【语音识别】一文搞懂hmm
一 一些概念理解
- 熵:代表信息的不确定性。描述一件事情的时候,考虑到所有的不确定性,能将风险降到最低
- 最大熵:如上,描述一件未知状态时候,要尽量考虑所有的可能结果,以此估计出的结果风险才最低。从此处出发,使用最大熵模型,可以用在估计词性,要考虑到该词语的上下文条件,发音。这些都考虑到后给出的结果风险最低,指的是最接近实际结果。 最大熵的模型函数如下
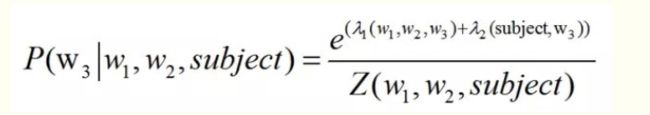
假设w3是要估计的词的词性,则w1,w2可以是该词前后的词语,subject是当前文章的主题。所以训练的过程,就是已经知道w3的词性和w1,w2的内容,对于每个词的情况,推导参数lamda和z的值。解码的时候,对于要估计的w3的结果,是公式中代入lamda和z的值,解出来。解码的时候,还应用到最大似然度,因为每个词语相关的特征有很多种。不同的特征导入,估计出的结果p(w3/w1,w2,subject)的值很多,给出该值最大的时候的w3对应的结果,就是解码的工作。(以上为个人理解,后续发现误解及时做补充修改)
- HMM隐马尔科夫模型: 常用在可以看到一部分过程,以及一些输出的参数。需要估计隐含的参数内容。该过程是马尔科夫过程,前者会影响到后者,该参数是隐含参数。看到的的参数是输出参数
- hmm模型参数:两个状态集合,三个概率矩阵。两个状态:隐含状态S,可见状态O,三个矩阵:起始概率矩阵,隐含状态转移概率(前一时刻是s1,后一时刻是s2的概率),输出转移概率(当前时刻状态是s1,输出为o1的概率)。HMM参数是(π,A,B),π是初始概率矩阵,A是隐含状态转移矩阵,B是某个时刻由隐藏状态到可见状态的发射概率矩阵。
。
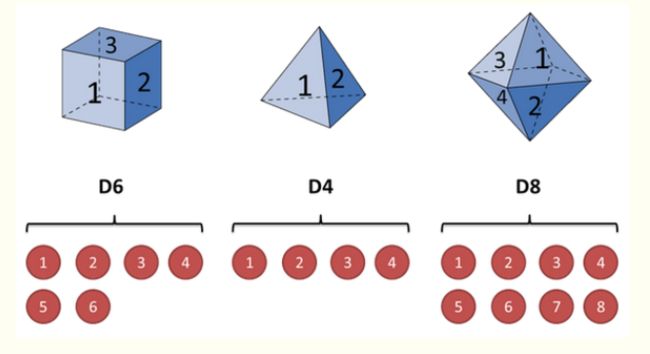
如上图,有三种筛子,4面体,6面体,8面体。分别是D6,D4,D8.每种筛子都有1.2,3,4.。。。7,8. 并且三种筛子排好了顺序,D6后面是D4,在后面是D8,顺序可能是D6,D4,D8,D4,D4,D8,D6,D6. 因此该例子中:
投掷一次筛子,看到的结果可能为1,2,3.。。。7.8.假设投掷多次筛子看到的结果为2,3,8,5,6,1,2,这个序列为可见参数,也叫做可见输出状态。而我们已经规定好三种筛子的排列顺序,D6,D4,D8,D4,D4,D8,D6,D6。也就是d6后面只能是d4或者d8.这个序列为转换状态。从d6转换到d4的结果。我们想知道的是到底第一个筛子是d6,d4,d8中哪一个。这就是隐含参数。hmm模型解决的就是使用一些可见输出状态和转换概率,估计其中的隐含参数。
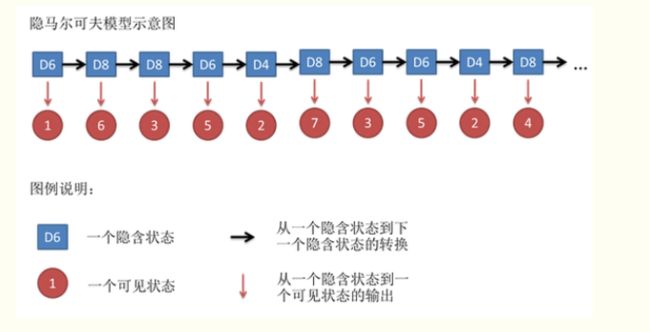
如果提前知道所有的转换序列和所有的可见结果,要估计隐含结果还是比较完整容易的。可是实际中,往往只能知道一部分转换结果和一部分输出结果,想估计所有的隐含结果。hmm主要用在如下三种问题中
- 知道都有几种筛子(隐含状态数量),每种是什么(转换概率),根据投筛子得到的结果(可见状态序列),估计每次投的都是那种筛子(隐含状态序列)
