80 多个 Linux 系统管理员必备的监控工具
随着互联网行业的不断发展,各种监控工具多得不可胜数。这里列出网上最全的监控工具。让你可以拥有超过80种方式来管理你的机器。在本文中,我们主要包括以下方面:
-
命令行工具
-
网络相关内容
-
系统相关的监控工具
-
日志监控工具
-
基础设施监控工具
监控和调试性能问题是一个艰巨的任务,但用对了正确的工具有时也是很容易的。下面是一些你可能听说过的工具,也有可能没有听说过——何不赶快开始试试?
八大系统监控工具
1. top
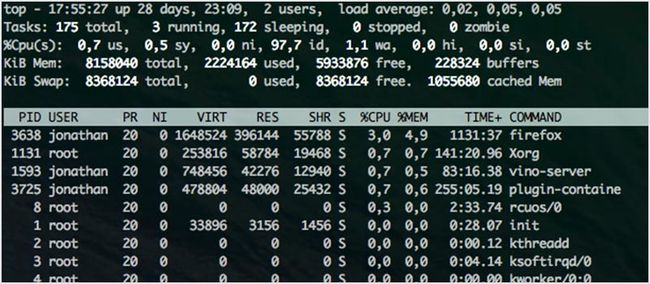
这是一个被预装在许多 UNIX 系统中的小工具。当你想要查看在系统中运行的进程或线程时:top 是一个很好的工具。你可以对这些进程以不同的方式进行排序,默认是以 CPU 进行排序的。
2. htop
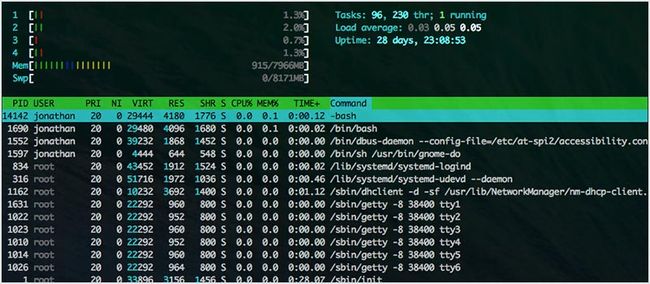
htop 实质上是 top 的一个增强版本。它更容易对进程排序。它看起来上更容易理解,并且已经内建了许多通用操作。它也是完全交互式的。
3. atop
atop 和 top,htop 非常相似,它也能监控所有进程,但不同于 top 和 htop 的是,它可以按日记录进程的日志供以后分析。它也能显示所有进程的资源消耗。它还会高亮显示已经达到临界负载的资源。
4. apachetop
apachetop 会监控 apache 网络服务器的整体性能。它主要是基于 mytop。它会显示当前的读取进程、写入进程的数量以及请求进程的总数。
5. ftptop
ftptop 给你提供了当前所有连接到 ftp 服务器的基本信息,如会话总数,正在上传和下载的客户端数量以及客户端是谁。
6. mytop
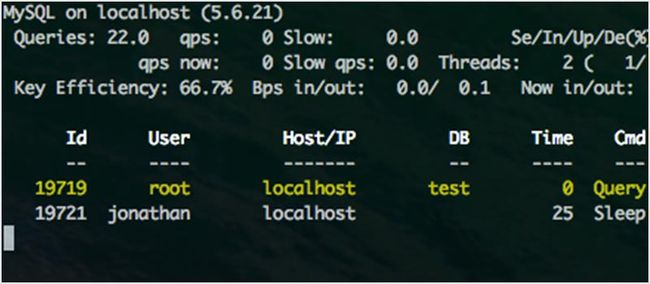
mytop 是一个很简洁的工具,用于监控 mysql 的线程和性能。它能让你实时查看数据库以及正在处理哪些查询。
7. powertop
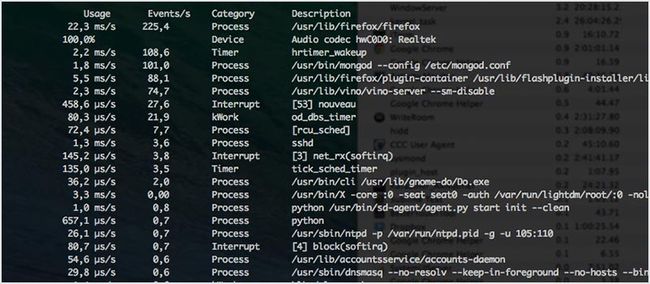
powertop 可以帮助你诊断与电量消耗和电源管理相关的问题。它也可以帮你进行电源管理设置,以实现对你服务器最有效的配置。你可以使用 tab 键切换选项卡。
8. iotop
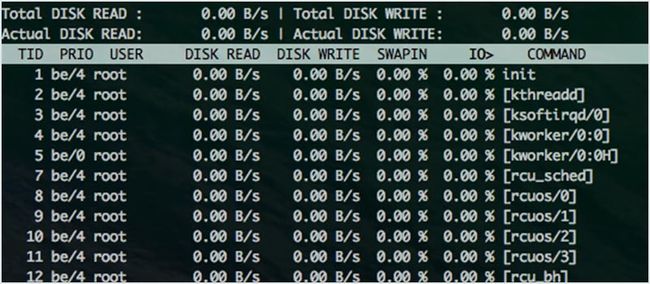
iotop 用于检查 I/O 的使用情况,并为你提供了一个类似 top 的界面来显示。它按列显示读和写的速率,每行代表一个进程。当发生交换或 I/O 等待时,它会显示进程消耗时间的百分比。
与网络相关的监控
9. ntopng
