过剩通勤应用——线性规划问题解决开源工具(下篇)
看了上篇博客对GLPK的建模计算有了大概了解,本章完成BOSS下达任务,完成一个过剩通勤计算。
首先当然是写好model文件,其中最大通勤为:
param n;
param m;
param Population{i in 1..n,j in 1..m};
param Distance{i in 1..n,j in 1..m};
var x{i in 1..n,j in 1..m}>=0,integer;
maximize obj:sum{i in 1..n}sum{j in 1..m} Distance[i,j]*x[i,j];
s.t.
e{i in 1..n}:sum{j in 1..m}x[i,j]=sum{j in 1..m}Population[i,j];
f{j in 1..m}:sum{i in 1..n}x[i,j]=sum{i in 1..n}Population[i,j];
solve;
printf "min sum:%d",sum{i in 1..n}sum{j in 1..m} Distance[i,j]*x[i,j];
end;
最小通勤为:
param n;
param m;
param Population{i in 1..n,j in 1..m};
param Distance{i in 1..n,j in 1..m};
var x{i in 1..n,j in 1..m}>=0,integer;
minimize obj:sum{i in 1..n}sum{j in 1..m} Distance[i,j]*x[i,j];
s.t.
e{i in 1..n}:sum{j in 1..m}x[i,j]=sum{j in 1..m}Population[i,j];
f{j in 1..m}:sum{i in 1..n}x[i,j]=sum{i in 1..n}Population[i,j];
solve;
printf "min sum:%d",sum{i in 1..n}sum{j in 1..m} Distance[i,j]*x[i,j];
end;
就是将maximize改为miniminze,写了个run.bat文件方便输出:glpsol --model MaxTrafficCommuting.model --data Data.data --output max.solve glpsol --model MinTrafficCommuting.model --data Data.data --output min.solve
接下来是data文件部分了,由于原始数据是excel数据,需要先进行格式整理,主要就用pandas进行整理,操作方便,直接附上python代码:(data文件的格式可以参照上一篇GPLK解释的文章)
# -*- coding: cp936 -*-
import pandas as pd
def toformat():
#data is big table, and data1 is small table
#make the big equal to the small
data=pd.read_excel('Distance.xlsx',index_col=None)#big
data1=pd.read_excel('Population.xlsx',index_col=None)#small
#change its column
