初识KMP
-
KMP简介
KMP是一种由Knuth(D.E.Knuth)、Morris(J.H.Morris)和Pratt(V.R.Pratt)设计的字符串匹配算法。对目标串T[0:n-1]中查找与之匹配的模式串P[0:m-1],KMP算法的时间复杂度为O(n+m),它是核心思想是通过目标串和模式串已经部分匹配的信息,减少或者避免冗余的比较,达到提高效率的目的。
-
暴力匹配简介
通常情况下,C/C++初学者是采用"暴力匹配"算法来解决目标串T[0:n-1]和模式串P[0:m-1]的匹配问题。"暴力匹配"的算法用自然语言描述,如下所示。
- 若strlen(T)<strlen(P), 则匹配失败,否则进行第二步。其中strlen(P)表示字符串P的长度。
- 用P的第j位(初始j=0)与T的第i位(初始i=0)进行比较,若P[j] == T[i],则分别比较两者的下一位;若 P[j] != T[i],则用P的首位与T的下一位进行比较。
- 重复第2步,直到模式串已经全部匹配成功或者匹配失败。全部匹配成功时,j>=strlen(P);匹配失败时,i>=strlen(T)且j<strlen(P)。
"暴力匹配"算法的代码如图4-1所示。
1 int StringMatch(char * T, char * P) 2 { //匹配失败返回-1,匹配成功返回T[0:n]中匹配字符串首字符位置 3 int i = 0, j = 0, len1 = strlen(T), len2 = strlen(P); 4 if(len1 < len2) 5 return -1; 6 while( i<len1 && j < len2){ 7 if(P[j] == T[i]) 8 i++, j++; 9 else 10 i++; 11 } 12 if(j>=len2) 13 return i - len2; 14 else 15 return -1; 16 }
图4-1 "暴力匹配"的C语言代码
-
冗余的原因
KMP算法是对暴力匹配进行改进,减少于冗余比较次数。那么,暴力匹配的"冗余比较"出现在哪里呢?
表4-2 字符串匹配
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 目标串T | A | B | C | B | B | A | B | C | D |
| 模式串P | A | B | C | D |
如表4-2所示,T[0:2]和P[0:2]已经匹配,只有T[3] != P[3],按照暴力匹配的算法,把P[0]与T[1]进行比较。注意目标串的T[0:3]已经比较过了,已经确定T[0:3]的字符的值。暴力匹配需要把指向T[3]的指针回溯到T[1],重新进行比较。这就造成冗余!按照人的思维进行字符串匹配来思考,这时知道T[1:3]中没有出现字符'A',所以不可能匹配,因此需要越过T[1:3],进行T[4]与P[0]比较。
-
特征向量next
机器只会执行,即使比较过了,它也不会记住T[1:3]中没有'A'。因此,需要一个特征向量next来让标记已经匹配的子串信息。next是一个数组,与模式串密切相关,长度与模式串相等,定义如下。
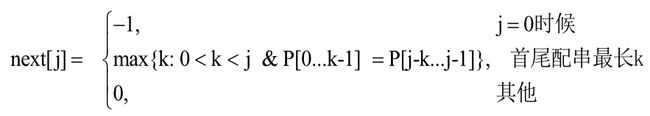
图4-3 next数组的定义
由图4-3中可以得出,next[0] = -1,当存在正整数k(0<k<j),使得P[0...k-1] = P[j-k...j-1]成立的最大k值即为next[j]的值,不存在这样的k时,next[j]=0。其中P[0...k-1] = P[j-k...j-1]是指,模式串最前面的k位字符与刚好当前位置j之前倒数k个字符相匹配。如表4-4所示,构造出模式串的next特征向量。
| 下标j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 模式串P | A | B | A | B | B | B | A | B | A |
| next[j] | -1 | 0 | 0 | 1 | 2 | 0 | 0 | 1 | 2 |
-
-
-
-
-
-
-
-
- j = 0, next[j] = -1
- j = 1, 因为0<k<j, 因此不存在正整数k, next[1] = 0
- j = 2, 当k=1,P[0] != P[1], next[2] = 0
- j = 3, 存在最大值k=1,满足P[2] = P[0], next[3] = 1
- j = 4, 存在最大值k=2, 满足P[0,1] = P[2,3], next[4] = 2
- j = 5, 不存在最大值k=3,满足P[0,1,2] = P[2,3,4], P[4] != P[0], next[5] = 0
- j = 6, P[5] != P[0], next[6] = 0
- j = 7, 存在最大值k=1, P[6] = P[0], next[7] = 1
- j = 8, 存在最大值k=2, P[6,7] = P[0,1], next[8] = 2
-
-
-
-
-
-