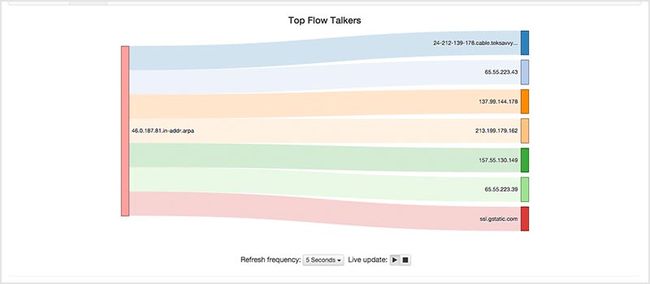
ntopng 是 ntop 的升级版,它提供了一个能通过浏览器进行网络监控的图形用户界面。它还有其他用途,如:地理定位主机,显示网络流量和 ip 流量分布并能进行分析。
10. iftop
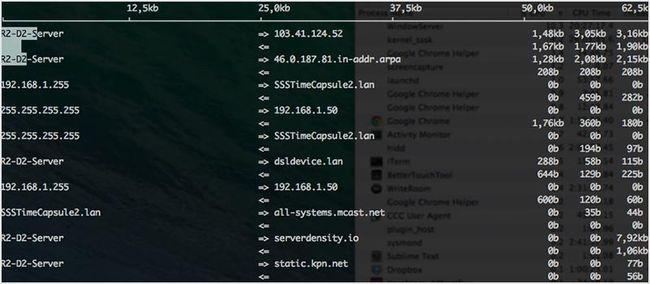
iftop 类似于 top,但它主要不是检查 cpu 的使用率而是监听所选择网络接口的流量,并以表格的形式显示当前的使用量。像“为什么我的网速这么慢呢?!”这样的问题它可以直接回答。
11. jnettop
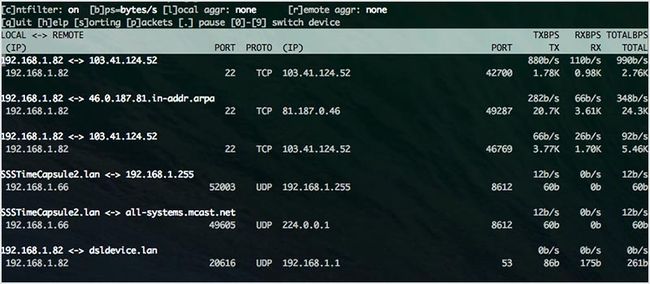
jnettop 以相同的方式来监测网络流量但比 iftop 更形象。它还支持自定义的文本输出,并能以友好的交互方式来深度分析日志。
12. bandwidthd
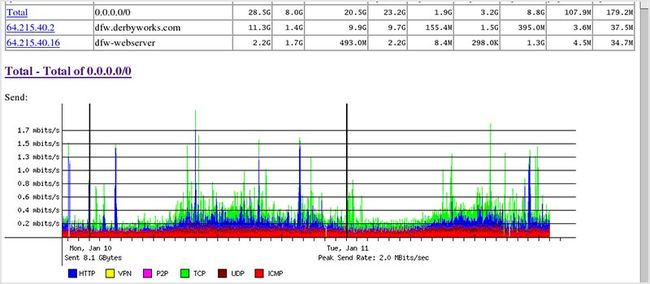
BandwidthD 可以跟踪 TCP/IP 网络子网的使用情况,并能在浏览器中通过 png 图片形象化地构建一个 HTML 页面。它有一个数据库系统,支持搜索、过滤,多传感器和自定义报表。
13. EtherApe
EtherApe 以图形化显示网络流量,可以支持更多的节点。它可以捕获实时流量信息,也可以从 tcpdump 进行读取。也可以使用 pcap 格式的网络过滤器来显示特定信息。
14. ethtool
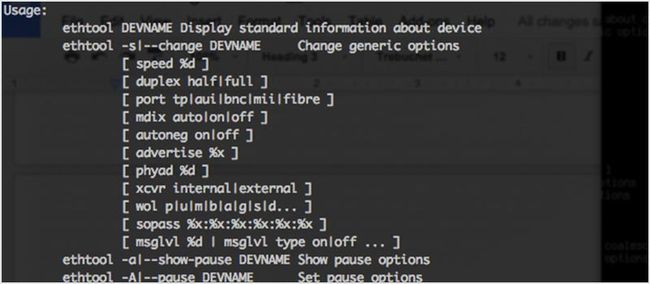
ethtool 用于显示和修改网络接口控制器的一些参数。它也可以用来诊断以太网设备,并获得更多的统计数据。
15. NetHogs
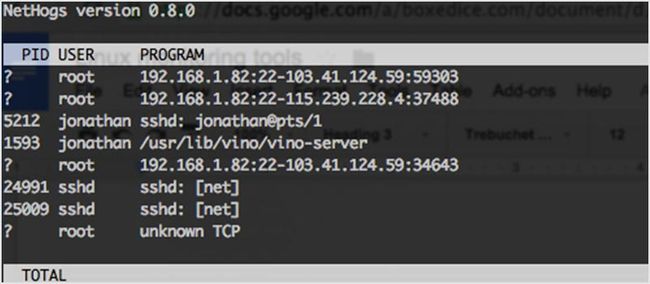
NetHogs 打破了网络流量按协议或子网进行统计的惯例,它以进程来分组。所以,当网络流量猛增时,你可以使用 NetHogs 查看是由哪个进程造成的。
16. iptraf
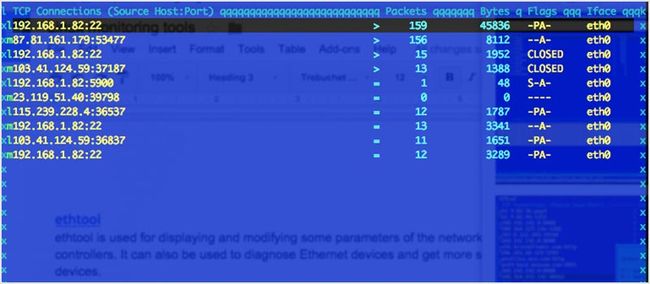
iptraf 收集的各种指标,如 TCP 连接数据包和字节数,端口统计和活动指标,TCP/UDP 通信故障,站内数据包和字节数。
17. ngrep
ngrep 就是网络层的 grep。它使用 pcap ,允许通过指定扩展正则表达式或十六进制表达式来匹配数据包。
18. MRTG
MRTG 最初被开发来监控路由器的流量,但现在它也能够监控网络相关的东西。它每五分钟收集一次,然后产生一个 HTML 页面。它还具有发送邮件报警的能力。
19. bmon
