Linux下Python的安装以及注意事项
Linux的yum依赖自带Python,为防止错误,这里我们再安装一个Python
首先查看默认Python版本
python -V
1、安装gcc,用于编译Python源码
[root@Python~]# yum install gcc
2、下载源码,https://www.python.org/ftp/python ,解压并切换到源码文件
3、编译安装
[root@Python tools]# tar xf Python-2.7.10.tar.xz
[root@Python tools]# ll
total 11968
drwxr-xr-x 17 1000 1000 4096 May 24 00:09 Python-2.7.10
-rw-r--r-- 1 root root 12250696 May 24 00:20 Python-2.7.10.tar.xz
[root@Python tools]# cd Python-2.7.10
[root@Python Python-2.7.10]# ./configure && make && make install
4、查看版本
[root@Python Python-2.7.10]# /usr/local/bin/python2.7 -V
Python 2.7.10
[root@Python Python-2.7.10]#
5、修改版本morePython版本
[root@Python Python-2.7.10]#mv /usr/bin/python /usr/bin/python2.6
[root@Python Python-2.7.10]#ln -s /usr/local/bin/python2.7 /usr/bin/python
6、防止yum执行异常,修改yum使用的Python版本
[root@Python Python-2.7.10]#vim /usr/bin/yum
将头部#!/usr/bin/python 改为 #!/usr/bin/python2.6
7、第一个Python代码
print ‘hello world!’
>>> print 'hello world'
hello world
>>>
8、字符编码
#-*- coding:utf-8 -*-
约定字符编码都用上面的"# -*- coding:utf-8 -*-"
#!/usr/bin/env python
#-*- coding:utf8 -*-
print 'hello world!'
print '你好,世界!'
[root@Python scripts]# ./hello.py
hello world!
你好,世界!
或者
[root@Python scripts]# python hello.py
hello world!
你好,世界!
总结:Python默认编码是ASCII,是用一个8位的二进制数字表示所有英文和特殊符号,即ASCII最多有256(2的8次方)种可能,因为没有考虑到中文,所以只能满足英文,如果我们要考虑中文,这里就采用utf8,(了解utf8可以将utf8与Unicode进行对比,他们的关系可以参考:http://alexiter.iteye.com/blog/1533109),在utf8中所有的英文还是用SACII码的形式来存储,中文就用3个字节存储,英文仍然用2个字节了,如果将英文改用三个字节存储,那么这样就造成了存储空间的浪费。
提示:Python2.7是Python2.0的最后一个版本
9、注释:
1)单行注释用"#"号
比如:
[root@Python scripts]# cat hello.py
#!/usr/bin/env python
#-*- coding:utf8 -*-
#print 'hello world!'
#print '你好,世界!
以上是单行注释,其中"
#!/usr/bin/env python "和“#-*- coding:utf8 -*-”是特殊的注释
2)多行注释
[root@Python scripts]# cat hello.py
#!/usr/bin/env python
#-*- coding:utf8 -*-
print 'hello world!'
print '你好,世界!'
"""
该Python脚本是用来测试Python语法功能的,
请不要用于正式环境
"""
三引号里面的部分就是多行注释一般用来说明脚本中某段代码的功能
10、获取脚本后面的参数 sys.argv
【
Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中:
Python内部提供的模块
业内开源的模块
程序员自己开发的模块
】
该模块名字是sys,是Python内置的模块
[root@Python scripts]# vim hello.py
#!/usr/bin/env python
#-*- coding:utf8 -*-
import sys
print sys.argv
print 'hello world!'
print '你好,世界!'
在hello.py后面添加参数 localhost:8001
[root@Python scripts]# python hello.py localhost:8001
['hello.py', 'localhost:8001'] #---->获取的两个参数hello.py和localhost:8001,并且将两个参数存放在一个集合中,该集合在这里叫做列表:['hello.py', 'localhost:8001']
hello world!
你好,世界!
