mongodb从2.6 升级到3.0
本文主要介绍mongodb3.0的新特性,及具体由2.6 到3.0的升级过程。
mongodb3.0的新特性:参照(http://dataunion.org/12868.html) http://my.oschina.net/robinyao/blog/495807
1 插件式存储引擎API
类似mysql 的思想。 目前除了早期的MMAP存储引擎外,WiredTiger和 RocksDB 均 已完成了对MongoDB的支持,前者更是在被MongoDB公司收购后更是直接引入到了MongoDB 3.0版本中。插件式存储引擎API的引入为MongoDB丰富自己武器库以处理更多不同类型的业务提供了无限可能,内存存储引擎、事务存储引擎甚至 Hadoop在未来都有可能接入进来。
2WiredTiger存储引擎
MMAP存储引擎自身的天然缺陷(耗费磁盘空间和内存空间且难以清理,库级别锁)。
1文档级别并发控制: WiredTiger 通过MVCC(注解1)实现文档级别的并发控制,即文档级别锁。这就允许多个客户端请求同时更新一个集合内存的多个文档,再也不需要在排队等待 库级别的写锁。这在提升数据库读写性能的同时,大大提高了系统的并发处理能力。关于这一点的效果从监控工具mongostat就可以直接体现出来,旧版本 的监控指标会有locked db这一项(该项指标过高是mongo使用人员的一大痛点啊),而新版的mongostat已经看不到了。
2磁盘数据压缩: WiredTiger 支持对所有集合和索引进行Block压缩和前缀压缩(如果数据库启用了journal,journal文件一样会压缩),已支持的压 缩选项包括:不压缩、Snappy压缩和Zlib压缩。这为广大Mongo使用者们带来了又一福音,因为很多Mongo数据库都是因为MMAP存储引擎消 耗了过多的磁盘空间而不得已进行扩容。其中Snappy压缩为数据库的默认压缩方式,用户可以根据业务需求选择适合的压缩方式。理论上来说,Snappy 压缩速度快,压缩率OK,而Zlib压缩率高,CPU消耗多且速度稍慢。当然,只要选择使用压缩,Mongo肯定会占用更多的CPU使用率,但是thinking到 Mongo本身并不是十分耗CPU,所以启用压缩完全是值得的。 此 外,WiredTiger存储方式上也有很大改进。旧版本Mongo在数据库级别分配文件,数据库中的所有集合和索引都混合存储在数据库文件中,所以即 使删掉了某个集合或者索引,占用的磁盘空间也很难及时自动回收。WiredTiger在集合和索引级别分配文件,数据库中的所有集合和索引均存储在单独的 文件中,集合或者索引删除后,对应的存储文件随即删除。当然,因为存储方式不同,低版本的数据库无法直接升级到WiredTiger存储引擎,只能通过导 出导入数据的方式来实现。
MMAPv1存储引擎提升
MongoDB 3.0出了引入WiredTiger外,对于原有的存储引擎MMAP也进行了一定的完善,该存储引擎依然是3.0版的默认存储引擎。遗憾的是改进后的 MMAP存储引擎依旧在数据库级别分配文件,数据库中的所有集合和索引都混合存储在数据库文件中,所以磁盘空间无法及时自动回收的问题如故。
1、锁粒度由库级别锁提升为集合级别锁
这在一定程度上也能够提升数据库的并发处理能力。
2、文档空间分配方式改变
在 MMAP存储引擎中,文档按照写入顺序排列存储。如果文档更新后长度变长且原有存储位置后面没有足够的空间放下增长部分的数据,那么文档就要移动到文件 中的其他位置。这种因更新导致的文档位置移动会严重降低写性能,因为一旦文档发生移动,集合中的所有索引都要同步修改文档新的存储位置。
MMAP 存储引擎为了减少这种情况的发生提供了两种文档空间分配方式:基于paddingFactor(填充因子)的自适应分配方式和基于 usePowerOf2Sizes的预分配方式,其中前者为默认方式。第一种方式会基于每个集合中文档更新历史计算文档更新的平均增长长度,然后在新文档 插入或旧文档移动时填充一部分空间,如当前集合paddingFactor的值为1.5,那么一个大小为200字节的文档插入时就会自动在文档后填充 100个字节的空间。第二种方式则不thinking更新历史,直接为文档分配2的N次方大小的存储空间,如一个大小同样为200字节的文档插入时直接分配256个字 节的空间。
MongoDB 3.0版本中的MMAPv1抛弃了基于paddingFactor的自适应分配方式,因为这种方式看起来很智能,但是因为一个集合中的文档的大小不一,所 以经过填充后的空间大小也不一样。如果集合上的更新操作很多,那么因为记录移动后导致的空闲空间会因为大小不一而难以重用。目前基于 usePowerOf2Sizes的预分配方式成为默认的文档空间分配方式,这种分配方式因为分配和回收的空间大小都是2的N次方(当大小超过2MB时则 变为2MB的倍数增长),因此更容易维护和利用。如果某个集合上只有insert或者in-place update,那么用户可以通过为该集合设置noPadding标志位,关闭空间预分配。
下面介绍由2.6 升级到3.0 的过程。
升级过程
1搭建3.0 分片+副本 集群模式
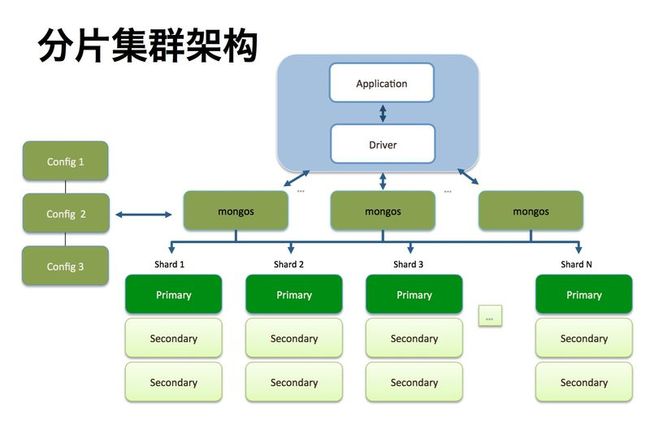
mongodb 集群一般是shard(分片)+ replicateSet(副本集)+mongos(路由)+config(配置服务)
shard :分片顾名思义就是把原本的数据放在一堆,现在分开放。可以分2堆 ,3 堆 ,n 堆,但是每堆之间的数据不能重复。
这样做的好事自然是可以把数据分别放到不同的机器上。
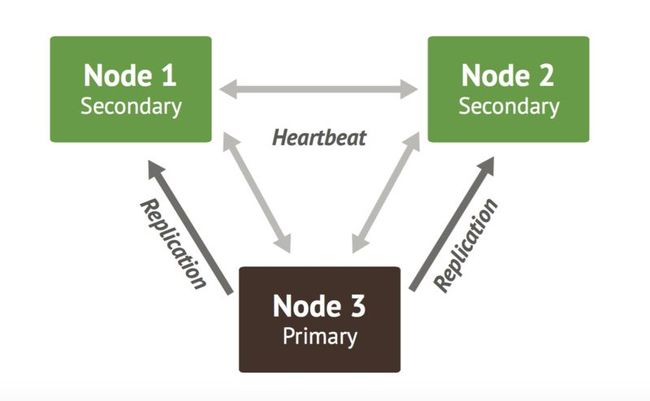