bmon 能监控并帮助你调试网络。它能捕获网络相关的统计数据,并以友好的方式进行展示。你还可以与 bmon 通过脚本进行交互。
20. traceroute
traceroute 是一个内置工具,能显示路由和测量数据包在网络中的延迟。
21. IPTState
IPTState 可以让你观察流量是如何通过 iptables,并通过你指定的条件来进行排序。该工具还允许你从 iptables 的表中删除状态信息。
22. darkstat
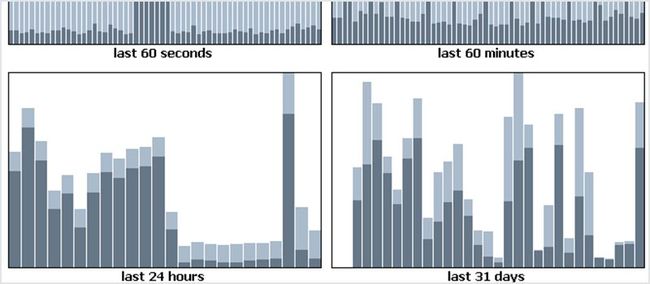
darkstat 能捕获网络流量并计算使用情况的统计数据。该报告保存在一个简单的 HTTP 服务器中,它为你提供了一个非常棒的图形用户界面。
23. vnStat
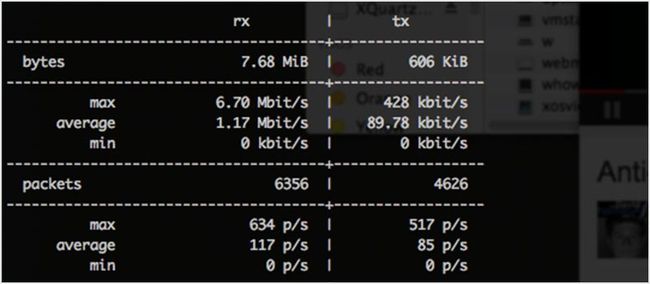
vnStat 是一个网络流量监控工具,它的数据统计是由内核进行提供的,其消耗的系统资源非常少。系统重新启动后,它收集的数据仍然存在。有艺术感的系统管理员可以使用它的颜色选项。
24. netstat
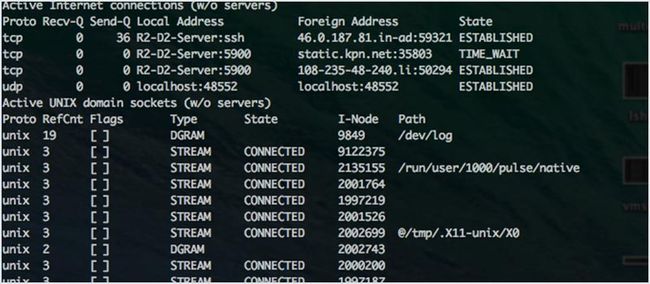
netstat 是一个内置的工具,它能显示 TCP 网络连接,路由表和网络接口数量,被用来在网络中查找问题。
25. ss
比起 netstat,使用 ss 更好。ss 命令能够显示的信息比 netstat 更多,也更快。如果你想查看统计结果的总信息,你可以使用命令 ss -s。
26. nmap
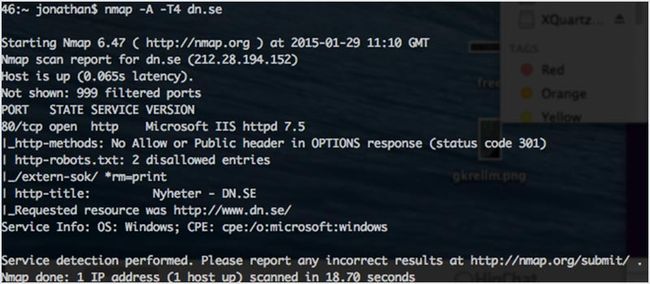
Nmap 可以扫描你服务器开放的端口并且可以检测正在使用哪个操作系统。但你也可以将其用于 SQL 注入漏洞、网络发现和渗透测试相关的其他用途。
27. MTR
MTR 将 traceroute 和 ping 的功能结合到了一个网络诊断工具上。当使用该工具时,它会限制单个数据包的跳数,然后监视它们的到期时到达的位置。然后每秒进行重复。
28. Tcpdump
Tcpdump 将按照你在命令行中指定的表达式输出匹配捕获到的数据包的信息。你还可以将此数据保存并进一步分析。
29. Justniffer
Justniffer 是 tcp 数据包嗅探器。使用此嗅探器你可以选择收集低级别的数据还是高级别的数据。它也可以让你以自定义方式生成日志。比如模仿 Apache 的访问日志。
与系统有关的监控
30. nmon
nmon 将数据输出到屏幕上的,或将其保存在一个以逗号分隔的文件中。你可以查看 CPU,内存,网络,文件系统,前列 进程。数据也可以被添加到 RRD 数据库中用于进一步分析。