11、字节码
运行.py文件后,同级目录下会出现很多.pyc后缀的文件,该文件就是Python解释器将Python脚本编译之后产生的字节码文件
提示:Python代码经过编译可以生成字节码文件(即:.pyc后缀的文件),字节码也可以反编译成Python代码文件(用反编译器),如果代码经过Python编译器生成字节码之后,再将Python代码该文件删除,后面还是可以继续运行,如果Python代码内容重新更新,那么再进行调用运行.pyc字节码时候就要重新编译Python代码文件而成新的字节码
12、Python的变量
变量名的要求:
1)变量名中只能是字母(大小写)、下划线、数字三种
2)变量名开头不能是数字
1name="rick" 2name="bobo"这些都是不符合规范的,
3)不能使用系统的关键字(系统已经内置了一些关键字)
>>> import keyword
>>> keyword.kwlist;
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
>>>
以上单词即为系统内置关键字,在定义变量时不要用他们作为变量名字
查看某个变量是否是关键字
>>> keyword.iskeyword ('待查询的字符串')
变量赋值:
#!/usr/bin/env python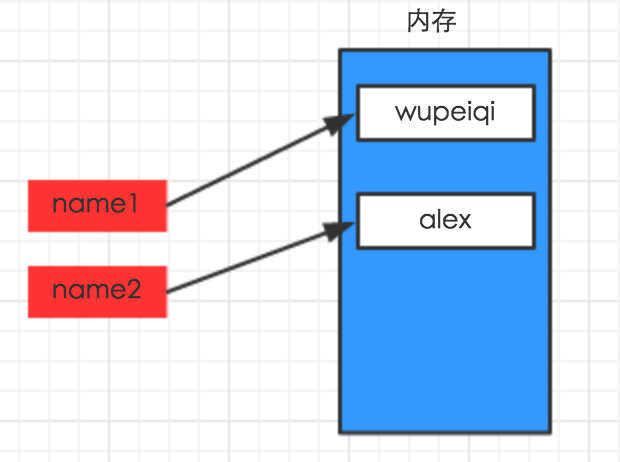 # -*- coding: utf-8 -*-
# -*- coding: utf-8 -*-
name1 = "wupeiqi"
name2 = "alex"
#!/usr/bin/env python
# -*- coding: utf-8 -*- 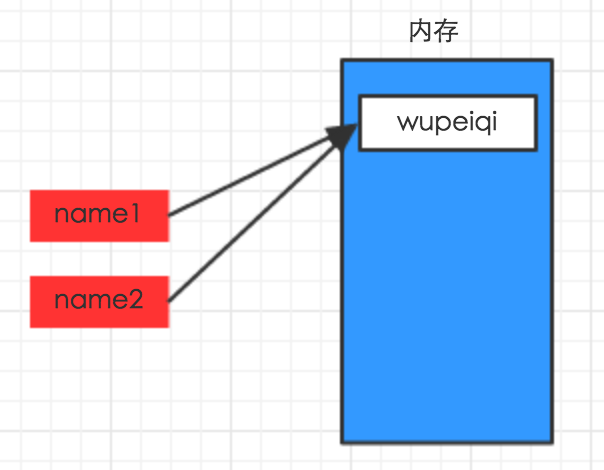
name1 = "wupeiqi"
name2 = name1
变量赋值的实质其实就是用某个别名将指针指向内存中某一块区域的存储的数据库,这里两个例子的别名依次为name1和name2,分别指向的内存中的对应位置的数据块(wupeiqi,alex)
在第二种情况变量复制中,如果修改name1的值,name2值是否会变化呢?这里我们通过实验来证明:
>>> name1="wupeiqi"
>>> name2=name1
>>> name2
'wupeiqi'
>>> name1="alex"
>>> name2
'wupeiqi'
>>> name1
'alex'
>>>
通过以上实验,得出结果,变量name2的值在变量name1发生变化时并不会随着name1而变化,因为变量的实质是存储在内存中数据的别名,而别名是通过指针指向内存中的数据块,当变量name1赋值为"alex"时,其实是将name1的指针指向内存中新开辟的数据块“alex”,而变量name2仍然指向原来的数据块“wupeiqi”,所以变量name2的值没有发生变化。
在Python中,如果要用字符串相加,即:"hello"+"sb"+"alex"这样的形式,
其实是在内存中一次开辟空间"hello"、“hello”+“sb”、"hello"+"sb"+“alex”等空间,而最终有用的空间为“hello”+“sb”+“alex”这一块,而其他的则内存空间处于浪费状态,这里就要用Python的虚拟机垃圾回收功能,而对于Python、java这些高级语言来说,对于程序员一般不用去关心垃圾回收,这些都自动交给了对应的虚拟机来完成。
另外对于:
name1="wupeiqi"
name2="wupeiqi"
实质上name1和name2指向内存中的两个数据块中的,内容都为“wupeiqi”,但是有人说id("name1")和id(name2)地址空间一样,其实Python相对于C语言而言,对内存寻址做了优化,对于常用的而且数据相同的内容都放在同一个地址空间内(或者地址段内),但是当数据长度达到一定的数量级之后,虽然内容相同但是内存地址也就会不相同,因为Python有一个内存地址的缓冲区,可以理解为如果数据相同而且数据长度小于等于内存缓冲区的长度,那么他们的内存地址表现为相同,否则就不同;这里可以用两个列子来说明:
>>> name1="wupeiqi"
>>> name2="wupeiqi"
>>> id(name1)
140084306598864
>>> id(name2)
140084306598864
>>> a=142584756214225512155212464431641346573.
>>> b=142584756214225512155212464431641346573.
>>> id(a)
25671328
>>> id(b)
25671352
>>>
如上例所述,因为name1和name2指向的数据块长度在Python地址空间缓冲区内,所以name1和name2的地址相同,而a和b的值已经超出了Python地址空间的缓冲区长度大小,所以显示出两个地址不同,其实如上例所示的两个变量赋值相同,其实质就是在内存中开辟两块完整相同的数据块进行存储他们,而不是一块数据指向两个变量