Configuration
default built-in settings+3种配置方法: 修改配置后续重启生效,配置文件可以create/edit
1)environment variables:配置端口ports,配置文件路径filelocations,服务名称NODENAME.(override the defaults built in to the RabbitMQ startup scripts,taken from the shell, 可以配置在/etc/rabbitmq/rabbitmq-env.conf文件里)。
RabbitMQ environment variable names have the prefix RABBITMQ_. A typical variable calledRABBITMQ_var_name is set as follows:
- a shell environment variable called RABBITMQ_var_name is used if this is defined;
- otherwise, a variable called var_name is used if this is set in the rabbitmq-env.conf file;
- otherwise, a system-specified default value is used.
如果在/rabbitmq-env.conf文件里,Use the standard environment variable names (but drop the RABBITMQ_ prefix) e.g.
#example rabbitmq-env.conf file entries #Rename the node NODENAME=bunny@myhost #Config file location and new filename bunnies.config CONFIG_FILE=/etc/rabbitmq/testdir/bunnies
2)a configuration file:defines [server component(RabbitMQ core application, Erlang services and RabbitMQ plugins)] settings for permissions, limits and clusters, and also plugin settings. 标准的erlang配置文件,例子:
[
{mnesia, [{dump_log_write_threshold, 1000}]},
{rabbit, [{tcp_listeners, [5673]}]}
].
This example will alter the dump_log_write_threshold for mnesia (increasing from the default of 100), and alter the port RabbitMQ listens on from 5672 to 5673.
Distributed RabbitMQ brokers
AMQP and the other messaging protocols supported by RabbitMQ via plug-ins (e.g. STOMP), are (of course) inherently distributed - it is quite common for applications from multiple machines to connect to a single broker, even across the internet.
RabbitMQ broker分布式的方法:1)clustering, 2)federation, 3)using the shovel
Note that you do not need to pick a single approach - you can connect clusters together with federation, or the shovel, or both.
Clustering
2)The network links between machines in a cluster must be reliable;
3)all machines in the cluster must run the same versions of RabbitMQ and Erlang.
Typically you would use clustering for high availability and increased throughput, with machines in a single location.
Federation
Federation allows an exchange or queue on one broker to receive messages published to an exchange or queue on another (the brokers may be individual machines, or clusters). Communication is via AMQP (with optional SSL), so for two exchanges or queues to federate they must be granted appropriate users and permissions.
Federated exchanges are connected with one way point-to-point links. By default, messages will only be forwarded over a federation link once, but this can be increased to allow for more complex routing topologies. Some messages may not be forwarded over the link; if a message would not be routed to a queue after reaching the federated exchange, it will not be forwarded in the first place.
Federated queues are similarly connected with one way point-to-point links. Messages will be moved between federated queues an arbitrary number of times to follow the consumers.
Typically you would use federation to link brokers across the internet for pub/sub messaging and work queueing.
The Shovel
Connecting brokers with the shovel is conceptually similar to connecting them with federation. However, the shovel works at a lower level.
Whereas federation aims to provide opinionated distribution of exchanges and queues, the shovel simply consumes messages from a queue on one broker, and forwards them to an exchange on another.
Typically you would use the shovel to link brokers across the internet when you need more control than federation provides.
Dynamic shovels can also be useful for moving messages around in an ad-hoc manner on a single broker.