31. conky
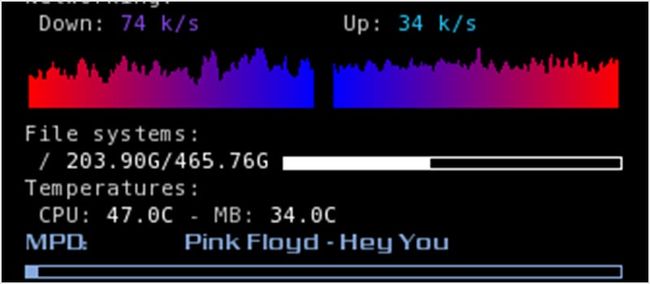
Conky 能监视很多的操作系统数据。它支持 IMAP 和 POP3, 甚至许多流行的音乐播放器!出于方便不同的人,你可以使用自己的 Lua 脚本或程序来进行扩展。
32. Glances
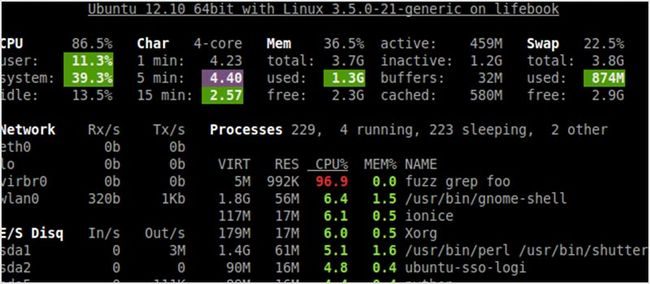
使用 Glances 监控你的系统,其旨在使用最小的空间为你呈现最多的信息。它可以在客户端/服务器端模式下运行,也有远程监控的能力。它也有一个 Web 界面。
33. saidar
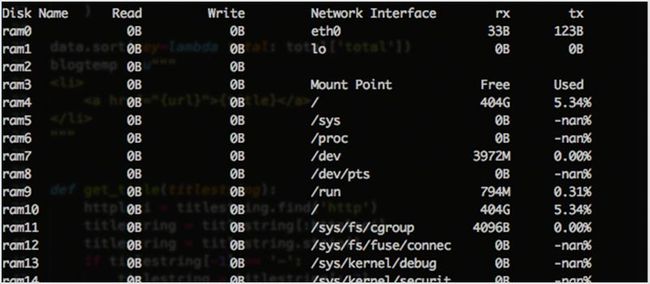
Saidar 是一个非常小的工具,为你提供有关系统资源的基础信息。它将系统资源在全屏进行显示。重点是 saidar 会尽可能的简化。
34. RRDtool
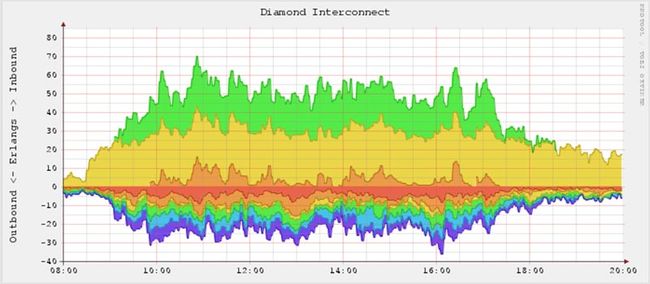
RRDtool 是用来处理 RRD 数据库的工具。RRDtool 旨在处理时间序列数据,如 CPU 负载,温度等。该工具提供了一种方法来提取 RRD 数据并以图形界面显示。
35. monit
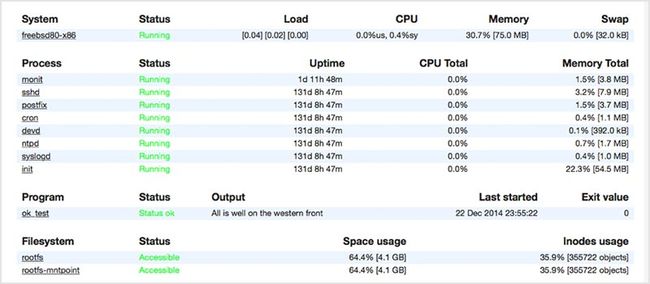
如果出现故障时,monit 有发送警报以及重新启动服务的功能。它可以对各种数据进行检查,你可以为 monit 写一个脚本,它有一个 Web 用户界面来分担你眼睛的压力。
36. Linux process explorer
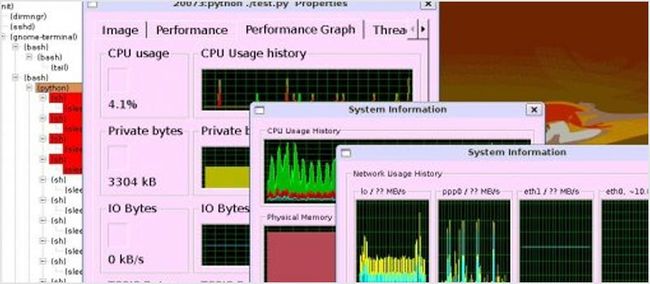
Linux process explorer 是类似 OSX 或 Windows 的活动监视器。它比 top 或 ps 的使用范围更广。你可以查看每个进程的内存消耗以及 CPU 的使用情况。
37. df
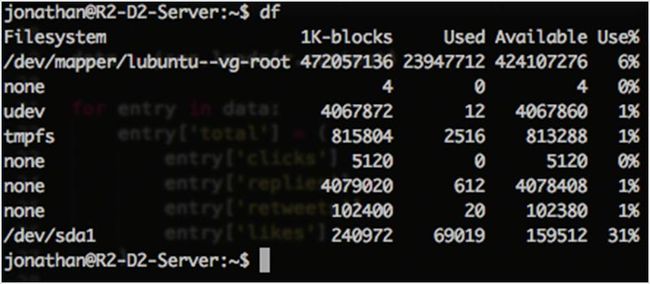
df 是 disk free 的缩写,它是所有 UNIX 系统预装的程序,用来显示用户有访问权限的文件系统的可用磁盘空间。
38. discus
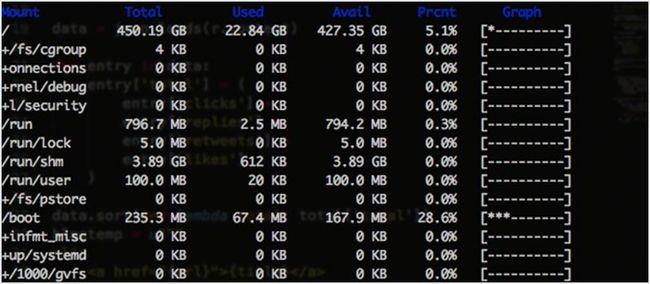
discus 类似于 df,它的目的是通过使用更吸引人的特性,如颜色,图形和数字来对 df 进行改进。
39. xosview
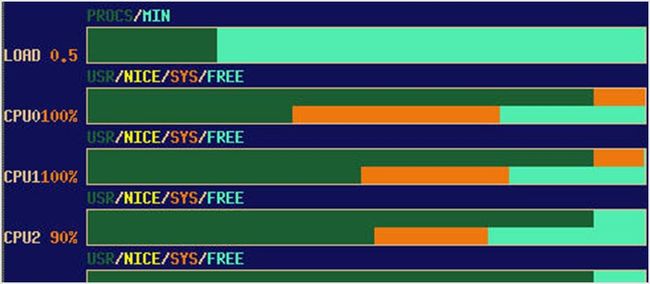
xosview 是一款经典的系统监控工具,它给你提供包括 IRQ 在内的各个不同部分的简单总览。
40. Dstat
