HDFS介绍
环境:Hadoop 1.X
HDFS
提供分布式存储机制,提供可线性增长的海量存储能力
自动数据冗余,无须使用Raid,无须另行备份
为进一步分析计算提供数据基础
HDFS设计基础与目标
硬件错误是常态。因此需要冗余
流式数据访问。即数据批量读取而非随机读写, Hadoop擅长做的是数据分析而不是事务处理
大规模数据集
简单一致性模型。为了降低系统复杂度,对文件采用一次性写多次读的逻辑设计,即是文件一经写入,关闭,就再也不能修改
程序采用“数据就近”原则分配节点执行
HDFS体系结构
NameNode
DataNode
事务日志
映像文件
SecondaryNameNode

Namenode
管理文件系统的命名空间
记录每个文件数据块在各个Datanode上的位置和副本信息
协调客户端对文件的访问
记录命名空间内的改动或空间本身属性的改动
Namenode使用事务日志记录HDFS元数据的变化。使用映像文件存储文件系统的命名空间,包括文件映射,文件属性等
Datanode
负责所在物理节点的存储管理
一次写入,多次读取(不修改)
文件由数据块组成,典型的块大小是64MB
数据块尽量散布道各个节点
读取数据流程
客户端要访问HDFS中的一个文件
首先从namenode获得组成返个文件的数据块位置列表
根据列表知道存储数据块的datanode
访问datanode获取数据
Namenode并不参不数据实际传输
读过程图解

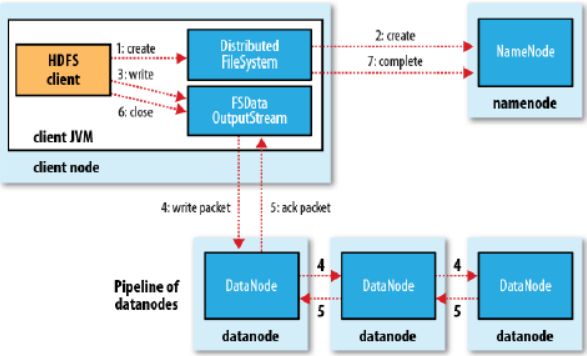
写入数据流程
客户端请求namenode创建新文件
客户端将数据写入DFSOutputStream
建立pipeline依次将目标数据块写入各个datanode,建立多个副本
写过程图解
HDFS的可靠性
冗余副本策略
机架策略
心跳机制
安全模式
校验和
回收站
元数据保护
快照机制
冗余副本策略
可以在hdfs-site.xml中设置复制因子指定副本数量
所有数据块都有副本
Datanode启动时,遍历本地文件系统,产生一份hdfs数据块和本地文件的对应关系列表( blockreport)汇报给namenode
机架策略
集群一般放在不同机架上,机架间带宽要比机架内带宽要小
HDFS的“机架感知”
一般在本机架存放一个副本,在其它机架再存放别的副本,这样可以防止机架失效时丢失数据,也可以提高带宽利用率

RackAware.py
#!/usr/bin/python
#-*-coding:UTF-8 -*-
import sys
rack = {
"hadoop-node-31":"rack1",
"hadoop-node-32":"rack1",
"hadoop-node-49":"rack2",
"hadoop-node-50":"rack2",
"hadoop-node-51":"rack2",
"192.168.1.31":"rack1",
"192.168.1.32":"rack1",
"192.168.1.49":"rack2",
"192.168.1.50":"rack2",
"192.168.1.51":"rack2",
}
if __name__=="__main__":
print "/" +rack.get(sys.argv[1],"rack0")
core-site.xml配置文件
<property>
<name>topology.script.file.name</name>
<value>/opt/modules/hadoop/hadoop-1.0.3/bin/RackAware.py</value><!--机架感知脚本路径-->
</property>
<property>
<name>topology.script.number.args</name>
<value>10</value><!--服务器数量-->
</property>
然后重启hadoop的namenode和jobtracker,可以在logs里看下namenode和jobtracker的日志,看到机架感知功能已经启用了。
心跳机制
Namenode周期性从datanode接收心跳信号和块报告
Namenode根据块报告验证元数据
没有按时发送心跳的datanode会被标记为宕机,不会再给它任何I/O请求
如果datanode失效造成副本数量下降,并且低于预先设置的阈值, namenode会检测出返些数据块,并在合适的时机迕行重新复制
引发重新复制的原因迓包括数据副本本身损坏、磁盘错误,复制因子被增大等
安全模式
Namenode启劢时会先经过一个“安全模式”阶段
安全模式阶段不会产生数据写
在此阶段Namenode收集各个datanode的报告,当数据块达到最小副本数以上时,会被认为是“安全”的
在一定比例(可设置)的数据块被确定为“安全”后,再过若干时间,安全模式结束
当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数
