Ogre2.0 全新功能打造新3D引擎
不知当初是在那看到,说是Ogre2.0浪费了一个版本号,当时也没多想,以为没多大更新,一直到现在想做一个编辑器时,忽然想到要看下最新版本的更新,不看不知道,一看吓一跳,所以说,网络上的话少信,你不认识别人,别人张嘴就来,对别人也没损失,还可以装B下,靠.
从现在Ogre2.1的代码来看,大约总结下,更新包含去掉过多的设计模式,SoA的数据结构(用于SIMD,DOD),新的线程模式,新的渲染流程与场景更新,新的材质管理系统,新的模型格式,新的合成器方案,更新是全方面的,可以说,Ogre2.x与Ogre1.x完全不是同一个引擎,不管是效率,还是从渲染新思路的使用上.
大体上参照二份主要文档,一份是OGRE.2.0.Proposal.Slides.odp,现在Ogre的维护者之一dark_sylinc比对其他的引擎以及相关测试写的Ogre2.0要修改的方向,一是Ogre 2.0 Porting Manual DRAFT.odt,移植手册,简单来说,Ogr2.0具体的修改位置与说明.非常有价值的二份文档,可以说,这是全新Ogre改动的精华,我们从这二份文档里,能学到如何针对C++游戏引擎级别的包含效率,可用性的重构.这是一个幸运的学习经历.
从https://bitbucket.org/sinbad/ogre下载最新版本,里面的DOC文件夹,有多份文档,我整理了下,每部分包含改动原因,改动位置,相关代码来说,因为全是英文文档,所以如果理解有错误,欢迎大家指出,不希望误导了大家.本文只针对新模型新功能,也就是加了v1命名空间的(Ogre1.x中的功能,有对应Ogre2.x版本),本文不会特别说明.
Ogre1.x中问题与建议
Cache末命中
看看作者的幻灯片,哈哈,图片特别形象生动.
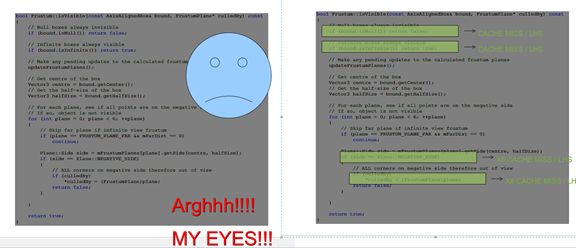
这个是函数是判断模型是否在当前摄像机可见,如果可见,加入渲染通道.不过你去看现在的Ogre2.1的代码,这个方法没有变,不是因为没有改,是因为渲染流程变了,这个函数的功能被MovableObject::cullFrustum包含了,其中判断摄像机与模型AABB相交的算法也换了.
这个函数因为每桢都对每个模型来计算,如果Cache misses,损失有点大.

同样这个一般用来得到模型的世界坐标位置,也是每桢每个模型要计算的,如果Cache miss,同上.
那么如何改进,像上面,你不要那些判断,要么多计算,要么结果不对,作者给出的答案就是改进渲染流程,减少判断条件的出现.后面会细说.
低效的场景遍历和操作.

可以看到场景每次更新都在重复,检查是否需要更新,然后更新.很多不必要的变量和是否更新状态的跟踪,以及太多的判断,分别造成cache misses缓存不友好.(我去,if判断有这么大的破坏力?还是只是引擎级别的代码才会造成这样的影响,后面渲染流程中,原来很多if都去掉了).
然后指出Ogre的渲染流程中,其中SceneManager::_renderScene()调用太多次,如Shadow Map一次,合成器中的render_scene一次,然后他们还没有重复使用剔除的数据,每次renderScene,都重新剔除了一次.特别是合成器中多次调用render_scene,每次都会把渲染队列里的模型全部检查剔除一次,这是无效的操作.
综合这二点,渲染队队肯定要大改,如下是作者综合别的商业渲染引擎,给出的在Ogre2.0中新的实现建议,根据现在Ogre2.1我所看到的代码,已经实现如下图的功能.
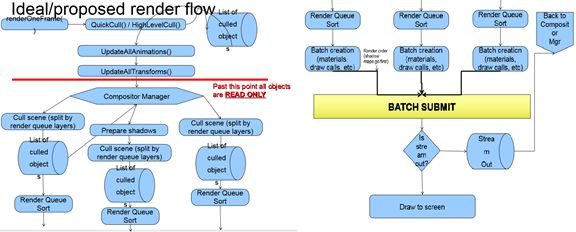
这个图后面会简单说下其中的线程相关部分,这就是Ogre2.x的渲染流程了,从图中,我们可以看到新的合成器是Ogre核心中的一部分,已经不是可选组件了,当然新的合成器也有相当大的更新,功能更强大,更好用.其中更详细的部分,后面会专门写一篇介绍Ogre2.x新的渲染流程与合成器.
SIMD,DOD,SoA
在看如下内容时,先介绍一下什么是基于DOD的设计.DOD(面向数据设计),以及我们面向对象OOP常用的OOD(面向对象设计)
DOD与OOD之争: Data oriented design vs Object oriented design

Data-Oriented Design Data-Oriented Design 二 什么是DOD,为什么要使用DOD,什么情况下用DOD
[译]基于数据的设计(Data-oriented design) 这是CSDN上针对第一篇的翻译
有兴趣大家仔细读下,这里总结下DOD相对OOP的优势.简洁高效的并行化,缓存友好.