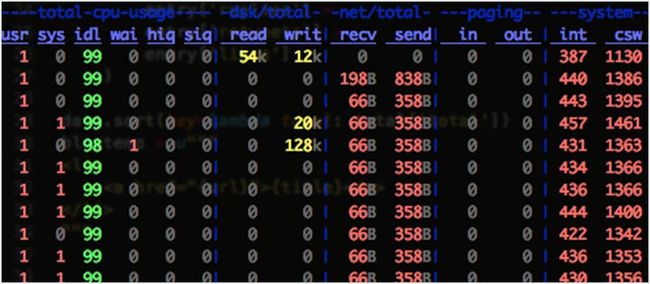
dstat 旨在替代 vmstat,iostat,netstat 和 ifstat。它可以让你查实时查看所有的系统资源。这些数据可以导出为 CSV。最重要的是 dstat 允许使用插件,因此其可以扩展到更多领域。
41. Net-SNMP
SNMP 即“简单网络管理协议”,Net-SNMP 工具套件使用该协议可帮助你收集服务器的准确信息。
42. incron
incron 允许你监控一个目录树,然后对这些变化采取措施。如果你想在目录‘a’中出现新文件时,将其复制到目录‘b’,这正是 incron 能做的。
43. monitorix
Monitorix 是轻量级的系统监控工具。它可以帮助你监控单独一台机器,并为你提供丰富的指标。它也有一个内置的 HTTP 服务器,来查看图表和所有指标的报告。
44. vmstat
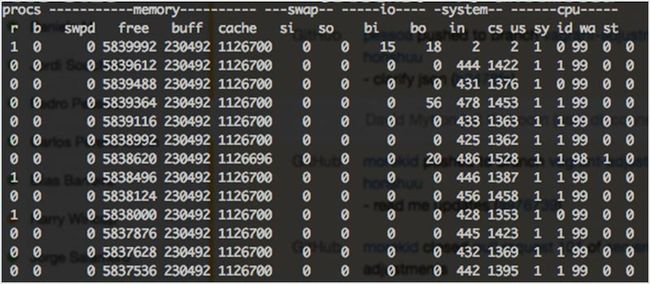
vmstat(virtual memory statistics)是一个小型内置工具,能监控和显示机器的内存。
45. uptime
这个小程序能快速显示你机器运行了多久,目前有多少用户登录和系统过去1分钟,5分钟和15分钟的平均负载。
46. mpstat
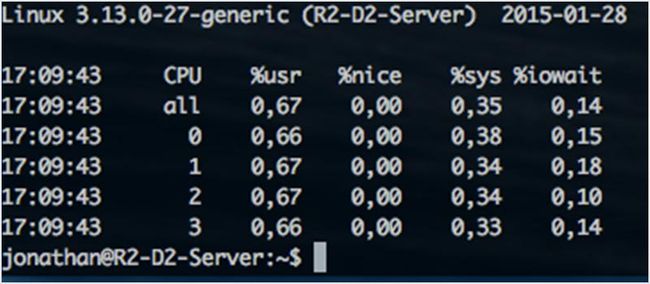
mpstat 是一个内置的工具,能监视 cpu 的使用情况。最常见的使用方法是 mpstat -P ALL,它给你提供 cpu 的使用情况。你也可以间歇性地更新 cpu 的使用情况。
47. pmap
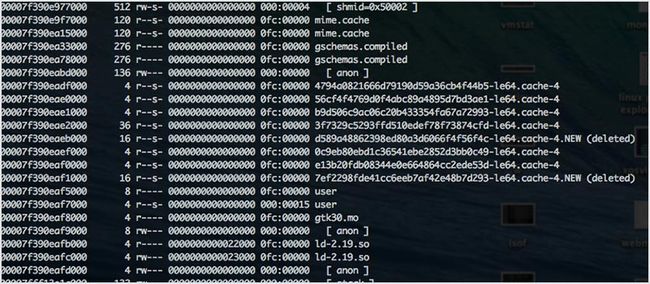
pmap 是一个内置的工具,报告一个进程的内存映射。你可以使用这个命令来找出导致内存瓶颈的原因。
48. ps
该命令将给你当前所有进程的概述。你可以使用 ps -A 命令查看所有进程。
49. sar
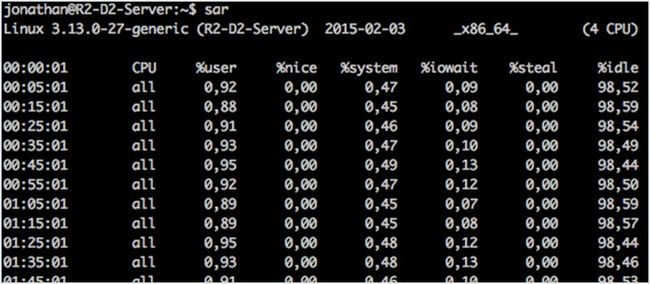
sar 是 sysstat 包的一部分,可以帮助你收集、报告和保存不同系统的指标。使用不同的参数,它会给你提供 CPU、 内存和 I/O 使用情况及其他东西。
50. collectl
类似于 sar,collectl 收集你机器的性能指标。默认情况下,显示 cpu、网络和磁盘统计数据,但它实际收集了很多信息。与 sar 不同的是,collectl 能够处理比秒更小的单位,它可以被直接送入绘图工具并且 collectl 的监控过程更广泛。
51. iostat
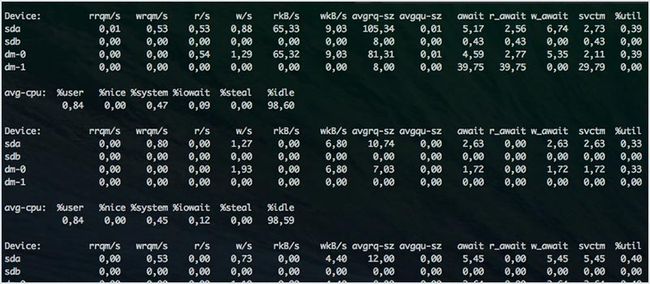