Summary
| Brokers are logically separate and may have different owners. | A cluster forms a single logical broker. |
| Brokers can run different versions of RabbitMQ and Erlang. | Nodes must run the same version of RabbitMQ, and frequently Erlang. |
| Brokers can be connected via unreliable WAN links. Communication is via AMQP (optionally secured by SSL), requiring appropriate users and permissions to be set up. | Brokers must be connected via reliable LAN links. Communication is via Erlang internode messaging, requiring a shared Erlang cookie. |
| Brokers can be connected in whatever topology you arrange. Links can be one- or two-way. | All nodes connect to all other nodes in both directions. |
| Chooses Availability and Partition Tolerance from the CAP theorem. | Chooses Consistency and Availability (or optionally Consistency and Partition Tolerance) from the CAP theorem. |
| Some exchanges in a broker may be federated while some may be local. | Clustering is all-or-nothing. |
| A client connecting to any broker can only see queues in that broker. | A client connecting to any node can see queues on all nodes. |
Federation

rabbitmq-plugins enable rabbitmq_federation
rabbitmq-plugins enable rabbitmq_federation_management
rabbitmq-plugins enable rabbitmq_management
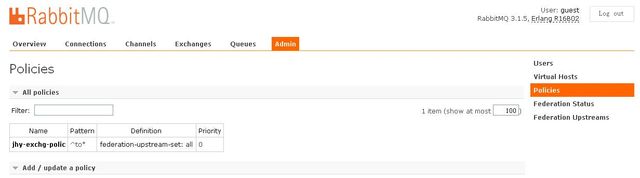
- Upstreams - 定义如何连接到upstream的rmq上
- Upstream sets - upstream的集合,默认一个all集合(包含所有定义好的upstream)
- Policies - 定义的一批配置, 整批的配置可以按pattern apply to给具体的rmq组件(exchange,queue,connections....),这里是把配置好的federation upstream配置应用到哪个exchange
参数:1)uri: The AMQP URI(s) for the upstream. 必填.2) prefetch-count: The maximum number of unacknowledged messages copied over a link at any one time. Default is 1000 .3)reconnect-delay:The duration (in seconds) to wait before reconnecting to the broker after being disconnected. Default is 1. 3)ack-mode:Determines how the link should acknowledge messages. on-confirm (the default):messages are acknowledged to the upstream broker after they have been confirmed downstream. This handles network errors and broker failures without losing messages, and is the slowest option. on-publish:messages are acknowledged to the upstream broker after they have been published downstream. This handles network errors without losing messages, but may lose messages in the event of broker failures. no-ack:message acknowledgements are not used. This is the fastest option, but may lose messages in the event of network or broker failures. 4)trust-user-id:Determines how federation should interact with the validated user-id feature. If set to true, federation will pass through any validated user-id from the upstream, even though it cannot validate it itself. If set to false or not set, it will clear any validated user-id it encounters. You should only set this to true if you trust the upstream server (and by extension, all its upstreams) not to forge user-ids.
5)exchange:The name of the upstream exchange. Default is to use the same name as the federated exchange. 6)max-hops:The maximum number of federation links that a message published to a federated exchange can traverse before it is discarded. Default is 1. Note that even if max-hops is set to a value greater than 1, messages will never visit the same node twice due to travelling in a loop. However, messages may still be duplicated if it is possible for them to travel from the source to the destination via multiple routes. 7)expires:The expiry time (in milliseconds) after which an upstream queue for a federated exchange may be deleted, if a connection to the upstream broker is lost. The default is 'none', meaning the queue should never expire.This setting controls how long the upstream queue will last before it is eligible for deletion if the connection is lost.This value is used to set the "x-expires" argument for the upstream queue. 8)message-ttl:The expiry time for messages in the upstream queue for a federated exchange (see expires), in milliseconds. Default is 'none', meaning messages should never expire. This does not apply to federated queues.This value is used to set the "x-message-ttl" argument for the upstream queue. 9)ha-policy:Determines the "x-ha-policy" argument for the upstream queue for a federated exchange (see expires). This is only of interest when connecting to old brokers which determine queue HA mode using this argument. Default is 'none', meaning the queue is not HA.常用命令
开机启动:chkconfig rabbitmq-server on
开关服务:/sbin/rabbitmq-server start
· rabbitmqctl stop
· 查看状态:rabbitmqctl status
插件 :rabbitmq-plugin list -
组件
Producer
Connection
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection(); è创建2个线程,一个心跳线程发送心跳帧,一个接收帧读主线程(特殊帧则由channel0处理,不是则使用channelManage根据帧的channl的id获得channel,在channel进行handleFrame),如果是非心跳帧则发送给channel。
connection 封装socket connection,负责protocol version negotiation and authentication
1)用一个channel channel0和Server进行协议参数
特点:
1)使用完必须关闭
2)线程池
Consumer threads are automatically allocated in a new ExecutorService thread pool by default.