先看如下 http://stackoverflow.com/questions/12141626/data-oriented-design-in-oop 中提出的一个问题,二代码如下:
//DOD void updateAims(float* aimDir, const AimingData* aim, vec3 target, uint count) { for(uint i = 0; i < count; i++) { aimDir[i] = dot3(aim->positions[i], target) * aim->mod[i]; } } //OOP class Bot { vec3 position; float mod; float aimDir; void UpdateAim(vec3 target) { aimDir = dot3(position, target) * mod; } }; void updateBots(Bots* pBots, uint count, vec3 target) { for(uint i = 0; i < count; i++) pBots[i]->UpdateAim(target); } };
下面有人解释为什么第一段代码要高效,在第二段代码中,每次得到一个结构域,浪费更多带宽,以及更新无用数据到缓存中,缓存Miss高.第一种一次取一个float块,提高缓存有效利用.
如在游戏中最常见的操作,取得每个模型的MVP矩阵,而OOP告诉我们,要取的位置,先要取得模型.模型还包含许多其它的内容,但是是无用的,占用缓存空间,缓存命中变低.而DOD是把所有的字段存放在一起,一下取的所有位置,请看下面SoA.
下面再次提出二个概念,一个是SoA(Structure of Arrays,非你百度搜出来的SOA),一个是AoS(Arrays of Structure),暂时先说下,SoA是一种DOD里常用的数据组织方式,对应OOP里常用的AoS组织方法.

简单说下,SoA的组织方式,是把一组元素的每个字段连续保存,如下是我针对Ogre2.x里的代码改写的.
struct Vector3 { float x = 0; float y = 0; float z = 0; Vector3() { } Vector3(float nx, float ny, float nz) { x = nx; y = ny; z = nz; } float& operator [] (const size_t i) { assert(i >= 0 && i < 3); return *(&x + i); } }; struct Quaternion { float x; float y; float z; float w; }; //OOD 面向对象设计 struct Transform { Vector3 pos; Vector3 scale; Quaternion orient; void move(Vector3 move) { for (int i = 0; i < 3; i++) { pos[i] += move[i]; } } }; //SIMD struct ArrayVector3 { float x[4]; float y[4]; float z[4]; ArrayVector3() { memset(x, 0, sizeof(float)* 4); memset(y, 0, sizeof(float)* 4); memset(z, 0, sizeof(float)* 4); } Vector3 getIndex(int index) { assert(index >= 0 && index < 4); return Vector3(x[index], y[index], z[index]); } void setIndex(int index, float fx, float fy, float fz) { assert(index >= 0 && index < 4); x[index] = fx; y[index] = fy; z[index] = fz; } }; struct ArrayQuaternion { float x[4]; float y[4]; float z[4]; float w[4]; }; //SoA(Structure of Arrays) struct ArrayTransformSoA { ArrayVector3* pos; ArrayVector3* scale; ArrayQuaternion* orient; int mIndex = 0; ArrayTransformSoA() { pos = new ArrayVector3(); scale = new ArrayVector3(); orient = new ArrayQuaternion(); } ~ArrayTransformSoA() { delete pos; delete scale; delete orient; } void move(Vector3 move) { //xxxxyyyyzzzz float *soa = reinterpret_cast<float*>(pos); for (int i = 0; i < 3; i++) { for (int j = 0; j < 4; j++) { soa[i * 4 + j] += move[i]; } } } void setPos(float x, float y, float z) { pos->setIndex(mIndex, x, y, z); } Vector3 getPos() { return pos->getIndex(mIndex); } }; void SoAVAoS() { //AoS(Arrays of Structure) Transform aosArray[4]; ArrayTransformSoA soaArray; Vector3 moveAdd(4.0f, 2.0f, 1.0f); for (int i = 0; i < 4; i++) { aosArray[i].move(moveAdd); } soaArray.move(moveAdd); for (int i = 0; i < 4; i++) { cout << aosArray[i].pos.x << endl; soaArray.mIndex = i; cout << soaArray.getPos().x << endl; } cout << "" << endl; }
下面的ArrayVector3和ArrayTransformSoA就是SoA相关组织方式与操作,这里上面注释写的是SIMD,因为这个组织方式确实是用于SIMD的,SIMD在这不多说,如果有机会,专门研究这个后再来详细说明,在这,我们只需要知道SSM2可以每下处理128位数据,在32位下,每下处理4个float数据,如上面的ArrayTransformSoA中的move方法中,第二个循环中对于使用SSM2指令来说,就是一个指令,简单来说速度提高4倍,可以说是一种最简单安全的并行处理,不要你来设线程,关心同步啥的.更具体点的说,在游戏中一下可以处理四个顶点进行操作,如移动,缩放,以及矩阵运算(当然这四个顶点也有限制,并不是所有都放一起,请看后面).同时如上图所示,这也是缓存友好的.