iostat 也是 sysstat 包的一部分。此命令用于监控系统的输入/输出。其报告可以用来进行系统调优,以更好地调节你机器上硬盘的输入/输出负载。
52. free
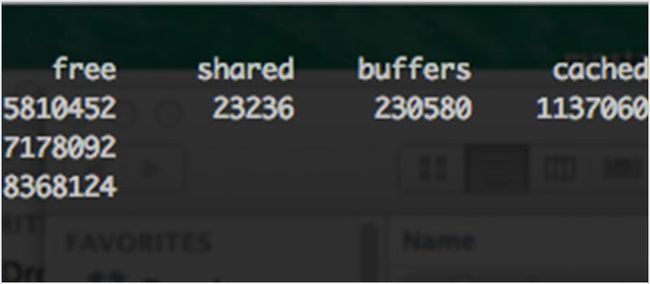
这是一个内置的命令,用于显示你机器上可用的内存大小以及已使用的内存大小。它还可以显示某时刻内核所使用的缓冲区大小。
53. /proc 文件系统
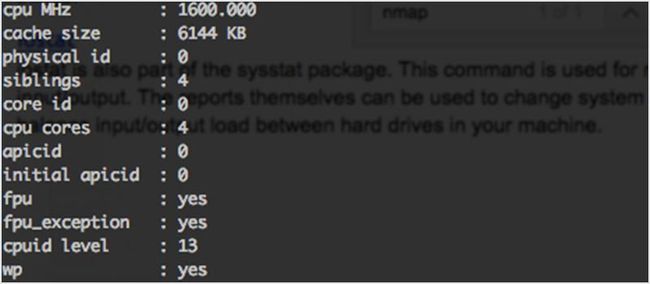
proc 文件系统可以让你查看内核的统计信息。从这些统计数据可以得到你机器上不同硬件设备的详细信息。看看这个 proc 文件统计的完整列表。
54. GKrellM
GKrellm 是一个图形应用程序,用来监控你硬件的状态信息,像CPU,内存,硬盘,网络接口以及其他的。它也可以监视并启动你所选择的邮件阅读器。
55. Gnome 系统监控器
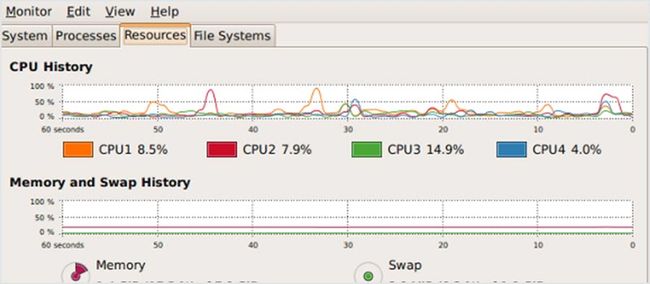
Gnome 系统监控器是一个基本的系统监控工具,其能通过一个树状结构来查看进程的依赖关系,能杀死进程及调整进程优先级,还能以图表形式显示所有服务器的指标。
日志监控工具
56. GoAccess
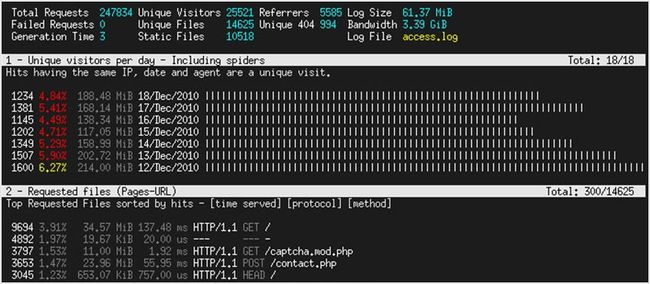
GoAccess 是一个实时的网络日志分析器,它能分析 apache, nginx 和 amazon cloudfront 的访问日志。它也可以将数据输出成 HTML,JSON 或 CSV 格式。它会给你一个基本的统计信息、访问量、404 页面,访客位置和其他东西。
57. Logwatch
Logwatch 是一个日志分析系统。它通过分析系统的日志,并为你所指定的部分创建一个分析报告。它每天给你一个报告,以便让你花费更少的时间来分析日志。
58. Swatch
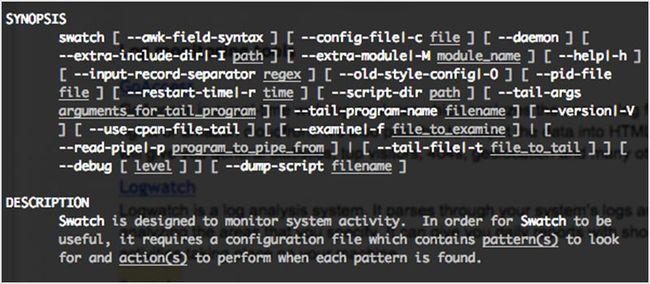
像 Logwatch 一样,Swatch 也监控你的日志,但不是给你一个报告,它会匹配你定义的正则表达式,当匹配到后会通过邮件或控制台通知你。它可用于检测入侵者。
59. MultiTail
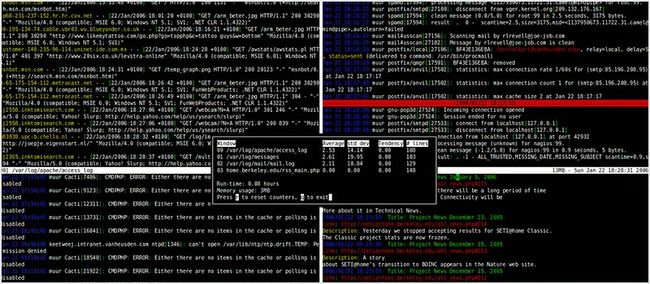
MultiTail 可帮助你在多个窗口之下监控日志文件。你可以将这些日志文件合并到一个窗口。它可以通过正则表达式的帮助,使用不同的颜色来显示日志文件以方便你阅读。
系统工具
60. acct or psacct
acct 也称 psacct(取决于如果你使用 apt-get 还是 yum)可以监控所有用户执行的命令,包括 CPU 时间和内存占用。一旦安装完成后你可以使用命令 sa 来查看统计。