If greater control is required supply an ExecutorService on the newConnection() method, so that this pool of threads is used instead. Here is an example where a larger thread pool is supplied than is normally allocated:
ExecutorService es = Executors.newFixedThreadPool(20);
Connection conn = factory.newConnection(es);
When the connection is closed a default ExecutorService will be shutdown(), but a user-suppliedExecutorService (like es above) will not be shutdown(). Clients that supply a custom ExecutorService must ensure it is shutdown eventually (by calling its shutdown() method), or else the pool’s threads may prevent JVM termination.
The same executor service may be shared between multiple connections, or serially re-used on re-connection but it cannot be used after it is shutdown().
适用场景:if there is evidence that there is a severe bottleneck in the processing of Consumer callbacks. If there are no Consumer callbacks executed, or very few, the default allocation is more than sufficient. The overhead is initially minimal and the total thread resources allocated are bounded, even if a burst of consumer activity may occasionally occur.
3)Address array
Channel
Channel channel = connection.createChannel();
属性:
1)标识名:the name of the queue
2)durable:true if we are declaring a durable queue (the queue will survive a server restart)
3)exclusive:true if we are declaring an exclusive queue (restricted to this connection)
4)autoDelete:true if we are declaring an autodelete queue (server will delete it when no longer in use)
5)其他参数
6)线程安全,但不提倡共享:Channel instances are safe for use by multiple threads. Requests into a Channel are serialized, with only one thread being able to run a command on the Channel at a time. Even so, applications should prefer using a Channel per thread instead of sharing the same Channel across multiple threads.
Connection 有channelManage,channelManage有map的channelN,channelN里面是使用socket 在tcp层与rmq通信发送通信帧,阻塞的。
Channel里的方法都加synchronized
行为:
1)basicPulish:publish a message
exchange the exchange to publish the message to
routingKey the routing key
props other properties for the message - routing headers etc
body the message body
2)basicConsume:Start a non-nolocal, non-exclusive consumer, with a server-generated consumerTag.
queue the name of the queue
autoAck true if the server should consider messages acknowledged once delivered; false if the server should expect explicit acknowledgements
callback an interface to the consumer object
3)basicQos:Request a specific prefetchCount "quality of service" settings for this channel
每次给一个customer <=n个消息,一般搭配显示ack。
Exchanger
An exchange receives messages from producers and pushes them to queues.
The exchange must know exactly what to do with a message it receives.
Should it be appended to a particular queue? Should it be appended to many queues?
Or should it get discarded.
The rules for that are defined by the exchange type.
属性:
1)标识名:
2)类型:
类型:
1)direct:a message goes to the queues whose binding key exactly matches the routing key of the message.
2)topic:a message sent with a particular routing key will be delivered to all the queues that are bound with a matching binding key.
* (star) can substitute for exactly one word.
# (hash) can substitute for zero or more words.
3)headers
4)fanout:broadcasts all the messages it receives to all the queues it knows
默认已有的exchanges,rabbitmqctl list exchanges
Amq.direct
Direct
没有指定exchange时,默认使用的exchange
Amq.fanout
Fanout
Amq.headers
Headers
Amq.match
Headers
Amq.rabbitmq.log
Topic
Amq.rabbitmq.trace
Topic
Amq.topic
topic
Queue
特点:
1)无界:not bound by any limits
2)幂等:only be created if it doesn't exist already [幂等性是指一次和多次请求某一个资源应该具有同样的副作用]
3)消息存放格式:byte array
4)使用完需要关闭
5)RabbitMQ doesn't allow redefine an existing queue with different parameters and will return an error to any program that tries to do that.
