ceph分布式存储搭建经历
官方文档:http://docs.ceph.com/docs/master/start/quick-start-preflight/
汉化版:http://docs.openfans.org/ceph/
原理:利用ceph-deploy工具,通过管理节点admin-node,利用ssh通道,以达到控制各分布式节点存储的共享功能。
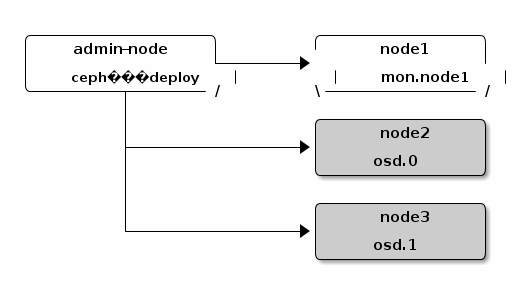

前提:admin-node 需提前安装好ceph-deploy;各分布节点需与admin-node时间同步,配置ssh彼此互信并拥有sudo权限;防火墙什么的先关掉再说。
主要步骤:
需新建目录,mkdir myceph && cd myceph,以下操作均在admin-node操作,我们命名为:ceph-mds,ceph-osd1,ceph-osd2,ceph-client;如在之前已有ceph环境下的目录操作,可能会影响ceph环境。
ceph目录下一般有这几个文件:
ceph.bootstrap-mds.keyring ceph.bootstrap-osd.keyring ceph.bootstrap-rgw.keyring ceph.client.admin.keyring ceph.conf ceph.log ceph.mon.keyring release.asc
1、start over:
ceph-deploy purgedata {ceph-node} [{ceph-node}] ##清空数据
ceph-deploy forgetkeys
##删除之前生成的密钥
ceph-deploy purge {ceph-node} [{ceph-node}] ##卸载ceph软件
If you execute purge, you must re-install Ceph.
2、start up:
1、Create the cluster. ---->ceph-deploy new {initial-monitor-node(s)}
2、Change the default number of replicas in the Ceph configuration file from 3 to 2 so that
Ceph can achieve an active + clean state with just two Ceph OSDs. Add the following line under the [global] section:---> osd pool default size = 23、If you have more than one network interface, add the public network setting under the [global] section of your Ceph configuration file.
See the Network Configuration Reference for details. ----->public network = {ip-address}/{netmask}
4、Install Ceph. ----> ceph-deploy install {ceph-node}[{ceph-node} ...]
5、Add the initial monitor(s) and gather the keys: ----> ceph-deploy mon create-initial/stat/remove/Once you complete the process, your local directory should have the following keyrings:
{cluster-name}.client.admin.keyring
{cluster-name}.bootstrap-osd.keyring
{cluster-name}.bootstrap-mds.keyring
{cluster-name}.bootstrap-rgw.keyring
3、ADD/REMOVE OSDS:
1、LIST DISKS :
To list the disks on a node, execute the following command: ---> ceph-deploy disk list {node-name [node-name]...}2、ZAP DISKS:
To zap a disk (delete its partition table) in preparation for use with Ceph, execute the following:
ceph-deploy disk zap {osd-server-name}:{disk-name}
ceph-deploy disk zap osdserver1:sda3、PREPARE OSDS:
ceph-deploy osd prepare ceph-osd1:/dev/sda ceph-osd1:/dev/sdb4、activate the OSDs:
ceph-deploy osd activate ceph-osd1:/dev/sda1 ceph-osd1:/dev/sdb15、Use ceph-deploy to copy the configuration file and admin key to your admin node and your Ceph Nodes
so that you can use the ceph CLI without having to specify the monitor address and ceph.client.admin.keyring
each time you execute a command. ----->ceph-deploy admin {admin-node} {ceph-node}6、Ensure that you have the correct permissions for the ceph.client.admin.keyring.sudo chmod +r /etc/ceph/ceph.client.admin.keyring7、Check your cluster’s health.