校验和
在文件创立时,每个数据块都产生校验和
校验和保存在.meta文件内
客户端获取数据时可以检查校验和是否相同,从而发现数据块是否损坏
如果正在读取的数据块损坏,则可以继续读取其它副本
回收站
初除文件时,其实是放入回收站/trash
回收站里的文件可以快速恢复
可以设置一个时间阈值,当回收站里文件的存放时间超过返个阈值,就被彻底初除,并且释放占用的数据块
打开回收站功能
在conf/core-site.xml添加配置:
<property>
<name>fs.trash.interval</name>
<value>10080</value>
<description>
Number of minutes between trashcheckpoints. If zero, the trash feature is disabled
</description>
</property>
重启集群
元数据保护
映像文件刚和事务日志是Namenode的核心数据。可以配置为拥有多个副本
副本会降低Namenode的处理速度,但增加安全性
Namenode依然是单点,如果发生故障要手工切换
快照
支持存储某个时间点的映像,需要时可以使数据重迒返个时间点的状态
Hadoop目前前不支持快照,已经列入开发计划,传说在Hadoop2.x某版本里讲获得此功能
HDFS文件操作
命令行方式
API方式
列出HDFS下的文件
注意,hadoop没有当前目录的概念,也没有cd命令
[grid@hadoop1 hadoop-1.2.1]$ ./bin/hadoop fs -ls
上传文件到HDFS
[grid@hadoop1 hadoop-1.2.1]$ ./bin/hadoop fs -put ../test.txt ./in
数据写在了哪儿(从OS看)
[grid@hadoop2 current]$ pwd
/home/grid/hadoop-1.2.1/tmp/dfs/data/current
[grid@hadoop2 current]$ ll
总用量 116
-rw-rw-r-- 1 grid grid 4 1月 3 00:06 blk_1094760079391893563
-rw-rw-r-- 1 grid grid 11 1月 3 00:06 blk_1094760079391893563_2710.meta
-rw-rw-r-- 1 grid grid 12 1月 3 00:15 blk_-196158584578311779
-rw-rw-r-- 1 grid grid 11 1月 3 00:15 blk_-196158584578311779_2711.meta
-rw-rw-r-- 1 grid grid 25 1月 3 00:18 blk_-4062373026097978062
-rw-rw-r-- 1 grid grid 11 1月 3 00:18 blk_-4062373026097978062_2721.meta
-rw-rw-r-- 1 grid grid 16373 1月 3 00:18 blk_4381313033413389167
-rw-rw-r-- 1 grid grid 135 1月 3 00:18 blk_4381313033413389167_2722.meta
-rw-rw-r-- 1 grid grid 13 1月 3 00:15 blk_-4506020707344896059
-rw-rw-r-- 1 grid grid 11 1月 3 00:15 blk_-4506020707344896059_2712.meta
-rw-rw-r-- 1 grid grid 50560 1月 3 00:18 blk_7732580110222652895
-rw-rw-r-- 1 grid grid 403 1月 3 00:18 blk_7732580110222652895_2720.meta
-rw-rw-r-- 1 grid grid 770 1月 3 00:52 dncp_block_verification.log.curr
-rw-rw-r-- 1 grid grid 159 1月 3 00:06 VERSION
将HDFS的文件复制到本地
[grid@hadoop1 hadoop-1.2.1]$ ./bin/hadoop fs -get ./in/test.txt ../test.bak
查看HDFS下某个文件的内容
[grid@hadoop1 hadoop-1.2.1]$ ./bin/hadoop fs -cat ./in/test.txt
删除HDFS下的文档
[grid@hadoop1 hadoop-1.2.1]$ ./bin/hadoop fs -rmr ./in/test.txt
查看HDFS基本统计信息
[grid@hadoop1 hadoop-1.2.1]$ ./bin/hadoop dfsadmin -report
怎样添加节点?