上面演示了常见SoA结构方法,可以看到,对于对象来说,他的存放不再是连续的了,如点的位置y和x相关了4*sizeof(float)个距离,在面向对象结构中,他们应该是相邻的.但是对于SoA来说,对象列表中的每个字段是相邻的,如上图所示应该是XXXXYYYYZZZZ这种内存布局方式,而不是XYZXYZXYZXYZ这种.前面说过,DOD也常用SoA结构,那这是不是就是Ogre中的DOD核心设计,不算,因为这种四个一组的只是专门为了SIMD的SoA结构,真正的DOD核心应该Ogre中的ArrayMemoryManager类,直接拖出这个方法可能看不明白,如下是我针对Ogre2.x中的ArrayMemoryManager改写的,只保留核心帮助大家理解.
//DOD 面向数据设计 class ArrayTransformManager { private: enum ElementType { Pos, Scale, Orient, ElementCount }; int elements[ElementCount]; vector<char*> memoryPool; int totalSize = 0; int maxMemory = 32; //当前 int nextSlot = 0; public: ArrayTransformManager() { elements[Pos] = 3 * sizeof(float); totalSize += elements[Pos]; elements[Scale] = 3 * sizeof(float); totalSize += elements[Scale]; elements[Orient] = 4 * sizeof(float); totalSize += elements[Orient]; memoryPool.resize(ElementCount); } void initialize() { for (int i = 0; i < ElementCount; i++) { int byteCount = elements[0] * maxMemory; memoryPool[i] = new char[byteCount]; memset(memoryPool[i], 0, byteCount); } } void createArrayTransform(ArrayTransformSoA &outTransform) { int current = nextSlot++; //current = 0,nextSlotIdx = 0,nextSlotBase = 0 //current = 3,nextSlotIdx = 3,nextSlotBase = 0 //current = 4,nextSlotIdx = 0,nextSlotBase = 4 //current = 5,nextSlotIdx = 1,nextSlotBase = 4 //current = 7,nextSlotIdx = 3,nextSlotBase = 4 //current = 8,nextSlotIdx = 0,nextSlotBase = 8 int nextSlotIdx = current % 4; int nextSlotBase = current - nextSlotIdx; outTransform.mIndex = nextSlotIdx; outTransform.pos = reinterpret_cast<ArrayVector3*>( memoryPool[Pos] + nextSlotBase*elements[Pos]); outTransform.scale = reinterpret_cast<ArrayVector3*>( memoryPool[Scale] + nextSlotBase*elements[Scale]); outTransform.orient = reinterpret_cast<ArrayQuaternion*>( memoryPool[Orient] + nextSlotBase*elements[Orient]); outTransform.setPos(nextSlotIdx, nextSlotIdx, nextSlotIdx); } }; void TestDOD() { ArrayTransformManager transformDOD; transformDOD.initialize(); ArrayTransformSoA transform0; transformDOD.createArrayTransform(transform0); ArrayTransformSoA transform1; transformDOD.createArrayTransform(transform1); ArrayTransformSoA transform2; transformDOD.createArrayTransform(transform2); ArrayTransformSoA transform3; transformDOD.createArrayTransform(transform3); ArrayTransformSoA transform4; transformDOD.createArrayTransform(transform4); cout << transform0.getPos().x << endl; cout << transform1.getPos().x << endl; cout << transform2.getPos().x << endl; cout << transform3.getPos().x << endl; cout << transform4.getPos().x << endl; }
这个是结合了SMID的DOD设计,不看SMID部分,就看初始化部分,maxMemory表示最多存入多少个Transform,而elements表示Transform对应每个字段占多少位,memoryPool表示每个字段(连续的)在一起占多少个字段,其中调用createArrayTransform生成一个ArrayTransformSoA数据,每四个连续的ArrayTransformSoA的里的如Pos,Scale等地址一样,如上面那种图,不同的是对应mIndex,用于指明是当前在SoA中的索引.其实对比上面的ArrayVector3来看,组织数据应该算是一样的,不同之处是一下并排放maxMemory个数据,而ArrayVector3一下放四个vector3数据.总的来说,这就是SoA数据结构,分别用于SIMD与DOD.
幻灯片文档第一点与第二点主要包含二点,一是渲染流程(后文细说),二是SMID,DOD等基本数据格式与操作的改变.后面关于顶点格式与着色器先暂时不说了,大家有兴趣可以看下,对应代码还没查到,不知是否已经完成.
最后结束,还不忘指出Ogre中的设计模式被过度使用,说明OOD的多态太浪费,并且用宏来控制一些virtual_l0 ,virtual_l1 ,virtual_l2 来控制多态级别,默认已经不启用虚函数,如SceneNode::getPosition(),SceneNode::setPosition默认不能重载,如果定义了SceneNode的子类,并重载了如上函数,你需要自己设定多态级别,并自己编译.嗯,Ogre1.x最出名的多设计模式使用也随着渲染流程的改变而去掉很多.相信大家看到相关更新后,都会说这改的太大了吧.
"We don't care really how long it takes" Ogre采用OOD带来的好处,在客户级别上的.
Ogre2.x移植手册:
模型,场景和节点:
1.Ogre2.0后,Ogre很多对象去掉name,改用IdObejct,这个更多意义就是很多原来的聚合关系都是用的map来表示,name当key,现在为IdObejct,且为自动生成,所以相关id意思不大,相关聚合关系用的是Ogre开发人员自己写的一个轻量级仿vector的类FastArray.
