接触到AtomicLong的原因是在看guava的LoadingCache相关代码时,关于LoadingCache,其实思路也非常简单清晰:用模板模式解决了缓存不命中时获取数据的逻辑,这个思路我早前也正好在项目中使用到。
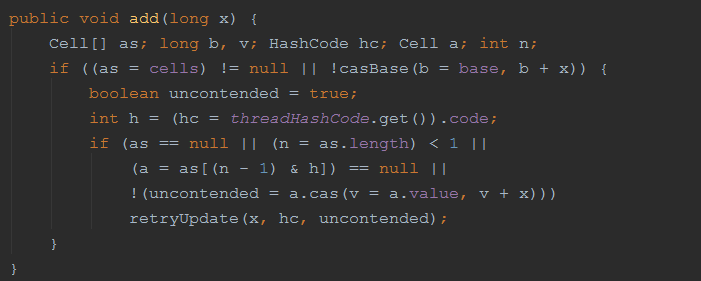
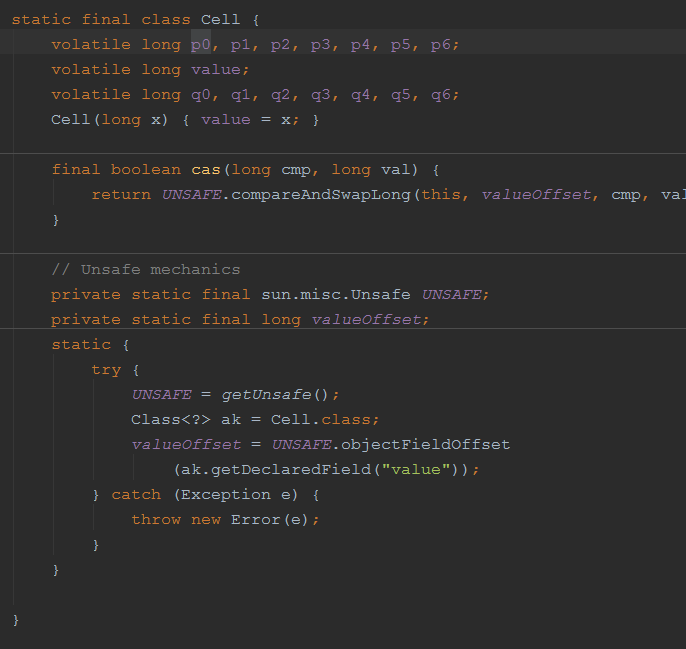

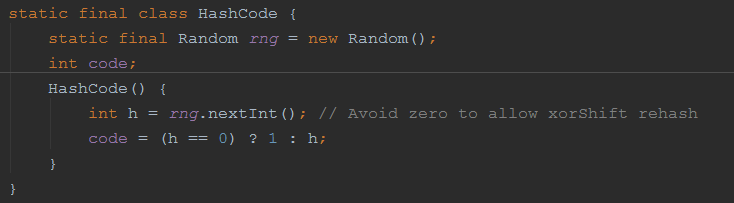
final void retryUpdate(long x, HashCode hc, boolean wasUncontended) {
int h = hc.code;
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {// 分支1
if ((a = as[(n - 1) & h]) == null) {
if (busy == 0) { // Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (busy == 0 && casBusy()) {
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
busy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
else if (a.cas(v = a.value, fn(v, x)))
break;
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
else if (!collide)
collide = true;
else if (busy == 0 && casBusy()) {
try {
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
busy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h ^= h << 13; // Rehash h ^= h >>> 17;
h ^= h << 5;
}
else if (busy == 0 && cells == as && casBusy()) {//分支2
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
busy = 0;
}
if (init)
break;
}
else if (casBase(v = base, fn(v, x)))
break; // Fall back on using base
}
hc.code = h; // Record index for next time
}
|
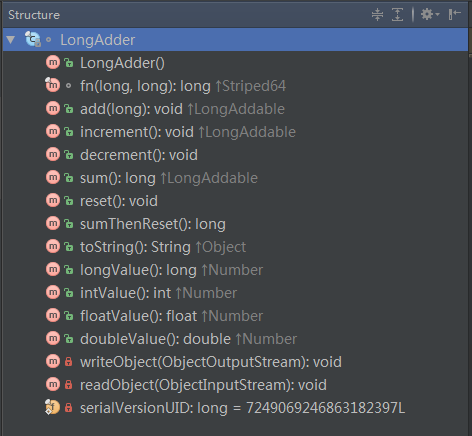
可以看到,LongAdder确实用了很多心思减少并发量,并且,每一步都是在”没有更好的办法“的时候才会选择更大开销的操作,从而尽可能的用最最简单的办法去完成操作。追求简单,但是绝对不粗暴。
————————————————分割线——————————————————————-
昨天在coolshell 投稿后 (文章在这里) 和左耳朵耗子简单讨论了下,发现左耳朵耗子对读者思维的引导还是非常不错的,在第一次发现这个类后,对里面的实现又提出了更多的问题,引导大家思考,值得学习,赞一个~
我们 发现的问题有这么几个:
1. jdk 1.7中是不是有这个类?
我确认后,结果如下: jdk-7u51版本上 上还没有 但是jdk-8u20 版本上已经有了。代码基本一样 ,增加了对double类型的支持和删除了一些冗余的代码。
2. base有没有参与汇总?
base在调用intValue等方法的时候是会汇总的:
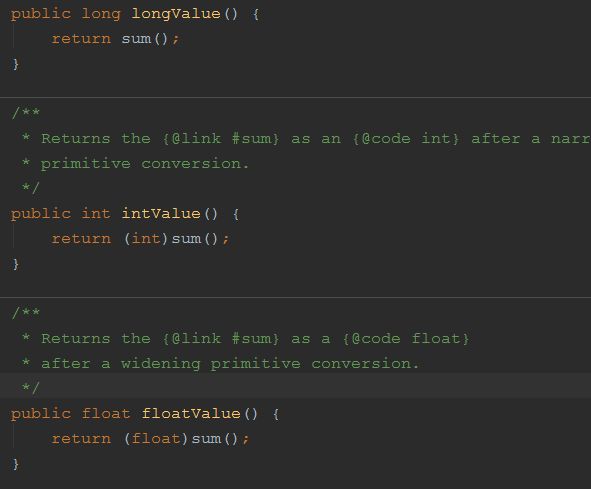
3. base的顺序可不可以调换?
左耳朵耗子,提出了这么一个问题: 在add方法中,如果cells不会为空后,casBase方法一直都没有用了?
因此,我想可不可以调换add方法中的判断顺序,比如,先做casBase的判断,结果是 不调换可能更好,调换后每次都要CAS一下,在高并发时,失败几率非常高,并且是恶性循环,比起一次判断,后者的开销明显小很多,还没有副作用。因此,不调换可能会更好。
4. AtomicLong可不可以废掉?
我的想法是可以废掉了,因为,虽然LongAdder在空间上占用略大,但是,它的性能已经足以说明一切了,无论是从节约空的角度还是执行效率上,AtomicLong基本没有优势了,具体看这个测试(感谢coolshell读者Lemon的回复):http://blog.palominolabs.com/2014/02/10/java-8-performance-improvements-longadder-vs-atomiclong/
原文地址: http://coolshell.cn/articles/11454.html