replicateSet: 副本集 ,如上图所示 shard1 分片下边有三个节点(Primary,Secondary,Secondary)。replicateSet 英文名字一看就是复制集合,把一个分片的数据重复拷贝几份。这样可以做到数据容灾,当主节点挂掉后,可以通过选举机制选出一个节点做主节点,集群仍可以正 常工作。工作机制如下图:
mongos :负责路由。所有的对mongodb集群 请求操作都有它来负责分发。一个集群中至少有一台mongos ,当然看自己心情,你可以多弄几台。这样在项目中用mongo 做为datasource 你就可以多配几个地址。一个路由挂掉了可以自动选择其他路由.
config: 配置服务器。负责记录集群中的配置信息,如一个集群由哪里分片组成,分片管理权限用户等等。
其实 分片 和副本集不是一定强求都要做,可以只用分片功能,或者只用副本集功能。
架构介绍完就是具体一步一步操作了
安装
大部分系统都可以直接下载压缩包,直接解压,添加相应的环境变量即可。
Ubuntu 用apt-get install 安装
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
sudo echo "deb http://repo.mongodb.org/apt/debian wheezy/mongodb-org/3.0 main" > /etc/apt/sources.list.d/mongodb-org.list
sudo apt-get update
sudo apt-get install -y mongodb-org=3.0.5 mongodb-org-server=3.0.5
mongodb-org-shell=3.0.5 mongodb-org-mongos=3.0.5 mongodb-org-tools=3.0.5
部署
我们部署采用3台服务器(每台机子 2个shard+config server+mongs)。从2.6起,mongodb的配置文件支持yaml格式。
shard1配置
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
systemLog:
destination: file
###日志存储位置
path: /XX/shard1.log
logAppend:
true
security:
keyFile: /XX/conf/mongo-keyfile
#
processManagement:
fork:
true
storage:
##journal配置
journal:
enabled:
true
##数据文件存储位置
dbPath: /XX/db/shard1/
##是否一个库一个文件夹
directoryPerDB:
true
##数据引擎
engine: wiredTiger
##WT引擎配置
wiredTiger:
engineConfig:
##WT最大使用cache(根据服务器实际情况调节)
cacheSizeGB:
3
##是否将索引也按数据库名单独存储
directoryForIndexes:
true
##表压缩配置
collectionConfig:
blockCompressor: snappy
##索引配置
indexConfig:
prefixCompression:
true
##端口配置
net:
port:
27117
##副本集
replication:
##oplog大小
oplogSizeMB:
2048
##复制集名称
replSetName: rs1
##分片
sharding:
##分片角色
clusterRole: shardsvr
|
shard2的配置就改下replSetName 和 端口。
config 配置
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
systemLog:
destination: file
###日志存储位置
path: /XX/logs/configsvr.log
logAppend:
true
#
processManagement:
fork:
true
security:
keyFile: /XX/conf/mongo-keyfile
storage:
##journal配置
journal:
enabled:
true
##数据文件存储位置
dbPath: /XX/db/config/
##数据引擎
engine: wiredTiger
##WT引擎配置
wiredTiger:
engineConfig:
##WT最大使用cache(根据服务器实际情况调节)
cacheSizeGB:
2
##是否将索引也按数据库名单独存储
directoryForIndexes:
true
##表压缩配置
collectionConfig:
blockCompressor: snappy
##索引配置
indexConfig:
prefixCompression:
true
##端口配置
net:
port:
28017
##分片
sharding:
##分片角色
clusterRole: configsvr
|
mongos配置
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
systemLog:
destination: file
###日志存储位置
path: /XX/logs/mongos.log
logAppend:
true
security:
keyFile: /XX/conf/mongo-keyfile
#
processManagement:
fork:
true
net:
port:
27017
##分片
sharding:
##config server
configDB: host1IP:
28017
,host2IP:
28017
,host3IP:
28017
|
三台机子的配置相同,直接scp 拷贝即可。
启动
三台机子先把分片和config 都启动,然后启动mongos
?