在新节点安装好hadoop
把namenode的有关配置文件复制到该节点
修改masters和slaves文件,增加该节点
设置ssh免密码进出该节点
单独启动该节点上的datanode和tasktracker(hadoop-daemon.sh startdatanode/tasktracker)
运行start-balancer.sh进行数据负载均衡
负载均衡
作用:当节点出现故障,或新增加节点时,数据块分布可能不均匀,负载均衡可以重新平衡各个datanode上数据块的分布
HDFS
提供分布式存储机制,提供可线性增长的海量存储能力
自动数据冗余,无须使用Raid,无须另行备份
为进一步分析计算提供数据基础
HDFS设计基础与目标
硬件错误是常态。因此需要冗余
流式数据访问。即数据批量读取而非随机读写, Hadoop擅长做的是数据分析而不是事务处理
大规模数据集
简单一致性模型。为了降低系统复杂度,对文件采用一次性写多次读的逻辑设计,即是文件一经写入,关闭,就再也不能修改
程序采用“数据就近”原则分配节点执行
HDFS体系结构
NameNode
DataNode
事务日志
映像文件
SecondaryNameNode
Namenode
管理文件系统的命名空间
记录每个文件数据块在各个Datanode上的位置和副本信息
协调客户端对文件的访问
记录命名空间内的改动或空间本身属性的改动
Namenode使用事务日志记录HDFS元数据的变化。使用映像文件存储文件系统的命名空间,包括文件映射,文件属性等
Datanode
负责所在物理节点的存储管理
一次写入,多次读取(不修改)
文件由数据块组成,典型的块大小是64MB
数据块尽量散布道各个节点
读取数据流程
客户端要访问HDFS中的一个文件
首先从namenode获得组成返个文件的数据块位置列表
根据列表知道存储数据块的datanode
访问datanode获取数据
Namenode并不参不数据实际传输
读过程图解
写入数据流程
客户端请求namenode创建新文件
客户端将数据写入DFSOutputStream
建立pipeline依次将目标数据块写入各个datanode,建立多个副本
写过程图解
HDFS的可靠性
冗余副本策略
机架策略
心跳机制
安全模式
校验和
回收站
元数据保护
快照机制
冗余副本策略
可以在hdfs-site.xml中设置复制因子指定副本数量
所有数据块都有副本
Datanode启动时,遍历本地文件系统,产生一份hdfs数据块和本地文件的对应关系列表( blockreport)汇报给namenode
机架策略
集群一般放在不同机架上,机架间带宽要比机架内带宽要小
HDFS的“机架感知”
一般在本机架存放一个副本,在其它机架再存放别的副本,这样可以防止机架失效时丢失数据,也可以提高带宽利用率
RackAware.py
#!/usr/bin/python
#-*-coding:UTF-8 -*-
import sys
rack = {
"hadoop-node-31":"rack1",
"hadoop-node-32":"rack1",
"hadoop-node-49":"rack2",
"hadoop-node-50":"rack2",
"hadoop-node-51":"rack2",
"192.168.1.31":"rack1",
"192.168.1.32":"rack1",
"192.168.1.49":"rack2",
"192.168.1.50":"rack2",
"192.168.1.51":"rack2",
}
if __name__=="__main__":
print "/" +rack.get(sys.argv[1],"rack0")
core-site.xml配置文件
<property>
<name>topology.script.file.name</name>
<value>/opt/modules/hadoop/hadoop-1.0.3/bin/RackAware.py</value><!--机架感知脚本路径-->
</property>
<property>
<name>topology.script.number.args</name>
<value>10</value><!--服务器数量-->
</property>
然后重启hadoop的namenode和jobtracker,可以在logs里看下namenode和jobtracker的日志,看到机架感知功能已经启用了。
心跳机制
Namenode周期性从datanode接收心跳信号和块报告
Namenode根据块报告验证元数据
没有按时发送心跳的datanode会被标记为宕机,不会再给它任何I/O请求
如果datanode失效造成副本数量下降,并且低于预先设置的阈值, namenode会检测出返些数据块,并在合适的时机迕行重新复制
引发重新复制的原因迓包括数据副本本身损坏、磁盘错误,复制因子被增大等
安全模式
Namenode启劢时会先经过一个“安全模式”阶段
安全模式阶段不会产生数据写
在此阶段Namenode收集各个datanode的报告,当数据块达到最小副本数以上时,会被认为是“安全”的
在一定比例(可设置)的数据块被确定为“安全”后,再过若干时间,安全模式结束
当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数
校验和
在文件创立时,每个数据块都产生校验和
校验和保存在.meta文件内