解法:结果可以理解为,是一串结果,推导出这一串结果(一串序列)产生的概率最大,则就是估计的结果。该解法称作最大似然估计,求一串骰子序列,这串序列产生可见状态序列的概率最大。
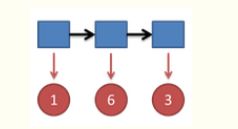
如果如上结果,求最可能的序列。那就是求出每个筛子出现该结果的最大概率然后乘起来。如上序列概率最大时候,第一个必须是d4,p=1/4,第二个必须是d6,p=1/6,第三个必须是d4.这样情况得到概率最大p=1/4*1/6*1/4.所以最可能序列是646.所以解决此种问题方法可以是穷举。
以上问题对应的是解码问题。解决方法是维特比算法。
实际情况中会做剪枝,不是每种状态都会考虑。
维特比算法两步骤:(1)每次从序列长度为1算起,算序列长度为1时候每个结果的最大概率,然后长度增加1,在前个基础上继续计算当前骰子出现结果的最大概率。以此类推,直到得到最后一个骰子的结果的最大概率。(2)由这串序列对应的最大概率,从后往前将序列反向推导出来。
在计算的过程中,这个算法计算每一个时刻每一个状态的部分概率,并且使用一个后向指针来记录达到当前状态的最大可能的上一个状态。最后,最可能的终止状态就是隐藏序列的最后一个状态,然后通过后向指针来查找整个序列的全部
2. 知道都有几种筛子(隐含状态数量),每种是什么(转换概率),根据投筛子得到的结果(可见状态序列),想知道投掷出这个结果的概率。
对应的是模型的评估问题。
也就是,已知模型参数和一串可见序列,想知道这串可见序列的概率。简单理解就是穷举从起始状态到当前时刻出现该状态,所有可能的路径。然后每种路径得到一个概率,概率的和就是出现此结果的概率。穷举法太耗费时间,可以用前向算法估计。
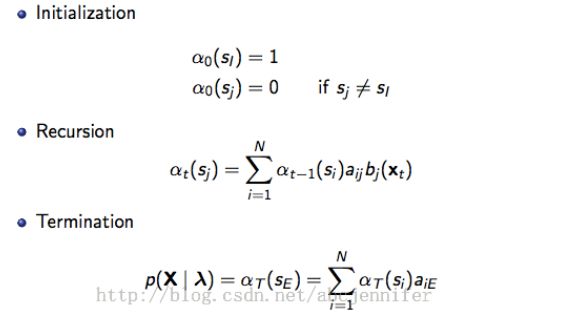
αt(sj)表示HMM在时刻t处于状态j,且observation = {x1,...,xt}的概率。前向算法,是t+1时刻的概率可以基于t时刻的概率计算。然后右边的概率是所有路径的和。主要是递归的思路。
3. 已知观察序列和输出序列,由此学习出hmm参数的三元组,用它来最好的描述我们看到的现象。这就是模型的训练。对应的算法是Baum-Welch算法,也叫作前向后向算法。
对于给定的可观察序列O,没有一个最优的hmm参数λ可以使得P(O\λ)最大,所以只能用一个局部最优解替代全局最优解。
首先假设一组参数,使得观察序列A的情况下得到输出序列O的结果最大。然后根据实际的输出序列评估这些参数做调整,直到和正确结果最接近。
-
GMM的作用
GMM就是几个高斯模型的叠加,一般是3-5个。一个高斯模型就是一个正态分布,表征了信号的概率密度。语音识别中,一个word由多个音素组成,一个音素就是一个状态state,一个state对应一个高斯混合模型GMM。每个GMM中有K个模型参数。
- 语音识别的过程:1)语音分成frame,每个frame提取特征mfcc 2) 每个frame的特征跑GMM,得到每个frame属于每个音素的概率