|
1
2
3
|
mongod --config conf/mongod_shard1.conf
mongod --config conf/mongod_shard2.conf
mongod --config conf/configsvr.conf
|
启动mongos
mongos --config conf/mongos.conf
配置分片副本集合
//shard1 shard2 都需要执行下边过程。
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
//连接到一个分片上
mongo <server1宿主ip>:
27117
//配置副本集
rs.initiate();
rs.add(“<server2宿主ip>:
27117
”);
rs.add(“<server3宿主ip>:
27117
”);
rs.status();
//Fix hostname of primary.
cfg = rs.conf();
cfg.members[
0
].host =
"<server1宿主ip>:21117"
;
rs.reconfig(cfg);
rs.status();
//以上命令一个一个执行
|
路由上添加分片
?
|
1
2
3
4
5
|
//连接到路由服务器
mongo <宿主ip>:
27017
sh.addShard(
"rs1/<宿主ip>:27017"
);
sh.addShard(
"rs2/<宿主ip>:27017"
);
sh.status();
|
添加用户和角色
以上启动过程都必须在非auth模式下启动的,配置中不要打开key-file选项(默认打开auth)。如果以auth模式打开,就不能配置用户和角色了,必须是配置完后,在加key-file选项(auth模式)打开。
直接登录到mongos 上:
?
|
1
2
|
use admin
//切换到admin数据库上
db.createUser({user:
"admin"
,pwd:
"pwd"
,roles: [ { role:
"root"
, db:
"admin"
} ]})
//这个角色是个超级角色,融合了很多权限。当然也可以把角色力度分开添加。
|
重新启动我们的mongo集群,然后在配置中加入key-file选项,以auth模式打开集群。
导数据
?
|
1
2
3
4
5
6
7
8
9
10
11
12
|
导出:
由旧的
2.6
直接导出
mongodump -u usename -p pwd -d dbname --out xxx/ &
导入:
mongoDB
3.0
兼容
2.6
导出的数据。
mongorestore -u username -p pwd --authenticationDatabase=dbname restore_data/ -j
1
&(一定要加-j 否者会把机器内存全部干了了)
以上命令在终端启动时最好加&,以后台进程启动(防止终端连接中断,过程被打断,数据量大,可能会持续几个小时…)
|
监控
?
|
1
2
3
4
5
|
1
mongostat -u admin -p pwd --authenticationDatabase=admin
2
tail -10f mongo.log
2
mongotop 不过不能用在mongos 只作用在具体的实例上。
|
其他
关闭mongoDB
千万不要 kill -9 pid,可以 kill -2 pid 或 db.shutdownServer()
程序驱动
spring-data spring-mongo 升级 ,datasource 配置也需要改变。有些类型映射需要手工转换(java.util.Date, java.sql.Date)
转发标注:http://my.oschina.net/robinyao/blog/495807 http://my.oschina.net/robinyao/blog/495807
注解1:MVCC(mulit-version concurrency Control)多版本并发控制 机制,大多数的MySQL事务型存储引擎,如InnoDB,都不使用一种简单的行锁机制。事实上,他们都和另外一种用来增加并发性的被称为“多版本并发控制(MVCC)”的机制来一起使用。MVCC不只使用在MySQL中,Oracle、PostgreSQL,以及其他一些数据库系统也同样使用它。你可将MVCC看成行级别锁的一种妥协,它在许多情况下避免了使用锁,同时可以提供更小的开销。根据实现的不同,它可以允许非阻塞式读,在写操作进行时只锁定必要的记录。