6)临时队列
In the Java client, when we supply no parameters to queueDeclare() we create a non-durable, exclusive, autodelete queue with a generated name:String queueName = channel.queueDeclare().getQueue();
At that point queueName contains a random queue name. For example it may look likeamq.gen-JzTY20BRgKO-HjmUJj0wLg.
绑定Bindings
need to tell the exchange to send messages to our queue.
That relationship between exchange and a queue is called a binding.
显示目前的bingdings:rabbitmqctl list_bindings
属性:
1) bindingKey: must be a list of words, delimited by dots. up to the limit of 255 bytes
规则:
1)The messages will be lost if no queue is bound to the exchange yet.if no consumer is listening yet we can safely discard the message.
2)It is perfectly legal to bind multiple queues with the same binding key.
Consumer
QueueingConsumer :
1 ) buffer the messages pushed to us by the server.
2 )是 [a callback in the form of an object] that will buffer the messages until we're ready to use them
3 ) an implementation of Consumer with straightforward blocking semantics. 阻塞的, nextDelivery 是阻塞的
QueueingConsumer.Delivery :
Encapsulates an arbitrary message - simple "bean" holder structure.
有:
1 ) body
2 ) envelope :
deliveryTag - the delivery tag
redeliver - true if this is a redelivery following a failed ack
exchange - the exchange used for the current operation
routingKey - the associated routing key
3 ) properties
4 )用户标识: When calling the API methods relating to Consumers, individual subscriptions are always referred to by their consumer tags. Distinct Consumers on the same Channel must have distinct consumer tags.
The easiest way to implement a Consumer is to subclass the convenience class DefaultConsumer. An object of this subclass can be passed on a basicConsume call to set up the subscription:
boolean autoAck = false;
channel.basicConsume(queueName, autoAck, "myConsumerTag",
new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag,
Envelope envelope,
AMQP.BasicProperties properties,
byte[] body)
throws IOException
{
String routingKey = envelope.getRoutingKey();
String contentType = properties.contentType;
long deliveryTag = envelope.getDeliveryTag();
// (process the message components here ...)
channel.basicAck(deliveryTag, false);
}
});
most conveniently done in the handleDelivery method, as illustrated.
handleShutdownSignal is called when channels and connections close,
handleConsumeOk is passed the consumer tag before any other callbacks to that Consumer are called.
handleCancelOk \ handleCancel methods to be notified of explicit and implicit cancellations, respectively.
You can explicitly cancel a particular Consumer with channel.basicCancel(consumerTag);
Callbacks to Consumers are dispatched on a thread separate from the thread managed by the Connection. This means that Consumers can safely call blocking methods on the Connection or Channel, such as queueDeclare, txCommit, basicCancel or basicPublish.
Each Channel has its own dispatch thread . For the most common use case of one Consumer per Channel, this means Consumers do not hold up other Consumers. If you have multiple Consumers per Channel be aware that a long-running Consumer may hold up dispatch of callbacks to other Consumers on that Channel.
Consumer 不能在同一个 channel 上同时定义一个 queue 和订阅另一个 queue
Message
Appid
classId
className
clusterId
contentEncoding
ContentType
Used to describe the mime-type of the encoding.
correlationId
Useful to correlate RPC responses with requests
is set to a unique value for every request
deliveryMode
Marks a message as persistent (with a value of 2) or transient (any other value)
Expiration
heades
messageId
Priority
replyTo
Commonly used to name a callback queue
timestamp
Type
userId
Routing_key
Immediate
不能立刻投递到哦消费者,返回失败
Mandatory
不能路由到队列,返回失败
MessageProperties
Content-type
deliveryMode
Priority
BASIC
Application/octet-stream
1:nonpersistent
0
MINIMAL_BASIC
MINIMAL_PERSISTENT_BASIC
2:persistent
PERSISTENT_BASIC
Application/octet-stream
2:persistent
0
PERSISTENT_TEXT_PLAIN
Text/plain
2:persistent
0
TEXT_PLAIN
Text/plain
1:nonpersistent
0
vhost
机制
线程相关
Consumer threads are automatically allocated in a new ExecutorService thread pool by default.
