s
Loadrunner project 001
系统卡顿可能原因:项目卡顿,碰巧是JVM GC 在做Full GC时,应用会出现暂时性停顿。
解决方法:合理设计项目的场景应用,应用场景合理拆分。
Loadrunner project 002
性能压测上不去原因:可能JDBC 数据源连接池小了,不合理;可能线程池百把个线程设计小了,不合理。
解决方案:调调,再压测,OK。
Loadrunner project yunlin
apache + jboss + mysql
问题现象:TPS上不去 < 1000笔/秒
解决过程
重启 apache + jboss + mysql
压测 TPS 172笔/秒 , TIME 0.171秒
重启 apache + jboss + mysql 的redhat
压测 TPS 175笔/秒 , TIME 0.168秒
检查 apache 磁盘空间满了,我操...
压测 TPS 1679笔/秒 , TIME 0.018秒 (清空磁盘垃圾后,继续测得)
类似案例二 / 目录数或文件数海量,也会导致磁盘节点数满的原因就是 disk inode 不够用
http://jicc.cc/post/a-debug-story.html
一次曲折的bug调试经历
Fatal error: mysql error: [1: Can't create/write to file '/var/tmp/#sql_9469_0.MYI' (Errcode: 28)]
解决过程:
1。df -h 磁盘空间够用
2、df -i 进一步发现crontab 造成的邮件频繁发送导致邮件总数有200万居多,删除root帐户的垃圾邮件,取消发送邮件,ok。
[root@Loadrunner19 test]# find /var/spool/postfix/maildrop -type f | wc -l
统计下谁的目录下目录数或文件数最多,发现该目下有文件数180万,删除掉。
[root@Loadrunner19 test]# vim /etc/crontab
SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root # 原MAILTO=root 改为 MAILTO="" 即可禁止发邮件 HOME=/ # run-parts 01 * * * * root run-parts /etc/cron.hourly 02 4 * * * root run-parts /etc/cron.daily 22 4 * * 0 root run-parts /etc/cron.weekly 42 4 1 * * root run-parts /etc/cron.monthly
(linux文件系统里对文件数是有限制,虽然超过windows子目录或子文件数最大两三万句柄数的N倍,但也有极限值。)
终极解决此问题:需要上分布式文件系统,海量图片分布式或海量文件分布式系统
Loadrunner project zhongtai spes chuxiao
[WAS] Web container 设置不合适,导致sys cpu过高
http://wiki.cns*****.com/pages/viewpage.action?pageId=17404695
问题现象:
利用Load runner压测工具增加用户时,当用户数增加到一定数量(比如 单机50个用户)时,服务器cpu/sys 居高不下。
was_cpu_high_sys.jpg
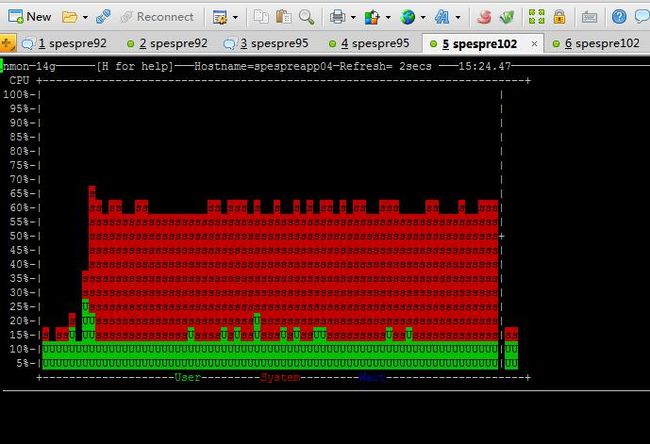
was_vmstat_cs_30万.jpg
http://dl2.iteye.com/upload/attachment/0113/0213/356d6215-8112-3ef4-82aa-28b9a6262f45.jpg

