Nutch2.2.1 笔记三 : 从Nutch脚本执行来看Nutch的内部执行过程
网上大部分的Nutch资料都是以前相对老的版本的一些介绍,其中介绍启动Nutch大多数是用如下命令 :
bin/nutch crawl urls -topN 10 -depth 1000
bin/nutch文件是一个shell脚本,我们在STS里面打开它可以观看它的代码,

实际上就是执行了org.apache.nutch.crawl.Crawler这个类,但是在Nutch2.2.1中已经告知该启动方法将要被废弃,如果我们去github上观看nutch2.x 版本的开发情况会发现正在开发的Master主分支中该类已经不存在了,官方推荐通过bin/crawl 脚本来启动Nutch,OK,既然这样在这里就不再介绍bin/nutch crawl这种启动方式和Crawler这个类了,毕竟它就要被废弃了,重点介绍bin/crawl这个脚本启动方式,我们打开脚本查看代码,可能此时还有点不太明白,但是不影响我们借此对它有一个大体的分析

在104行有一个for循环,LIMIT是传入的参数,这个值就相当于之前 bin/nutch crawl urls -topN 10 -depth 1000这种启动方式的topN这个参数,这个值是nutch抓取url链接的深度,在for循环之前执行了
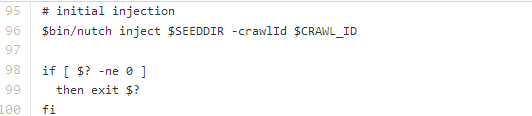
这个命令,可以看到bin/crawl脚本调用的是bin/nutch脚本,inject之后就是for循环了,重点查看for循环里面的执行步奏,流程依次向下
echo "Generating a new fetchlist" $bin/nutch generate $commonOptions -topN $sizeFetchlist -noNorm -noFilter -adddays $addDays -crawlId $CRAWL_ID -batchId $batchId
echo "Fetching : " $bin/nutch fetch $commonOptions -D fetcher.timelimit.mins=$timeLimitFetch $batchId -crawlId $CRAWL_ID -threads 50
echo "Parsing : " skipRecordsOptions="-D mapred.skip.attempts.to.start.skipping=2 -D mapred.skip.map.max.skip.records=1" $bin/nutch parse $commonOptions $skipRecordsOptions $batchId -crawlId $CRAWL_ID
echo "CrawlDB update for $CRAWL_ID" $bin/nutch updatedb $commonOptions -crawlId $CRAWL_ID
在for循环内部最后的执行命令是
echo "Indexing $CRAWL_ID on SOLR index -> $SOLRURL" $bin/nutch solrindex $commonOptions $SOLRURL -all -crawlId $CRAWL_ID
这个命令其实是将前面抓取到的数据提交到solr中创建索引,我在项目中应用的是elasticsearch,所以我把这里给改掉了,但是不论是solr还是elasticsearch我们这里都先不讨论,重点关注前几部步奏,也就是
bin/nutch generate ......
bin/nutch fetch ......
bin/nutch parse ......
bin/nutch updatedb .....
在for循环中的这几步加上for循环前面的bin/nutch inject ......这些就组成了nutch最基本的抓取流程,上一篇我们已经在STS成功执行了inject命令了,我们可以自己观看代码知道该类接受两个参数,<url_dir>表示必须传入的种子url的地址,在local模式下表示本地地址,在deploy模式下表示hdfs内部的地址,[-crawlId <id>] 表示该参数可选,我们在上一篇执行inject的时候没有指定该参数,大体了解了bin/crawl之后我们其实就可以再STS/Eclipse单步执行调试了,研究每一步的过程对理解nutch2.2.1有很大的帮助,根据bin/nutch inject 在源代码里面找到对应执行的类org/apache/nutch/injectorJob.java,基本上主要的逻辑全部在
![]()
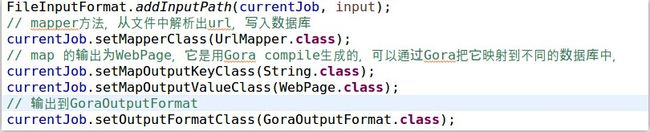
函数中,即使不懂map/reduce在这里同样可以看懂源代码,这里推荐http://blog.csdn.net/itufo/article/details/21519593 这篇文章详细的分析了InjectorJob
url的过滤是通过nutch的插件来实现的,配置文件为conf/regex-urlfilter.txt在这里可以配置我们想要过滤的url正则,这是我们接触到的第一个nutch插件,nutch默认对插件的配置在conf/nutch-default.xml中里面为
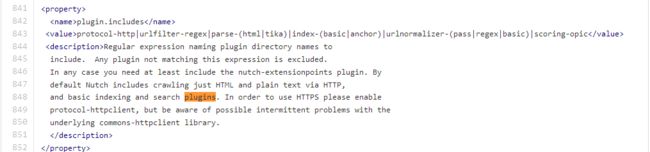
光看名字就知道urlfilter-regex是想对应的插件,我们已经在上一篇成功配置了Nutch2.2.1 + Mysql,我们可以一边配置研究代码一边查看mysql中的数据
最后这篇文章大致分析了Nutch2.0的执行流程,基本上能够代表Nutch2.x的了,很有参考性
http://blog.csdn.net/amuseme_lu/article/details/7777426
下一篇继续根据Nutch + Mysql来分析GeneratorJob => FetcherJob => ParserJob => DbUpdaterJob几个阶段的内部流程,根据Mysql数据库里面的数据变化加深nutch2.2.1流程的了解和记忆