The Sorted Vector pattern Part I
The Sorted Vector pattern Part II
因为我们场景中,更多如更新所有模型的位置,AABB等,能快速迭代是我们最大的要求,并且vector更节省空间,内存块连续(AoS,SMID,DOD).相反,map的优势如快速查找,随机删除与添加并不常用.所以像Ogre1.x中很多map的用法并不明智.
其中,Ogre内部更多聚合关系使用的是FastArray,FastArray是针对std::vector的轻量级实现,去掉了其中的大量边界检查与迭代器验证.沿用大部分std::vector的功能,如std::for_each正常工作,也有同标准不一样的,如FastArray<int> myArray(5),不会自动初始化这里面的5个数据是0.注释中默认不建议我们用,因为如前面所说,和标准std::vector不同,这个类主打效率,针对边界检查与相关验证全部去掉,除非我们知道我们应该怎么用.
2.如何查看如MovableObject与Node里的数据.
认真看过前面SoA部分的,这部分都不用细说了,Node里的位置信息用Transform保存,MovableObject的信息用ObjectData保存,对应的信息是四个一组用于SIMD指令加速,所以一个Node对应的Transform其实有4个Transform信息,这4个Transform位置在内存中数据如下XXXXYYYYZZZZ,根据Transform的mIndex(0,4]找出对应数据.
避免SIMD不能正常计算,以及大量的非空判断,Transform中如果只有三个node,最后一个node不设为null,为虚拟指针代替,这也是DOD常用的一个方法.
3.在Ogre1.x中,MovableObject只有附加到SceneNode后,才算是在场景中,而Ogre2.x就没有这个概念了,Node只算是MovableObject用来操作与保存相关位置信息.其实说起来,应该是和渲染流程的改变有变,原来的渲染流程中,通过Node一级一级查找下去所有的MoveableObject是否在视截体范围内,而现在生成一个MovableObject后,在对应的ObjectMemoryManager(同前面所讲,分配SoA结构) 保留指针,而在场景进行剔除时,根据ObjectMemoryManager来的,所以说MovableObject一直在场景中.但是Node保留位置信息,没有位置信号,一样不能在场景中渲染.
在Attaching/Detaching操作后,会自动调用对应setVisible,Attaching后,自动设visible为true,也可以设为flase,Detaching后,自动设visible为false,如果手动设true,会出现错误.
如果你Attaching一个SceneNode后,你再次Attaching另一个SceneNode时,需要先Detaching.否则断言错误.
4.所有的MovableObject都需要SceneNode,包含灯光与摄像机,所有的都需要附加到SceneNode中才行,很简单,原来如Light与Camera与一般的MovableObject有些区别,一是不渲染自己,二是有自己的位置信息,但是现在SceneNode不用于渲染通道,只是保存位置信息,自然和一般的MovableObject一样用SceneNode来保存位置信息了,灯光与摄像机也都必须附加到SceneNode上才有位置信息.
5. 改变Node的局部坐标位置,并不能马上得到对应的全局位置.不同于Ogre1.x版本,如setPosition会设置一个flag表示父节点要更新,而调用getDerivedPosition后,检查到flag就去更新父节点了.这是一个不友好的Cache设计.在Ogre2.x中,去掉了上面的一些flag,更新不会更新父节点,所有节点的更新都在每桢中的updateAllTransforms,就是说如果你setPosition后,你需要当前桢运行之后(调用updateAllTransforms)后才能得到getDerivedPosition的正确值.当然如果你一定现在要,可以用getDerivedPositionUpdated,当然这就是走老路了,如果可能,请更新你的设计.同时原Ogre1.x中的getDerivedPosition在Ogre2.x分成了二个方法,也去掉了if判断.
6.Node和MovableObject区分成动态与静态,静态就是告诉Ogre,我不会每桢去更新位置.这样Ogre能做的优化一是节省CPU,不用每桢去更新相应位置和相应AABB,二是告诉GPU,某些模型可以合并批次渲染.其中动态模型只能附加到动态节点上,静态模型只能附加到静态模型上.动态节点可以包含静态子节点,而静态节点不可以包含动态子节点(根节点除外),原因很简单,静态节点不常更新,你放个动态子节点在我里面,是让我更新了还是不更新了.
7.在Ogre2.0以前,我们知道最后用于渲染的只是Renderable与Pass,其中在场景可见性检查模型时, MovableObject把当下的所有Renderable加入RenderQueue,用户可以不通过MovableObject也能把Renderable加入RenderQueue,在Ogre2.1后,必需把Renderable与对应的MovableObject一起加入RenderQueue,因为新的渲染系统中的渲染模型,渲染中要求的Lod等级,骨骼动画,MVP矩阵等都直接保存在MovableObject.就如Ogre2.1以后MVP矩阵是直接保存在对应MovableObject中,不再是通过Renderable的getWorldTransforms获取.详细请查看相关QueuedRenderable引用相关信息.