61. whowatch
类似 acct,这个工具监控系统上所有的用户,并允许你实时查看他们正在执行的命令及运行的进程。它将所有进程以树状结构输出,这样你就可以清楚地看到到底发生了什么。
62. strace
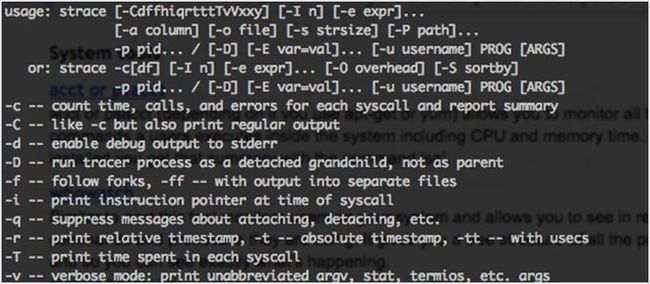
strace 被用于诊断、调试和监控程序之间的相互调用过程。最常见的做法是用 strace 打印系统调用的程序列表,其可以看出程序是否像预期那样被执行了。
63. DTrace
DTrace 可以说是 strace 的大哥。它动态地跟踪与检测代码实时运行的指令。它允许你深入分析其性能和诊断故障。但是,它并不简单,关于这个话题有1200本书之多。
64. webmin
Webmin 是一个基于 Web 的系统管理工具。它不需要手动编辑 UNIX 配置文件,可以让你远程管理系统。它有一对监控模块用于连接它。
65. stat
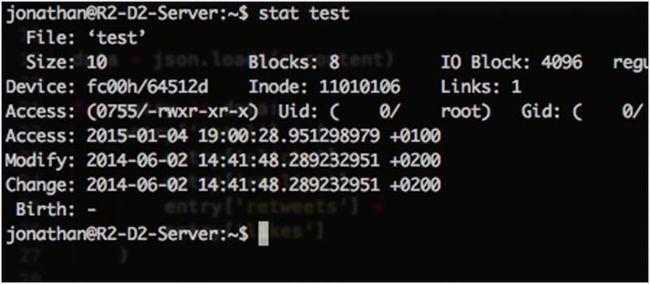
Stat 是一个内置的工具,用于显示文件和文件系统的状态信息。它会显示文件何时被修改、访问或更改。
66. ifconfig
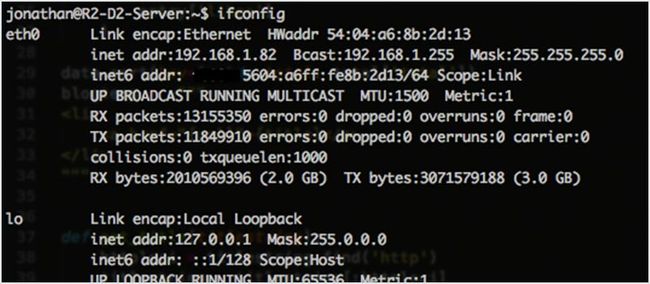
ifconfig 是一个内置的工具,用于配置网络接口。大多数网络监控工具背后都使用 ifconfig 将网卡设置成混乱模式来捕获所有的数据包。你可以手动执行 ifconfig eth0 promisc 进入混乱模式,使用ifconfig eth0 -promisc 返回正常模式。
67. ulimit
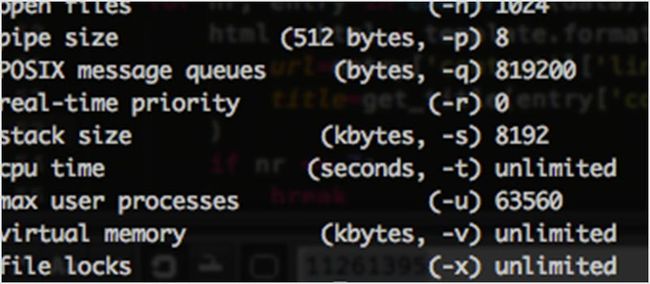
ulimit 是一个内置的工具,可监控系统资源,并可以限制任何监控资源不得超标。比如做一个 fork 炸弹,如果使用 ulimit 正确配置了将完全不受影响。
68. cpulimit
CPULimit 是一个小工具,用于监控并限制进程对 CPU 的使用率。其特别可以用于将批处理作业对 CPU 的使用率保持在一定范围。
69. lshw
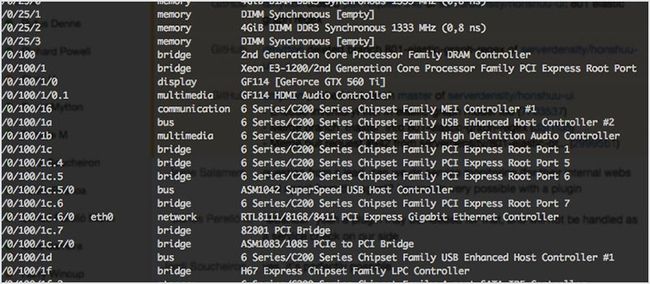
lshw 是一个小的内置工具,能提取关于本机硬件配置的详细信息。它可以输出 CPU 版本和主板配置。
70. w
w 是一个内置命令,用于显示当前登录用户的信息及他们所运行的进程。
71. lsof
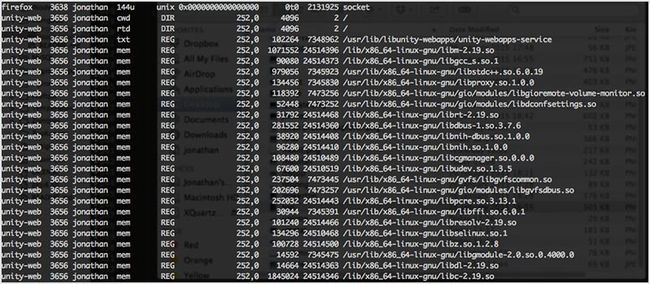