ceph health/status
应为能看到:
root@ceph-mds:/home/megaium/myceph# ceph status
cluster 3734cac3-4553-4c39-89ce-e64accd5a043
health HEALTH_WARN
clock skew detected on mon.ceph-osd2
8 pgs degraded
8 pgs stuck degraded
72 pgs stuck unclean
8 pgs stuck undersized
8 pgs undersized
recovery1004/1506 objects degraded (66.667%)
recovery1/1506 objects misplaced (0.066%)
too few PGs per OSD (6 < min 30)
Monitor clock skew detected
monmap e1:2 mons at {ceph-osd1=192.168.2.242:6789/0,ceph-osd2=192.168.2.243:6789/0}
election epoch8, quorum 0,1 ceph-osd1,ceph-osd2
osdmap e135:24 osds: 24 up, 24 in; 64 remapped pgs
flags sortbitwise
pgmap v771:72 pgs, 2 pools, 1742 MB data, 502 objects
4405 MB used, 89256 GB / 89260 GB avail
1004/1506 objects degraded (66.667%)
1/1506 objects misplaced (0.066%)
64 active+remapped
8 active+undersized+degraded
root@ceph-mds:/home/megaium/myceph# ceph health HEALTH_WARN clock skew detected on mon.ceph-osd2; 8 pgs degraded; 8 pgs stuck degraded; 72 pgs stuck unclean; 8 pgs stuck undersized; 8 pgs undersized; recovery 1004/1506 objects degraded (66.667%); recovery 1/1506 objects misplaced (0.066%); too few PGs per OSD (6 < min 30); Monitor clock skew detected
4、验证命令:
ceph osd tree 查看状态 ceph osd dump 查看osd配置信息 ceph osd rm 删除节点 remove osd(s) <id> [<id>...] ceph osd crush rm osd.0 在集群中删除一个osd 硬盘 crush map ceph osd crush rm node1 在集群中删除一个osd的host节点 ceph -w / -s ceph mds stat 查看状态 ceph mds dump 查看状态
5、client端挂载磁盘
ceph-deploy install ceph-client ##安装ceph客户端
ceph-deploy admin ceph-client ##把秘钥及配置文件拷贝到客户端
rbs方式:
在客户端上应用ceph块存储 新建一个ceph pool [root@ceph-client ceph]# rados mkpool test 在pool中新建一个镜像 [root@ceph-client ceph]# rbd create test-1 --size 4096 -p test -m 10.240.240.211 -k /etc/ceph/ceph.client.admin.keyring (“-m 10.240.240.211 -k /etc/ceph/ceph.client.admin.keyring”可以不用加) 把镜像映射到pool块设备中 [root@ceph-client ceph]# rbd map test-1 -p test --name client.admin -m 10.240.240.211 -k /etc/ceph/ceph.client.admin.keyring (“-m 10.240.240.211 -k /etc/ceph/ceph.client.admin.keyring”可以不用加) 查看rbd的映射关系 [root@ceph-client ~]# rbd showmapped id pool image snap device 0 rbd foo - /dev/rbd0 1 test test-1 - /dev/rbd1 2 jiayuan jiayuan-img - /dev/rbd2 3 jiayuan zhanguo - /dev/rbd3 4 jiayuan zhanguo-5G - /dev/rbd4 把新建的镜像ceph块进行格式化 [root@ceph-client dev]# mkfs.ext4 -m0 /dev/rbd1 新建一个挂载目录 [root@ceph-client dev]# mkdir /mnt/ceph-rbd-test-1把新建的镜像ceph块挂载到挂载目录 [root@ceph-client dev]# mount /dev/rbd1 /mnt/ceph-rbd-test-1/查看挂载情况 [root@ceph-client dev]# df -h Filesystem Size Used Avail Use% Mounted on/dev/sda2 19G 2.5G 15G 15% /tmpfs 116M 72K 116M 1% /dev/shm/dev/sda1 283M 52M 213M 20% /boot/dev/rbd1 3.9G 8.0M 3.8G 1% /mnt/ceph-rbd-test-1完成上面的步骤就可以向新建的ceph文件系统中存数据了。
如果报错:
root@ceph-client:/home/megaium# rbd create mypool/myimage --size 1024002016-01-28 09:56:40.605656 7f56cb67f7c0 0 librados: client.admin authentication error (1) Operation not permitted rbd: couldn't connect to the cluster!
查看日志:
2016-01-27 22:44:17.755764 7ffb8a1fa8c0 0 mon.ceph-client does not exist in monmap, will attempt to join an existing cluster2016-01-27 22:44:17.756031 7ffb8a1fa8c0 -1 no public_addr or public_network specified, and mon.ceph-client not present in monmap or ceph.conf
需在mds端更改ceph.conf配置:
[global] fsid = 3734cac3-4553-4c39-89ce-e64accd5a043 mon_initial_members = ceph-osd1, ceph-osd2 mon_host = 192.168.2.242,192.168.2.243 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx filestore_xattr_use_omap = true osd pool default size = 2 public network = 192.168.2.0/24
然后下发配置及密钥: ceph-deploy --overwrite-conf ceph-osd1 ceph-osd2 ceph-client。
cephFS文件系统方式:
在客户端上建立cephFS文件系统 [root@ceph-client ~]# mkdir /mnt/mycephfs [root@ceph-client ~]# mount -t ceph 10.240.240.211:6789:/ /mnt/mycephfs -v -o name=admin,secret=AQDT9pNTSFD6NRAAoZkAgx21uGQ+DM/k0rzxow== 10.240.240.211:6789:/ on /mnt/mycephfs type ceph (rw,name=admin,secret=AQDT9pNTSFD6NRAAoZkAgx21uGQ+DM/k0rzxow==) #上述命令中的name和secret参数值来自monitor的/etc/ceph/keyring文件: [root@node1 ~]# cat /etc/ceph/ceph.client.admin.keyring [client.admin] key = AQDT9pNTSFD6NRAAoZkAgx21uGQ+DM/k0rzxow==
如有疑问,欢迎与我联系。