详解运维监控利器Nagios 系列(三)-配置Nagios监控系统 (1)
详解运维监控利器Nagios 系列(三)-配置Nagios监控系统(1)
1、nagios默认配置文件介绍
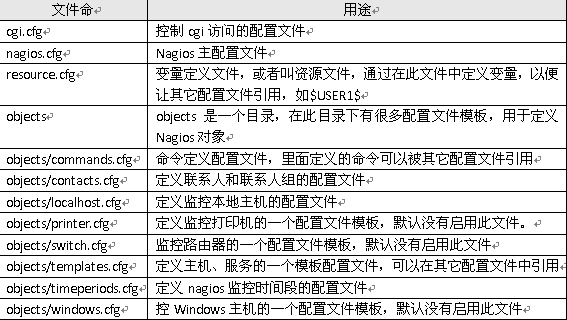
nagios安装完毕后,默认的配置文件在/usr/local/nagios/etc目录下,每个文件或目录含义如下表所示:
2、配置文件之间的关系
在nagios的配置过程中涉及到的几个定义有:主机、主机组,服务、服务组,联系人、联系人组,监控时间,监控命令等,从这些定义可以看出,nagios各个配置文件之间是互为关联,彼此引用的。
成功配置出一台nagios监控系统,必须要弄清楚每个配置文件之间依赖与被依赖的关系,最重要的有四点:
第一:定义监控哪些主机、主机组、服务和服务组
第二:定义这个监控要用什么命令实现,
第三:定义监控的时间段,
第四:定义主机或服务出现问题时要通知的联系人和联系人组。
3、开始配置nagios
为了能更清楚的说明问题,同时也为了维护方便,建议将nagios各个定义对象创建独立的配置文件:
即为:
创建hosts.cfg文件来定义主机和主机组
创建services.cfg文件来定义服务
用默认的contacts.cfg文件来定义联系人和联系人组
用默认的commands.cfg文件来定义命令
用默认的timeperiods.cfg来定义监控时间段
用默认的templates.cfg文件作为资源引用文件
(1)templates.cfg文件
nagios主要用于监控主机资源以及服务,在nagios配置中称为对象,为了不必重复定义一些监控对象,Nagios引入了一个模板配置文件,将一些共性的属性定义成模板,以便于多次引用。这就是templates.cfg的作用。
下面详细介绍下templates.cfg文件中每个参数的含义:
define host{
name linux-server #主机名称
use generic-host #use表示引用,也就是将主机generic-host的所有属性引用到linux-server中来,在nagios配置中,很多情况下会用到引用。
check_period 24x7 #这里的check_period告诉nagios检查主机的时间段
check_interval 5 #nagios对主机的检查时间间隔,这里是5分钟。
retry_interval 1 #重试检查时间间隔,单位是分钟。
max_check_attempts 10 #nagios对主机的最大检查次数,也就是nagios在检查发现某主机异常时,并不马上判断为异常状况,而是多试几次,因为有可能只是一时网络太拥挤,或是一些其他原因,让主机受到了一点影响,这里的10就是至少试10次的意思。
check_command check-host-alive #指定检查主机状态的命令,其中“check-host-alive”在commands.cfg文件中定义。
notification_period workhours #主机故障时,发送通知的时间范围,其中“workhours”在timeperiods.cfg中进行了定义,下面会陆续讲到。
notification_interval 120 #在主机出现异常后,故障一直没有解决,nagios再次对使用者发出通知的时间。单位是分钟。如果你觉得,所有的事件只需要一次通知就够了,可以把这里的选项设为0
notification_options d,u,r #定义主机在什么状态下可以发送通知给使用者,d即down,表示宕机状态,u即unreachable,表示不可到达状态,r即recovery,表示重新恢复状态。
contact_groups admins #指定联系人组,这个“admins”在contacts.cfg文件中定义。
register 0
}
define host{
name linux-server #主机名称
use generic-host #use表示引用,也就是将主机generic-host的所有属性引用到linux-server中来,在nagios配置中,很多情况下会用到引用。
check_period 24x7 #这里的check_period告诉nagios检查主机的时间段
check_interval 5 #nagios对主机的检查时间间隔,这里是5分钟。
retry_interval 1 #重试检查时间间隔,单位是分钟。
max_check_attempts 10 #nagios对主机的最大检查次数,也就是nagios在检查发现某主机异常时,并不马上判断为异常状况,而是多试几次,因为有可能只是一时网络太拥挤,或是一些其他原因,让主机受到了一点影响,这里的10就是至少试10次的意思。
check_command check-host-alive #指定检查主机状态的命令,其中“check-host-alive”在commands.cfg文件中定义。
notification_period workhours #主机故障时,发送通知的时间范围,其中“workhours”在timeperiods.cfg中进行了定义,下面会陆续讲到。
notification_interval 120 #在主机出现异常后,故障一直没有解决,nagios再次对使用者发出通知的时间。单位是分钟。如果你觉得,所有的事件只需要一次通知就够了,可以把这里的选项设为0
notification_options d,u,r #定义主机在什么状态下可以发送通知给使用者,d即down,表示宕机状态,u即unreachable,表示不可到达状态,r即recovery,表示重新恢复状态。
contact_groups admins #指定联系人组,这个“admins”在contacts.cfg文件中定义。
Register 0
}
define service{
name generic-service #定义一个服务名称
active_checks_enabled 1
passive_checks_enabled 1
parallelize_check 1
obsess_over_service 1
check_freshness 0
notifications_enabled 1
event_handler_enabled 1
flap_detection_enabled 1
failure_prediction_enabled 1
process_perf_data 1
retain_status_information 1
retain_nonstatus_information 1
is_volatile 0
check_period 24x7 #这里的check_period告诉nagios检查服务的时间段。
max_check_attempts 3 #nagios对服务的最大检查次数。
normal_check_interval 10 #此选项是用来设置服务检查时间间隔,也就是说,nagios这一次检查和下一次检查之间所隔的时间,这里是10分钟。
retry_check_interval 2 #重试检查时间间隔,单位是分钟。
contact_groups admins #指定联系人组,同上。
notification_options w,u,c,r #这个定义的是“通知可以被发出的情况”。w即warn,表示警告状态,u即unknown,表示不明状态,c即criticle,表示紧急状态,r即recover,表示恢复状态。也就是在服务出现警告状态、未知状态、紧急状态和重新恢复后都发送通知给使用者。
notification_interval 60 #在服务出现异常后,故障一直没有解决,nagios再次对使用者发出通知的时间。单位是分钟。如果你认为,所有的事件只需要一次通知就够了,可以把这里的选项设为0。
notification_period 24x7 #指定“发送通知”的时间段,也就是可以在什么时候发送通知给使用者。
register 0
}
(2)resource.cfg文件
resource.cfg是nagios的变量定义文件,文件内容只有一行:
$USER1$=/usr/local/nagios/libexec
其中,变量$USER1$指定了安装nagios插件的路径,如果把插件安装在了其它路径,只需在这里进行修改即可。需要注意的是,变量必须先定义,然后才能在其它配置文件中进行引用。