此外去掉原Ogre2.0在场景可见性检查时要得到是否可以接收阴影用到的访问者模式,让修改的人来说,这个模式花费太大,不值得.当然Ogre2.0以后的阴影相关全部改变,只支持shadow map,以及shadow map很多变种技术.模版阴影去掉支持,可以看到MovableObject不再是ShadowCaster的子类,这个类包装模版阴影相关.
再一个就是新模型和VAO的引进,原来的VBO的类也改成相应VaoManager.具体后文详细分析.
SIMD,DOD,Thread:
SIMD与DOD设计前面有说,在这里,只是简单说几个类.所在文件都在OgreMain/Math/Array/SSE2下.
如下这段代码是前面我说的针对Ogre2.x中抽取的,主要是根据相关Ogre中SIMD与DOD设计中改写的,帮助理解.
//SIMD struct ArrayVector3 { float x[4]; float y[4]; float z[4]; ArrayVector3() { memset(x, 0, sizeof(float)* 4); memset(y, 0, sizeof(float)* 4); memset(z, 0, sizeof(float)* 4); } Vector3 getIndex(int index) { assert(index >= 0 && index < 4); return Vector3(x[index], y[index], z[index]); } void setIndex(int index, float fx, float fy, float fz) { assert(index >= 0 && index < 4); x[index] = fx; y[index] = fy; z[index] = fz; } }; struct ArrayQuaternion { float x[4]; float y[4]; float z[4]; float w[4]; }; //SoA(Structure of Arrays) struct ArrayTransformSoA { ArrayVector3* pos; ArrayVector3* scale; ArrayQuaternion* orient; int mIndex = 0; ArrayTransformSoA() { pos = new ArrayVector3(); scale = new ArrayVector3(); orient = new ArrayQuaternion(); } ~ArrayTransformSoA() { delete pos; delete scale; delete orient; } void move(Vector3 move) { //xxxxyyyyzzzz float *soa = reinterpret_cast<float*>(pos); for (int i = 0; i < 3; i++) { for (int j = 0; j < 4; j++) { soa[i * 4 + j] += move[i]; } } } void setPos(float x, float y, float z) { pos->setIndex(mIndex, x, y, z); } Vector3 getPos() { return pos->getIndex(mIndex); } }; void SoAVAoS() { //AoS(Arrays of Structure) Transform aosArray[4]; ArrayTransformSoA soaArray; Vector3 moveAdd(4.0f, 2.0f, 1.0f); for (int i = 0; i < 4; i++) { aosArray[i].move(moveAdd); } soaArray.move(moveAdd); for (int i = 0; i < 4; i++) { cout << aosArray[i].pos.x << endl; soaArray.mIndex = i; cout << soaArray.getPos().x << endl; } cout << "" << endl; } //DOD 面向数据设计 class ArrayTransformManager { private: enum ElementType { Pos, Scale, Orient, ElementCount }; int elements[ElementCount]; vector<char*> memoryPool; int totalSize = 0; int maxMemory = 32; //当前 int nextSlot = 0; public: ArrayTransformManager() { elements[Pos] = 3 * sizeof(float); totalSize += elements[Pos]; elements[Scale] = 3 * sizeof(float); totalSize += elements[Scale]; elements[Orient] = 4 * sizeof(float); totalSize += elements[Orient]; memoryPool.resize(ElementCount); } void initialize() { for (int i = 0; i < ElementCount; i++) { int byteCount = elements[0] * maxMemory; memoryPool[i] = new char[byteCount]; memset(memoryPool[i], 0, byteCount); } } void createArrayTransform(ArrayTransformSoA &outTransform) { int current = nextSlot++; //current = 0,nextSlotIdx = 0,nextSlotBase = 0 //current = 3,nextSlotIdx = 3,nextSlotBase = 0 //current = 4,nextSlotIdx = 0,nextSlotBase = 4 //current = 5,nextSlotIdx = 1,nextSlotBase = 4 //current = 7,nextSlotIdx = 3,nextSlotBase = 4 //current = 8,nextSlotIdx = 0,nextSlotBase = 8 int nextSlotIdx = current % 4; int nextSlotBase = current - nextSlotIdx; outTransform.mIndex = nextSlotIdx; outTransform.pos = reinterpret_cast<ArrayVector3*>( memoryPool[Pos] + nextSlotBase*elements[Pos]); outTransform.scale = reinterpret_cast<ArrayVector3*>( memoryPool[Scale] + nextSlotBase*elements[Scale]); outTransform.orient = reinterpret_cast<ArrayQuaternion*>( memoryPool[Orient] + nextSlotBase*elements[Orient]); outTransform.setPos(nextSlotIdx, nextSlotIdx, nextSlotIdx); } }; void TestDOD() { ArrayTransformManager transformDOD; transformDOD.initialize(); ArrayTransformSoA transform0; transformDOD.createArrayTransform(transform0); ArrayTransformSoA transform1; transformDOD.createArrayTransform(transform1); ArrayTransformSoA transform2; transformDOD.createArrayTransform(transform2); ArrayTransformSoA transform3; transformDOD.createArrayTransform(transform3); ArrayTransformSoA transform4; transformDOD.createArrayTransform(transform4); cout << transform0.getPos().x << endl; cout << transform1.getPos().x << endl; cout << transform2.getPos().x << endl; cout << transform3.getPos().x << endl; cout << transform4.getPos().x << endl; }
1.ArrayVector3 对应ArrayVector3.是SIMD要求的SoA结构,用于使用SSE2指令.