定位过程:
redis停用,直接查询DB时,
单台机器web container配置为20时,20用户WAS的CPU已经达到90%,再增加并发用户数都不会出现S高的情况。
3台机器时web container配置为20时,120用户时CPU为85%,再增加用户CPU无明显变化,且不会出现S高的情况。
当web container配置为50时,则出现了sys高的现象。
redis启用时,
wencontainer配置为50时,4台机器180用户的WAS的CPU已经达到80%,再增加用户CPU无明显变化。
wencontainer配置为80时,4台机器240用户的WAS的CPU已经达到90%。
总上对于8C8G配置的机器,直连DB查询时,我们的业务场景wencontainerd 配置为20比较合适,启用redis的场景时wencontainer 配置为50比较合适
我们的业务场景时使用redis的,当redis宕机时也要提高查询服务,所以个人建议我们生产的wencontainer配置为40比较合适
线程池 一般情况下 ,漏斗形 ,类似下面
web container 50 x 台数 > was pool 40 x 台数 >= db pool 30 x 台数
看 web 2 was ,看 was 2 db ,netstat 统计统计就可,理论模型的一种,跟据实际而定
Loadrunner project apache loadblance
033-Apache负载不均衡问题 loadblance
http://wiki.cns*****.com/pages/viewpage.action?pageId=26315529
1 关于Apache+Jboss+Mysql架构压测CPU波动问题----短时间大量连接
1.1 问题现象
Apache+Jboss+Mysql的架构模式,在压测过程中发现,几乎所有的系统都存在应用服务器CPU波动的情况。
多个尝试后,发现单压jboss,CPU还是比较稳定的,
只有经过Apache分发的,会出现类似问题。
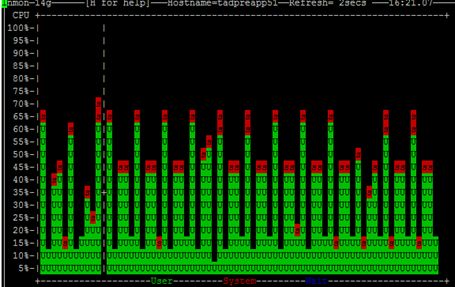
通过tcpdump抓包发现,该现象是由于apache的负载不均衡导致的:在某一时刻请求全部负载给1个机器,在另一时刻,请求负载给另一台机器,使得单台机器CPU发生周期性波动。

Tcpdump图1 Tcpdump图2
Tcpdump图1是测试刚开始的情况,此时apache的负载是在2台机器上轮流负载的。
Tcpdump图2是CPU波动时的情况,此时apache的负载是一段时间集中在1台机器,下一段时间集中的另一台机器。
经过对源码的debug发现,apache的负载不均衡是由于JBOSS提供的负载模块mod_proxy_cluster中,权重值参数的更新功能对多进程之间的竞争考虑不足引起的。
在高并发模式下,负载均衡算法中2个参数更新发生异常,导致负载均衡算法异常,后端Jboss服务器承载不均衡。直接表现为CPU发生定期波动。
1.3 解决方法
1.3.1 目前方法:已实施
调整apache配置,
加入 LBstatusRecalTime 1
说明:该功能定期更新负载均衡算法中的2个参数,默认值为5 (秒)
把这个值改成1,是为了在负载不平衡的情况刚发生时,就更新参数,重新计算权重值,
以此达到整体平衡的目的。
2 Post请求apache负载不均衡问题----长时间少量连接
2.1 问题现象
Apache+Jboss在测试过程中发现,一段时间后,大量负载都集中的1-2台Jboss上。
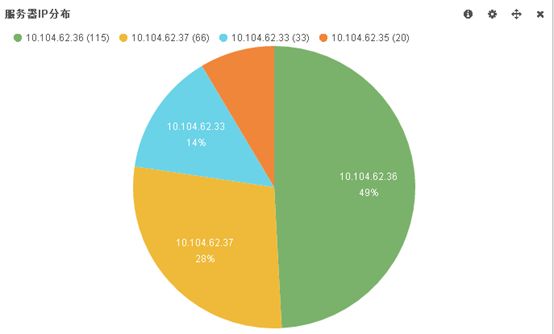
通过apache的debug日志发现,该现象是由于发包的间隔时间远大于LBstatusRecalTime的值引起的。
查找关键字” proxy: byrequests balancer DONE”,观察日志:
[Fri Sep 11 16:00:09 2015] [debug] mod_proxy_cluster.c(2221): proxy: byrequests balancer DONE (ajp://10.104.62.33:9109)
[Fri Sep 11 16:00:10 2015] [debug] mod_proxy_cluster.c(2221): proxy: byrequests balancer DONE (ajp://10.104.62.37:9109)
[Fri Sep 11 16:01:00 2015] [debug] mod_proxy_cluster.c(2221): proxy: byrequests balancer DONE (ajp://10.104.62.36:9109)
[Fri Sep 11 16:01:00 2015] [debug] mod_proxy_cluster.c(2221): proxy: byrequests balancer DONE (ajp://10.104.62.37:9009)
[Fri Sep 11 16:01:30 2015] [debug] mod_proxy_cluster.c(2221): proxy: byrequests balancer DONE (ajp://10.104.62.36:9109)
[Fri Sep 11 16:01:45 2015] [debug] mod_proxy_cluster.c(2221): proxy: byrequests balancer DONE (ajp://10.104.62.36:9109)
[Fri Sep 11 16:02:00 2015] [debug] mod_proxy_cluster.c(2221): proxy: byrequests balancer DONE (ajp://10.104.62.36:9109)
[Fri Sep 11 16:02:15 2015] [debug] mod_proxy_cluster.c(2221): proxy: byrequests balancer DONE (ajp://10.104.62.36:9109)
调整apache配置,
加入 LBstatusRecalTime 1200
说明:该功能定期更新负载均衡算法中的2个参数,默认值为5 (秒)
把这个值改成1200,是为了降低算法的执行频率,使请求到达的间隔时间低于算法执行的间隔时间,以此达到整体平衡的目

的。
end