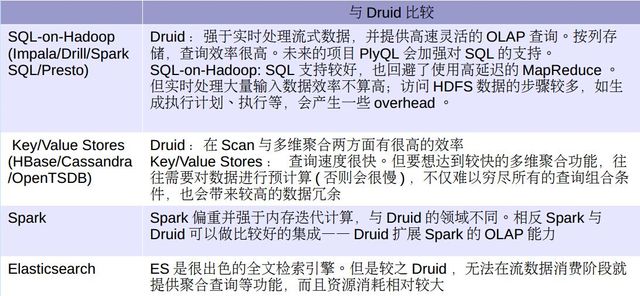
以下 是druid 的架构模型:
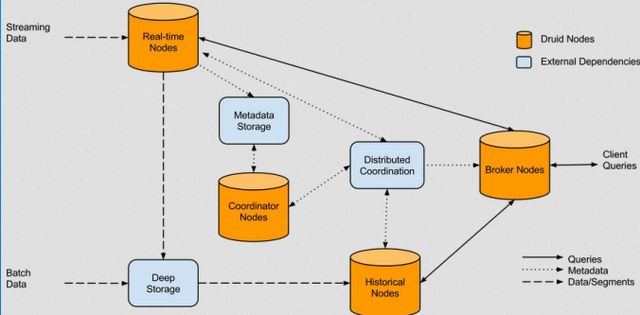
只说两个缺点:硬件要求,以及 本身即是数据的聚合结果存储需要对源数据进行额外存储。
原文 :http://druid.io/docs/0.8.2/design/index.html
5、es
elasticsearch搜索引擎,基于lucene,分布式,RESTful搜索引擎, 比solr在实时数据方面有优势。kibana 提供了数据前端展示。
缺点:没有事务概念,针对单个document最好采用单一实例操作。
官网:http://www.elastic.co
olap的暂时了解了以上开源框架,elk、flume+管道(redis或kafka)+es+kibana 、flume / logstash /rsync+ kafka+Hadoop+druid 等组合。
but,however,以上所有的olap的日志分析都要很大的主机(以上组合最少也要3个实例进程,或者需要大量内存空间)成本...我现在告诉大家一种省钱的架构组合,成本更低,效率有一定的优势。
jvm agent+kafka+es +kibana ~~
官网:http://my.oschina.net/u/2284716/blog/544201