2.Transform 对应ArrayTransformSoA.用于Node的位置信息.
3.ArrayMemoryManager对应ArrayTransformManager.用于生成DOD数据结构内存排列.
当然ArrayMemoryManager本身的功能要复杂的多,如删除插槽,追踪已被删除插槽,添加时自动选择删除插槽,队列中空白插槽太多后的自动清理.模拟的ArrayTransformManager都是没有的.
线程在Ogre2.x中再也不是一个可有可无的功能,也不是一个玩具,也不是简单的逻辑一个线程,渲染一个线程这种简单用法.因为Ogre2.x中使用位置太多,如下只列出SceneManager::updateSceneGraph()中关于新的线程的使用,我们来看下基本情况.
先看如下代码.
void SceneManager::startWorkerThreads() { #if OGRE_PLATFORM != OGRE_PLATFORM_EMSCRIPTEN mWorkerThreadsBarrier = new Barrier( mNumWorkerThreads+1 ); mWorkerThreads.reserve( mNumWorkerThreads ); for( size_t i=0; i<mNumWorkerThreads; ++i ) { ThreadHandlePtr th = Threads::CreateThread( THREAD_GET( updateWorkerThread ), i, this ); mWorkerThreads.push_back( th ); } #endif } unsigned long updateWorkerThread( ThreadHandle *threadHandle ) { SceneManager *sceneManager = reinterpret_cast<SceneManager*>( threadHandle->getUserParam() ); return sceneManager->_updateWorkerThread( threadHandle ); } THREAD_DECLARE( updateWorkerThread ); unsigned long SceneManager::_updateWorkerThread( ThreadHandle *threadHandle ) { #if OGRE_PLATFORM != OGRE_PLATFORM_EMSCRIPTEN size_t threadIdx = threadHandle->getThreadIdx(); while( !mExitWorkerThreads ) { mWorkerThreadsBarrier->sync(); if( !mExitWorkerThreads ) { #else size_t threadIdx = 0; #endif switch( mRequestType ) { case CULL_FRUSTUM: cullFrustum( mCurrentCullFrustumRequest, threadIdx ); break; case UPDATE_ALL_ANIMATIONS: updateAllAnimationsThread( threadIdx ); break; case UPDATE_ALL_TRANSFORMS: updateAllTransformsThread( mUpdateTransformRequest, threadIdx ); break; case UPDATE_ALL_BOUNDS: updateAllBoundsThread( *mUpdateBoundsRequest, threadIdx ); break; case UPDATE_ALL_LODS: updateAllLodsThread( mUpdateLodRequest, threadIdx ); break; case UPDATE_INSTANCE_MANAGERS: updateInstanceManagersThread( threadIdx ); break; case BUILD_LIGHT_LIST01: buildLightListThread01( mBuildLightListRequestPerThread[threadIdx], threadIdx ); break; case BUILD_LIGHT_LIST02: buildLightListThread02( threadIdx ); break; case USER_UNIFORM_SCALABLE_TASK: mUserTask->execute( threadIdx, mNumWorkerThreads ); break; default: break; } #if OGRE_PLATFORM != OGRE_PLATFORM_EMSCRIPTEN mWorkerThreadsBarrier->sync(); } } #endif return 0; } void SceneManager::fireWorkerThreadsAndWait(void) { #if OGRE_PLATFORM == OGRE_PLATFORM_EMSCRIPTEN _updateWorkerThread( NULL ); #else mWorkerThreadsBarrier->sync(); //Fire threads mWorkerThreadsBarrier->sync(); //Wait them to complete #endif } void SceneManager::updateSceneGraph() { //TODO: Enable auto tracking again, first manually update the tracked scene nodes for correct math. (dark_sylinc) // Update scene graph for this camera (can happen multiple times per frame) /*{ // Auto-track nodes AutoTrackingSceneNodes::iterator atsni, atsniend; atsniend = mAutoTrackingSceneNodes.end(); for (atsni = mAutoTrackingSceneNodes.begin(); atsni != atsniend; ++atsni) { (*atsni)->_autoTrack(); } // Auto-track camera if required camera->_autoTrack(); }*/ OgreProfileGroup("updateSceneGraph", OGREPROF_GENERAL); // Update controllers ControllerManager::getSingleton().updateAllControllers(); highLevelCull(); _applySceneAnimations(); updateAllTransforms(); updateAllAnimations(); #ifdef OGRE_LEGACY_ANIMATIONS updateInstanceManagerAnimations(); #endif updateInstanceManagers(); updateAllBounds( mEntitiesMemoryManagerUpdateList ); updateAllBounds( mLightsMemoryManagerCulledList ); { // Auto-track nodes AutoTrackingSceneNodeVec::const_iterator itor = mAutoTrackingSceneNodes.begin(); AutoTrackingSceneNodeVec::const_iterator end = mAutoTrackingSceneNodes.end(); while( itor != end ) { itor->source->lookAt( itor->target->_getDerivedPosition() + itor->offset, Node::TS_WORLD, itor->localDirection ); itor->source->_getDerivedPositionUpdated(); ++itor; } } { // Auto-track camera if required CameraList::const_iterator itor = mCameras.begin(); CameraList::const_iterator end = mCameras.end(); while( itor != end ) { (*itor)->_autoTrack(); ++itor; } } buildLightList(); //Reset the list of render RQs for all cameras that are in a PASS_SCENE (except shadow passes) uint8 numRqs = 0; { ObjectMemoryManagerVec::const_iterator itor = mEntitiesMemoryManagerCulledList.begin(); ObjectMemoryManagerVec::const_iterator end = mEntitiesMemoryManagerCulledList.end(); while( itor != end ) { numRqs = std::max<uint8>( numRqs, (*itor)->_getTotalRenderQueues() ); ++itor; } } CameraList::const_iterator itor = mCameras.begin(); CameraList::const_iterator end = mCameras.end(); while( itor != end ) { (*itor)->_resetRenderedRqs( numRqs ); ++itor; } // Reset these mStaticMinDepthLevelDirty = std::numeric_limits<uint16>::max(); mStaticEntitiesDirty = false; for( size_t i=0; i<OGRE_MAX_SIMULTANEOUS_LIGHTS; ++i ) mAutoParamDataSource->setTextureProjector( 0, i ); } void SceneManager::updateAllTransformsThread( const UpdateTransformRequest &request, size_t threadIdx ) { Transform t( request.t ); const size_t toAdvance = std::min( threadIdx * request.numNodesPerThread, request.numTotalNodes ); //Prevent going out of bounds (usually in the last threadIdx, or //when there are less nodes than ARRAY_PACKED_REALS const size_t numNodes = std::min( request.numNodesPerThread, request.numTotalNodes - toAdvance ); t.advancePack( toAdvance / ARRAY_PACKED_REALS ); Node::updateAllTransforms( numNodes, t ); } //----------------------------------------------------------------------- void SceneManager::updateAllTransforms() { mRequestType = UPDATE_ALL_TRANSFORMS; NodeMemoryManagerVec::const_iterator it = mNodeMemoryManagerUpdateList.begin(); NodeMemoryManagerVec::const_iterator en = mNodeMemoryManagerUpdateList.end(); while( it != en ) { NodeMemoryManager *nodeMemoryManager = *it; const size_t numDepths = nodeMemoryManager->getNumDepths(); size_t start = nodeMemoryManager->getMemoryManagerType() == SCENE_STATIC ? mStaticMinDepthLevelDirty : 1; //Start from the first level (not root) unless static (start from first dirty) for( size_t i=start; i<numDepths; ++i ) { Transform t; const size_t numNodes = nodeMemoryManager->getFirstNode( t, i ); //nodesPerThread must be multiple of ARRAY_PACKED_REALS size_t nodesPerThread = ( numNodes + (mNumWorkerThreads-1) ) / mNumWorkerThreads; nodesPerThread = ( (nodesPerThread + ARRAY_PACKED_REALS - 1) / ARRAY_PACKED_REALS ) * ARRAY_PACKED_REALS; //Send them to worker threads (dark_sylinc). We need to go depth by depth because //we may depend on parents which could be processed by different threads. mUpdateTransformRequest = UpdateTransformRequest( t, nodesPerThread, numNodes ); fireWorkerThreadsAndWait(); //Node::updateAllTransforms( numNodes, t ); } ++it; } //Call all listeners SceneNodeList::const_iterator itor = mSceneNodesWithListeners.begin(); SceneNodeList::const_iterator end = mSceneNodesWithListeners.end(); while( itor != end ) { (*itor)->getListener()->nodeUpdated( *itor ); ++itor; } }
我们先假设有n个工作线程.如下是针对这段代码的分析:
Barrier类型mWorkerThreadsBarrier对象:同步主线程与工作线程,用二个信号量来模拟.( 我们用来互换信号量。否则,如果多个工作线程中如果一个,造成这一困在当前线程的同步点,最终会死锁)。
mNumThreads:工作线程与主线程之和,n+1
mLockCount:当前锁定线程数.
工作线程执行方法updateWorkerThread -> _updateWorkerThread(死循环)
主线程里fireWorkerThreadsAndWait与工作线程中的_updateWorkerThread都会调用二次mWorkerThreadsBarrier->sync()方法.如下我们简化mWorkerThreadsBarrier->sync()为sync方法,如没做特殊说明,sync都是指mWorkerThreadsBarrier->sync().
创建Barrier对象mWorkerThreadsBarrier,信号量为0.
创建n个工程线程,因为当前信号量的值为0,所以在工作线程_updateWorkerThread循环中第一次的sync方法会引起当前信号量WaitForSingleObject堵塞.最终锁定线程数mLockCount为n.
主线程更新场景时,假设到了如上面的updateSceneGraph->updateAllTransforms后,更新标识为CULL_FRUSTUM,调用fireWorkerThreadsAndWait中的第一次sync方法后,达到mWorkerThreadsBarrier中的条件mLockCount== mNumThreads,此时重置当前信号量为工作线程数n(然后切换成下一个信号量,下一个信号量值为0).这样当前信号量下的工作线程就可以执行工作(_updateWorkerThread->updateAllAnimationsThread).