3). 根据每个单词的HMM状态转移概率a计算每个状态sequence生成该frame的概率; 哪个词的HMM 序列跑出来概率最大,就判断这段语音属于该词
- 经典hmm的语音识别步骤:
1 【训练以得到每个GMM参数和每个HMM参数】 2 a,前向后向算法计算P(O\A)--(输出序列\隐含序列) 3 b,B-W算法求出最优解λ=max(P(O\A) 4 c,对于输入语音,用veterbi算法查出对应哪个hmm模型概率最大,由此得到最佳序列 5 d,根据最佳序列对应组合出音素和单词 6 e,根据语言模型形成词和句子
-
对每个单词建立一个HMM模型,需要用到该单词的训练样本,这些训练样本是提前标注好的,即每个样本对应一段音频,该音频只包含这个单词的读音。当有了该单词的多个训练样本后,就用这些样本结合Baum-Welch算法和EM算法来训练出GMM-HMM的所有参数,这些参数包括初始状态的概率向量,状态之间的转移矩阵,每个状态对应的观察矩阵(这里对应的是GMM,即每个状态对应的K个高斯的权值,每个高斯的均值向量和方差矩阵)
- 在识别阶段,输入一段音频,如果该音频含有多个单词,则可以手动先将其分割开(考虑的是最简单的方法),然后提取每个单词的音频MFCC特征序列,将该序列输入到每个HMM模型(已提前训练好的)中,采用前向算法求出每个HMM模型生成该序列的概率,最后取最大概率对应的那个模型,而那个模型所表示的单词就是我们识别的结果。
参考:
http://blog.chinaunix.net/uid-26715658-id-3453274.html 隐马尔克夫模型攻略
http://www.cnblogs.com/skyme/p/4651331.html 一文读懂hmm
http://blog.csdn.net/abcjennifer/article/details/27346787 GMM-HMM语音识别
http://wenku.baidu.com/link?url=myzmzMqOZqc988bK5Pe3uDgE8bvRvwjAcNz4Oq6naD_584EnWGZjHPHiYVo06s7sx1VF-yayezJfXBjRjicCxo6DYXV-x8ehrCnF04Kai5e hmm模型进行语音识别的基本思路
http://yanyiwu.com/work/2014/04/07/hmm-segment-xiangjie.html hmm的中文分词
http://blog.chinaunix.net/uid-26715658-id-3453274.html 维特比算法介绍
http://www.hankcs.com/nlp/hmm-and-segmentation-tagging-named-entity-recognition.html HMM与分词,词性标注(内有维特比算法的python代码)
http://www.comp.leeds.ac.uk/roger/HiddenMarkovModels/html_dev/main.html 隐马尔克夫模型的英文介绍
http://www.cnblogs.com/tornadomeet/archive/2013/08/23/3276753.html 总结了hmm的几个点