-
由此,可以设计出求解next的算法,相应的C语言代码如图4-5所示。
void setNext(int * next)
{ //求特征向量next的数组元素值, P为模式串, T为目标串
int j=0, k=-1,len = strlen(P);
while(j<len-1){
if(k == -1 || P[k]== T[j])
next[++j]= ++k;
else
k = next[j];
}
}
图4-5 求解next的C程序
-
next的使用
next数组元素保存已经部分匹配的字符串信息,根据next数组元素值,可以跳过已经比较过的冗余的比较步骤。
| 下标i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 目标串T | A | B | A | B | A | B | A | B | B | B | A | B | A |
| 模式串P | A | B | A | B | B | B | |||||||
| A | B | A | B | B | B | ||||||||
| A | B | A | B | B | B | ||||||||
| next[j] | -1 | 0 | 0 | 1 | 2 | 0 |
如表4-6所示,当i=4, j=4时,T[i] != P[j], 需要移动模式串P与目标串相应比较的位置对齐。需要移动的多少从next数组的元素值可以得到。当j = 4, next[j] = 2,根据next的定义,P[0,1] = P[2,3],又T[0:3] = P[0:3],所以P[0,1] = T[2,3],因此只需比较T[4] 和 P[2]即可。此时i = 4, j = 2,j的值由4回溯为2,是根据j = next[j]得到的。j经过回溯后,P[0:j-1] = T[i-j:i-1]已经是匹配的。同理,当i = 6, j = 5, T[i] != P[j], 查next数组next[5] = 2, j回溯 j=4=>j=2。
所以next数组的作用是:
当P[j] != T[i]时,j的值由j = next[j],快速回溯到需要比较的位置, 并且P[0,j-1]必定与T[i-j, i-1]匹配。
-
思考: next数组的求解方法有没有需要优化的地方?
| 下标i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 目标串T | A | A | B | C | B | A | B | C | A | A | B | C | A | B | A |
| 模式串P | A | B | C | A | A | B | A | B | C | ||||||
| A | B | C | A | A | B | A | B | C | |||||||
| A | B | C | A | A | B | A | B | C | |||||||
| next[j] | -1 | 0 | 0 | 0 | 1 | 1 | 2 | 1 | 2 |
如表4-7所示,已知 T[1:3] = P[0:2], T[4] != P[3]。 此时 k = next[j] = 0, P[k] = P[j] = 'A'。又已知P[j] != T[i],根据之前的next数组求解,此时仍然进行P[k] 与 T[i]的比较。很明显,此时P[k] != T[i],
所以此次比较属于冗余!P[k] = P[j] 是在求解next数组的时候已知的,而特征向量,即next数组并没有显示出这个信息。所以,需要对next数组的求解进行优化,进一步减少冗余比较次数。
void setNext(int * next) { //求特征向量next的数组元素值, P为模式串, T为目标串
int j=0, k=-1,len = strlen(P); while(j<len-1){ if(k == -1 || P[k]== T[j]) {
j++, k++;
if(P[j] = P[k]) //对next数组求解进行优化
next[j] = next[k];
else
next[j] = k;
} else k = next[j]; } }
-
KMP算法的C代码
int KmpMatch(char T[], char P[], int * next, int start)
{//在目标串T[]中的start位置开始匹配模式串P,next为P的特征向量数组首地址,若匹配成功则返回模式串首字符在T中r位置,否则返回-1
int i = start, j = 0, plen = strlen(P), tlen = strlen(T);
if( plen > tlen )
return -1;
while( i < tlen && j< plen){
if( j == -1 || T[i] == P[j])
i++, j++;
else
j = next[j];
}
if( j >= plen )
return i - plen;
else
return -1;
}
-
扩展KMP算法(待续)