当主线程和n个工作线程纷纷通过第一个sync方法,执行任务,各达到线程中第二次sync方法前,前n个线程(主线程可能也在里面了)来到下一个信号量前面,这个信号量的值为0,所以大家都等着,等到最后一个线程也执行完了,到二次sync方法,此时和第三步差不多,因为mLockCount== mNumThreads, 此时重置当前信号量为工作线程数n(然后切换成下一个信号量,下一个信号量值为0).这样当前信号量下所有线程都纷纷跨过第二次sync方法.工作线程就是执行完当前循环,进到下一个循环里的第一次sync这里.这样又到当前信号量这里来了,因信号量为0,所以WaitForSingleObject堵塞.和第2步状态.
然后重复这个过程,一些平等关系的更新就可以用工作线程更新,等主线程调用fireWorkerThreadsAndWait的第一个sync方法.然后重复下去.不过要指出的是,线程的顺序是不确定的,不仅仅是说第四步最后到达的是不确定的,也有可能在第三步中,因为主线程执行fireWorkerThreadsAndWait后,接着执行fireWorkerThreadsAndWait的第一个sync可能还在工作线程第二个sync到时第下一个循环的第一个sync之前完成.但是这个其实是没有关系,因为我们要求的同步也不麻烦,只有一齐开始,然后等到一齐结束,这个是满足的.
这只是Ogre中新线程方案中的一例,这个过程我们可以看到Ogre中的渲染过程中,所有节点更新,所有动画,所有模型AABB全部是多线程开动的,这些方法内部数据的组合也多是DOD对应的SOA结构,前面DOD链接中说明DOD优势就有更容易的并行化以及更好的缓存命中.前面的幻灯片文档里有专门针对DOD与OOD缓存命中的比较.
HLMS:只是简介
Ogre2.0已经放弃FFP了,不过本来就是一个应该早放弃的东东,在Ogre1.9就能用RTSS组件替换FFP了,不过在Ogre2.0是真真完全没有,相关API都没有了,那是不是说要简单渲染一个模型都要写着色器代码了,或是一定要用到RTSS,这都不是,我们需要用到最新的高级材质系统HLMS.HLMS可以说是组合原来的material和RTSS的新的核心功能,使用更方便与灵活,高效.
在说明新的HLMS时,我认为有必要先讲解一下渲染流水线,这是博友亮亮的园子OpenGL管线(用经典管线代说着色器内部),本文FFP与可编程管线都有说明,对比如上,HLMS采用分块方案,这样有很多好处,第一每块状态可以重复使用,减少内存和带宽,提高cache命中.第二D3D和OpenGL都是状态机模式,使用块模式,可以组合相同块一起渲染,减少状态切换,提高渲染效率.这也是为什么作者说原来的Material是低效的,不建议使用,还有作者特意说明,这种分块模式看起来像是D3D11中的,但是作者本身是一个OpenGL fan,他开发这个HLMS一直都是在OpenGL下,只能说,作者说D3D11开发者想到一起了.
Macroblocks是光栅化状态,它们包含深度的读/写设置,剔除模式。Blendblocks就像D3D11混合状态,含混合模式及其影响因素。Samplerblocks就像D3D11在GL3 +或采样状态采样对象,包含过滤信息,纹理寻址模式(包,卡,等),纹理的设置,等等。
Macroblocks块: 包含逐片断处理中的深度检查,还有剔除模型,显示模式,类似如D3D11中的ID3D11RasterizerState.
Blendblocks块: 逐片断处理中的Alpha混合操作.类似ID3D11BlendState.
Samplerblocks块:纹理块的属性集合.类似D3D11_SAMPLER_DESC.
Datablocks块:这个OgreMain里没怎么体现出来,应该去看OgreHlmsPbs,对应文件夹Media\Hlms\Pbs中,可以看下是怎么回事. Datablocks与Renderable结合一起填充着色器代码,如RTSS一样.
包含上面所有块,承载着相当于原Material项.举例如原来Ogre1.x老模型Renderable原来是setMaterial,现在新模型Renderable使用setDatablock.
原来Material中,如表面颜色等影响顶点着色器与片断着色器之间属性分被分配到Datablocks,刚开始看到alaph_test等相关设置在里面还疑惑了下,后面直接在Media\Hlms\Pbs里查看,如glsl中的PixelShader_ps.glsl可以直接根据相应alaph_test设置已经可以丢弃片断,和逐片断处理中的AlphaTest一样,这里有点还是没搞清楚,是逐片断处理放弃AlphaTest了还是提前到片断着色器中处理了,毕竟逐片断处理是在片断着色器之后. 逐片断处理别的处理如上也是单独分块的.
总结:
这些都只是对应二份文档的一小部分翻译,只是简单介绍Ogre2.x中一部分新功能,从这一小部分,我们已经可以看到,这是一个完全不同的Ogre引擎,如下几点后面会具体分析.
1.新的渲染流程.
2.新模型格式以及VAO的引进
3.HLMS详解.
4.新合成器详解.
5.新线程详解.
当然Ogre2.1事实还是半完成状态,相关文章会尽量使用最新版本进行分析.最后,不得不说句,TMD果然只能用C++或C来设计游戏引擎,如上优化如果用C#来做,肯定比用C++都来的麻烦.