客户端获取数据时可以检查校验和是否相同,从而发现数据块是否损坏
如果正在读取的数据块损坏,则可以继续读取其它副本
回收站
初除文件时,其实是放入回收站/trash
回收站里的文件可以快速恢复
可以设置一个时间阈值,当回收站里文件的存放时间超过返个阈值,就被彻底初除,并且释放占用的数据块
打开回收站功能
在conf/core-site.xml添加配置:
<property>
<name>fs.trash.interval</name>
<value>10080</value>
<description>
Number of minutes between trashcheckpoints. If zero, the trash feature is disabled
</description>
</property>
重启集群
元数据保护
映像文件刚和事务日志是Namenode的核心数据。可以配置为拥有多个副本
副本会降低Namenode的处理速度,但增加安全性
Namenode依然是单点,如果发生故障要手工切换
快照
支持存储某个时间点的映像,需要时可以使数据重迒返个时间点的状态
Hadoop目前前不支持快照,已经列入开发计划,传说在Hadoop2.x某版本里讲获得此功能
HDFS文件操作
命令行方式
API方式
列出HDFS下的文件
注意,hadoop没有当前目录的概念,也没有cd命令
[grid@hadoop1 hadoop-1.2.1]$ ./bin/hadoop fs -ls
上传文件到HDFS
[grid@hadoop1 hadoop-1.2.1]$ ./bin/hadoop fs -put ../test.txt ./in
数据写在了哪儿(从OS看)
[grid@hadoop2 current]$ pwd
/home/grid/hadoop-1.2.1/tmp/dfs/data/current
[grid@hadoop2 current]$ ll
总用量 116
-rw-rw-r-- 1 grid grid 4 1月 3 00:06 blk_1094760079391893563
-rw-rw-r-- 1 grid grid 11 1月 3 00:06 blk_1094760079391893563_2710.meta
-rw-rw-r-- 1 grid grid 12 1月 3 00:15 blk_-196158584578311779
-rw-rw-r-- 1 grid grid 11 1月 3 00:15 blk_-196158584578311779_2711.meta
-rw-rw-r-- 1 grid grid 25 1月 3 00:18 blk_-4062373026097978062
-rw-rw-r-- 1 grid grid 11 1月 3 00:18 blk_-4062373026097978062_2721.meta
-rw-rw-r-- 1 grid grid 16373 1月 3 00:18 blk_4381313033413389167
-rw-rw-r-- 1 grid grid 135 1月 3 00:18 blk_4381313033413389167_2722.meta
-rw-rw-r-- 1 grid grid 13 1月 3 00:15 blk_-4506020707344896059
-rw-rw-r-- 1 grid grid 11 1月 3 00:15 blk_-4506020707344896059_2712.meta
-rw-rw-r-- 1 grid grid 50560 1月 3 00:18 blk_7732580110222652895
-rw-rw-r-- 1 grid grid 403 1月 3 00:18 blk_7732580110222652895_2720.meta
-rw-rw-r-- 1 grid grid 770 1月 3 00:52 dncp_block_verification.log.curr
-rw-rw-r-- 1 grid grid 159 1月 3 00:06 VERSION
将HDFS的文件复制到本地
[grid@hadoop1 hadoop-1.2.1]$ ./bin/hadoop fs -get ./in/test.txt ../test.bak
查看HDFS下某个文件的内容
[grid@hadoop1 hadoop-1.2.1]$ ./bin/hadoop fs -cat ./in/test.txt
删除HDFS下的文档
[grid@hadoop1 hadoop-1.2.1]$ ./bin/hadoop fs -rmr ./in/test.txt
查看HDFS基本统计信息
[grid@hadoop1 hadoop-1.2.1]$ ./bin/hadoop dfsadmin -report
怎样添加节点?
在新节点安装好hadoop
把namenode的有关配置文件复制到该节点
修改masters和slaves文件,增加该节点
设置ssh免密码进出该节点
单独启动该节点上的datanode和tasktracker(hadoop-daemon.sh startdatanode/tasktracker)
运行start-balancer.sh进行数据负载均衡
负载均衡
作用:当节点出现故障,或新增加节点时,数据块分布可能不均匀,负载均衡可以重新平衡各个datanode上数据块的分布