data=data[data1.columns]
if len(data1.columns)!=len(data.columns):
print "row exist Duplicate items"
#change its row's index
data=data.loc[data1.index]
if len(data1.index)!=len(data.index):
print "row exist Duplicate items"
data.to_excel('Distance.xlsx',sheet_name='Sheet1',engine='xlsxwriter')
#to creat txt file
data.to_csv('Distance.txt',sep='\t')
data1.to_csv('Population.txt',sep='\t')
pop,popnum=changeformat('Population.txt')
dis,disnum=changeformat('Distance.txt')
if popnum!=disnum:
print '两个矩阵大小不相等,请检查数据'
print '实际通勤为%d'%(sum(data*data1))
return pop,dis,str(len(data.index)),str(len(data.columns))
def todealmiss():
data=pd.read_excel('Population.xlsx','Sheet1',index_col=None,na_values=['0'])
data=data.fillna(0)
data.to_excel('Population.xlsx',sheet_name='Sheet1',engine='xlsxwriter')
def changeformat(filename='Population.txt'):
with open(filename,'r') as datafile:
data=datafile.read().split('\n')
n=len(data)
data[0]='param '+filename[:-4]+':'+data[0][1:]+':='
#从excel转换为txt时最后一个空格键多出了一行,
data[n-2]=data[n-2]+';'
outputname='new_'+filename
return data,n
todealmiss()
pop,dis,row,col=toformat()
with open('Data.data','w') as datafile:
datafile.write('param n:='+row+';'+'\n')
datafile.write('param m:='+col+';'+'\n')
for p in pop:
datafile.write(p+'\n')
for d in dis:
datafile.write(d+'\n')
代码写的很乱,没优化了,直接运行结果,总体来说速度还是挺快的,381*381(145161)个数据大概用了5秒多:
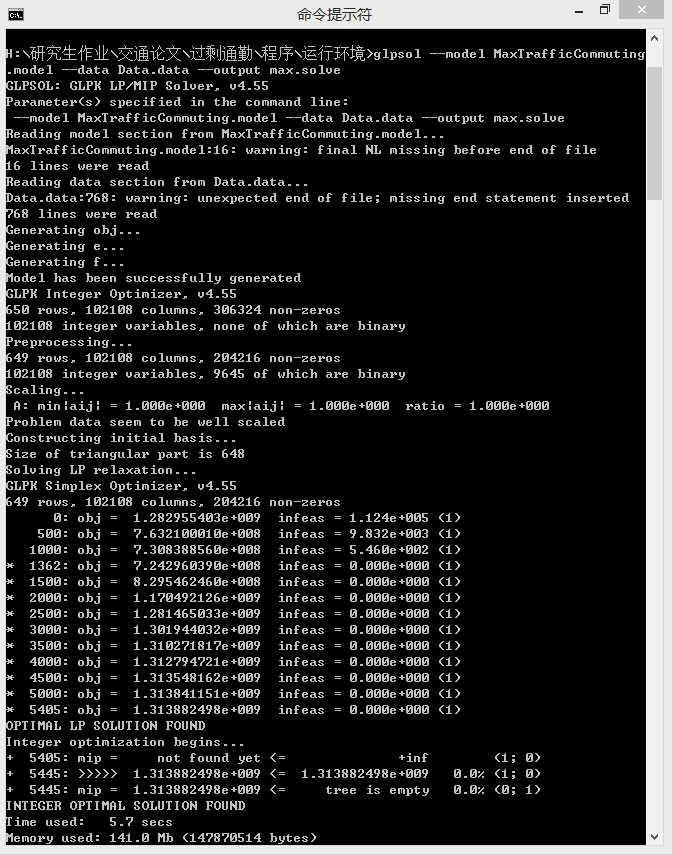
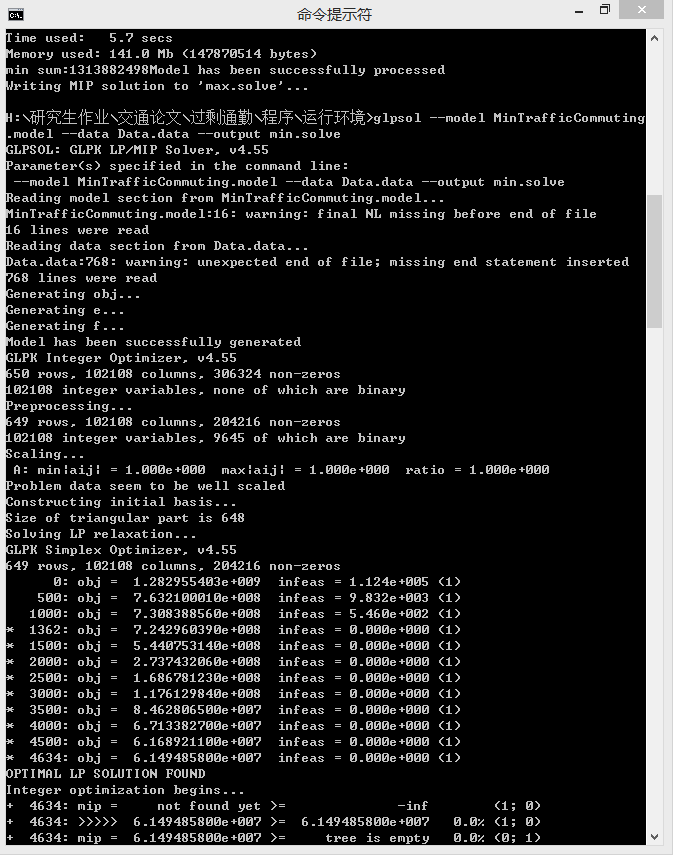
整体性能还不错,其实本来这次想试一试cvxopt的谁知道安装官网步骤也一直没安装上~有知道解决的万分感谢