RHadoop和CDH整合实例(一)- R及rhdfs
最近需要在hadoop上集成R语言环境进行统计分析任务,考虑用到RHadoop。但是由于集群上的hadoop并非原生态hadoop,而是cloudera集成的版本,并且由于系统上kerberos和sentry的安全管理机制,给集成RHadoop造成了不小的麻烦。网上搜索的步骤和问题有一些已经过时,有一些对集成了cloudera环境的配置方法所提甚少,甚至遇到一些问题在google上或者github上搜索,查看相关讨论却无果。因此环境整合完毕,觉得有必要进行一下总结。
RHadoop包含了三个组件,rhdfs, rmr2和rhbase,本文不涉及rhbase,除此之外,由于数据由hive管理,我们还会涉及到rJDBC和RHive的整合。
Roadmap:
一、环境
二、R的安装及相关依赖库
三、rhdfs的安装和测试
四、 rmr2的安装和测试
五、 rJDBC的安装和测试
六、 rHive的安装和测试
一、环境
本次实例中涉及到192.168.241.168,192.168.241.169和192.168.241.170三台主机,组成hadoop集群。其中Hiveserver 2在192.168.241.169上。环境及安装组件的详细版本信息如下表:
| 项目 | 版本 |
| hadoop | 2 |
| CDH | 5 |
| Hive | 0.12 |
| Java | 1.6.0 |
| R | 3.2.2 |
| rhdfs | 1.0.8 |
| rmr2 | 3.3.1 |
| RJDBC | 0.2-5 |
| RHive | 2.0 |
本文涉及到的库及组件下载地址:
rhadoop(rhdfs + rmr2 + rhbase)的详细信息可在github上查到https://github.com/RevolutionAnalytics/RHadoop/wiki, RevolutionAnalytics项目页上可直接拉取最新版本的源码并自己编译, 需要改造源码的同学请自行下载, 这里的rhds和rmr2包我们直接从以下地址下载。
rhdfs - https://github.com/RevolutionAnalytics/rhdfs/blob/master/build/rhdfs_1.0.8.tar.gz?raw=true
rmr2 - https://github.com/RevolutionAnalytics/rmr2/releases/download/3.3.1/rmr2_3.3.1.tar.gz
RHive是nexr的项目, 由于我们需要对RHive源码进行部分调整, github上编译好的安装包不知道为什么我也下不下来, 因此直接拉取源码。
RHive - https://github.com/nexr/RHive
二、R的安装及相关依赖库
R的安装需要gfortran,因此先确保gfortran存在于环境中,进行配置后安装R。
> yum install gcc-gfortran #R环境安装依赖gfortran > sudo yum install R #安装R环境 > sudo R CMD javareconf -y > sudo R #以管理员身份进入R,安装RHadoop所需的依赖包
进入R后,
install.packages(c("Rcpp","RJSONIO","itertools","digest"))
install.packages(c("itertools","iterators"))
install.packages(c("functional", "stringr", "plyr")
install.packages("reshape2")
install.packages("rJava")
R中通过install.packages()的方式安装,系统中默认安装路径:/usr/local/lib64/R/library。
由于版本原因,有些版本的R对于部分依赖库无法直接用install.packages()安装,此时需要到cran上手动下载,再用R直接安装即可,如:
> wget https://cran.r-project.org/src/contrib/Archive/plyr/plyr_1.8.tar.gz > sudo R CMD INSTALL plyr_1.8.tar.gz
二、rhdfs的安装及测试
首先需要配置环境变量HADOOP_CMD和HADOOP_STREAMING, HADOOP_CMD即为系统中用hadoop命令时所处的bin路径,HADOOP_STREAMING这个变量rmr2会用到,本身需要找的是hadoop-streaming-XXX.jar(XXX为版本号),很多文章中提到的设置方法都是基于原生态hadoop的,而本文的系统集成了cloudera,cloudera路径在/opt/cloudera/parcels/CDH-5.1.3-1.cdh5.1.3.p0.12/,通过ll可以看到/opt/cloudera/parcels/CDH-5.1.3-1.cdh5.1.3.p0.12/lib/下集成了hadoop, hive, hue等等库,需要注意的是hadoop-streaming-XXX.jar这个包用的不是/opt/cloudera/parcels/CDH-5.1.3-1.cdh5.1.3.p0.12/lib/hadoop/contrib/streaming/hadoop-streaming-XXX.jar, 而是和CDH5集成后的hadoop-streaming-2.3.0-mr1-cdh5.1.3.jar,路径在/opt/cloudera/parcels/CDH-5.1.3-1.cdh5.1.3.p0.12/lib/hadoop-0.20-mapreduce/contrib/streaming/。
这两个变量在本文提到的环境中分别设置如下:
> export HADOOP_CMD=/usr/bin/hadoop > export HADOOP_STREAMING=/opt/cloudera/parcels/CDH-5.1.3-1.cdh5.1.3.p0.12/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.3.0-mr1-cdh5.1.3.jar
环境变量的设置也可直接更改/etc/profile文件进行设置,记得更改后source /etc/profile一下才能立即生效。
rhdfs的安装包需要从github上下载(https://github.com/RevolutionAnalytics/rhdfs),新建一个临时目录,假设置于~/$INS_TMP路径下。rhdfs的安装还要依赖bitops和caTools库,直接用R的install.packages()都无法获取,先安装这两个库,再安装rhdfs。
> sudo R CMD INSTALL ~/$INS_TMP/rhdfs_1.0.8.tar.gz
测试:进入R,输入以下命令,
library(rhdfs) #加载rhdfs库
hdfs.init() #初始化
hdfs.ls("/user/") #查看hdfs上/user/目录下的文件
q() #退出R
rhdfs成功访问hdfs(由于hdfs上含有一些业务数据,这里进行了部分遮挡):
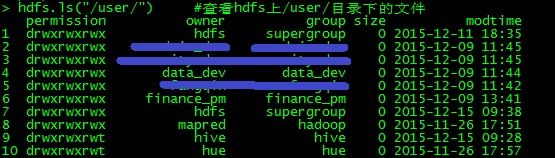
图1 rhdfs程序测试结果
hdfs.ls("/user/")的输出和直接用hadoop fs -ls /user/输出一致,证明rhdfs成功访问hdfs。
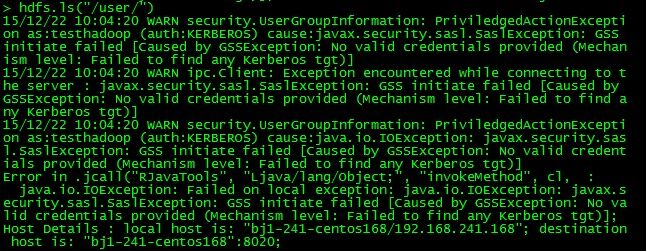
可能出现问题:
(1) 若出现异常security.UserGroupInformation: PriviledgedActionException as:testhadoop (auth:KERBEROS), 原因GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)]的问题,需要先用kinit获取kerberos票据,再进入R测试。