Callbacks to Consumers are dispatched on a thread separate from the thread managed by the Connection. This means that Consumers can safely call blocking methods on the Connection or Channel, such as queueDeclare, txCommit, basicCancel or basicPublish.
Each Channel has its own dispatch thread. For the most common use case of one Consumer per Channel, this means Consumers do not hold up other Consumers. If you have multiple Consumers per Channel be aware that a long-running Consumer may hold up dispatch of callbacks to other Consumers on that Channel.
轮询调度
默认地RabbitMQ will send each message to the next consumer, in sequence. On average every consumer will get the same number of messages. This way of distributing messages is called round-robin.
Message acknowledgment
An ack(nowledgement) is sent back from the consumer to tell RabbitMQ that a particular message has been received, processed and that RabbitMQ is free to delete it.
If a consumer dies without sending an ack, RabbitMQ will understand that a message wasn't processed fully and will redeliver it to another consumer. That way you can be sure that no message is lost, even if the workers occasionally die.
There aren't any message timeouts; RabbitMQ will redeliver the message only when the worker connection dies. It's fine even if processing a message takes a very, very long time.
Message acknowledgments are turned on by default. In previous examples we explicitly turned them off via the autoAck=true flag. It's time to remove this flag and send a proper acknowledgment from the worker, once we're done with a task.
-
Message durability
When RabbitMQ quits or crashes it will forget the queues and messages unless you tell it not to. Two things are required to make sure that messages aren't lost: we need to mark both the queue and messages as durable.
Exchange
Queue
Route
Runtime_parameters
User
User_permission
Vhost
RabbitMQ支持消息的持久化,也就是数据写在磁盘上。消息队列持久化包括3个部分:
(1)exchange持久化,在声明时指定durable => 1
(2)queue持久化,在声明时指定durable => 1
(3)消息持久化,在投递时指定delivery_mode => 2(1是非持久化)如果exchange和queue都是持久化的,那么它们之间的binding也是持久化的。如果exchange和queue两者之间有一个持久化,一个非持久化,就不允许建立绑定。
启动时的日志
${node}.log中记录
Starting RabbitMQ 3.1.3 on Erlang R16B01
Copyright (C) 2007-2013 VMware, Inc.
Licensed under the MPL. See http://www.rabbitmq.com/
node
rabbit@LBDZ-02201559
home dir
C:\WINDOWS
config file(s)
(none)
cookie hash
EN9Dcl/uRBFsY0r2iJhaQQ==
log
~/Application Data/RabbitMQ/log/${node}.log
sasl log
~/Application Data/RabbitMQ/log/${node}-sasl.log
database dir
~/Application Data/RabbitMQ/log/${node}-mnesia
Limiting to approx 8092 file handles (7280 sockets)
Only 2048MB of 3071MB memory usable due to limited address space.
Memory limit set to 819MB of 3071MB total.
Disk free limit set to 1000MB
如果没有达到1G,则refusing to accept messages。参数:disk_free_limit
Adding vhost '/'
Creating user 'guest'
Setting user tags for user 'guest' to [administrator]
Setting permissions for 'guest' in '/' to '.*', '.*', '.*'
msg_store_transient: using rabbit_msg_store_ets_index to provide index
msg_store_persistent: using rabbit_msg_store_ets_index to provide index
msg_store_persistent: rebuilding indices from scratch
started TCP Listener on 0.0.0.0:5672
Server startup complete; 0 plugins started.