lsof 是一个内置的工具,可让你列出所有打开的文件和网络连接。从那里你可以看到文件是由哪个进程打开的,基于进程名可找到其特定的用户,或杀死属于某个用户的所有进程。
基础架构监控工具
72. Server Density
我们的 服务器监控工具 它有一个 web 界面,使你可以进行报警设置并可以通过图表来查看所有系统的网络指标。你还可以设置监控的网站,无论是否在线。Server Density 允许你设置用户的权限,你可以根据我们的插件或 api 来扩展你的监控。该服务已经支持 Nagios 的插件了。
73. OpenNMS
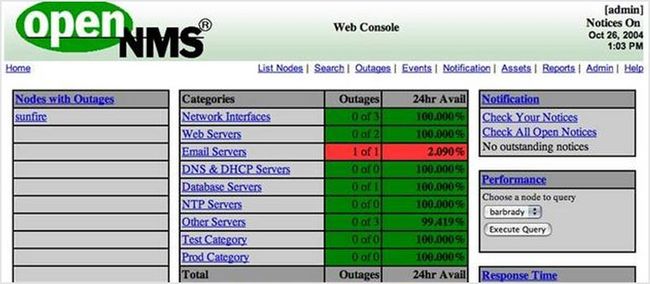
OpenNMS 主要有四个功能区:事件管理和通知;发现和配置;服务监控和数据收集。其设计为可被在多种网络环境中定制。
74. SysUsage
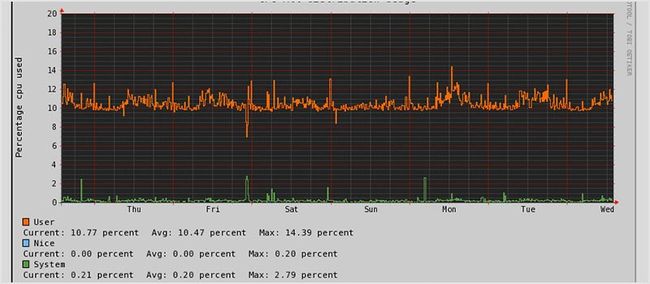
SysUsage 通过 Sar 和其他系统命令持续监控你的系统。一旦达到阈值它也可以进行报警通知。SysUsage 本身也可以收集所有的统计信息并存储在一个地方。它有一个 Web 界面可以让你查看所有的统计数据。
75. brainypdm
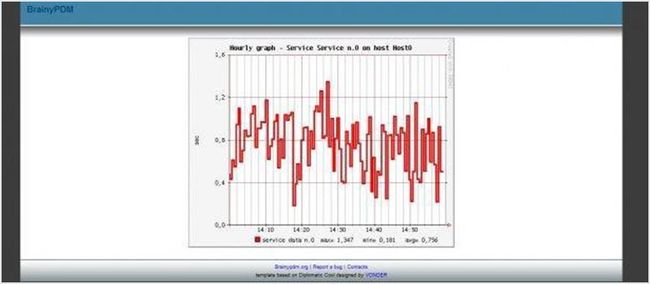
brainypdm 是一个数据管理和监控工具,它能收集来自 nagios 或其它常规来源的数据并以图表显示。它是跨平台的,其基于 Web 并可自定义图形。
76. PCP
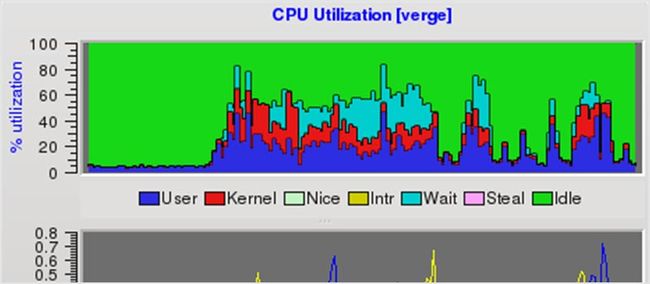
PCP 可以收集来自多个主机的指标,并且效率很高。它也有一个插件框架,所以你可以让它收集对你很重要的指标。你可以通过任何一个 Web 界面或 GUI 访问图形数据。它比较适合大型监控系统。
77. KDE 系统守护
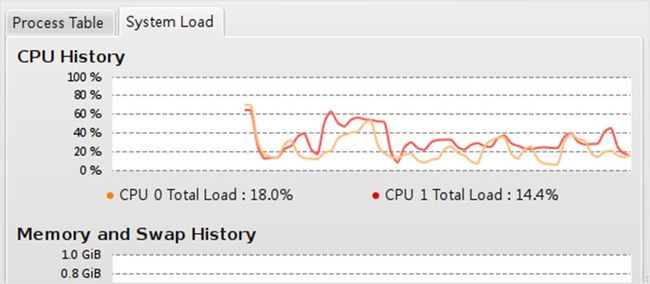
这个工具既是一个系统监控器也是一个任务管理器。你可以通过工作表来查看多台机器的服务指标,如果需要杀死一个进程或者你需要启动一个进程,它可以在 KDE 系统守护中来完成。
78. Munin
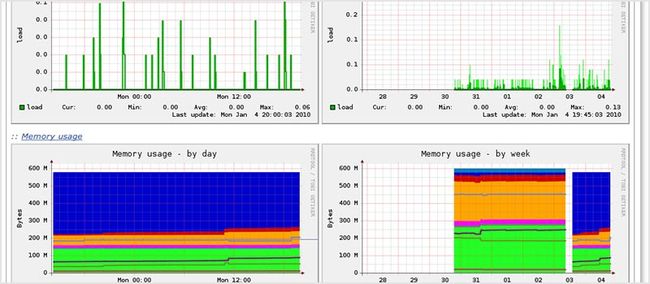
Munin 既是一个网络也是系统监控工具,当一个指标超出给定的阈值时它会提供报警机制。它运用 RRDtool 创建图表,并且它也有 Web 界面来显示这些图表。它更强调的是即插即用的功能并且有许多可用的插件。
79. Nagios

Nagios 是系统和网络监控工具,可帮助你监控多台服务器。当发生错误时它也有报警功能。它的平台也有很多的插件。
80. Zenoss
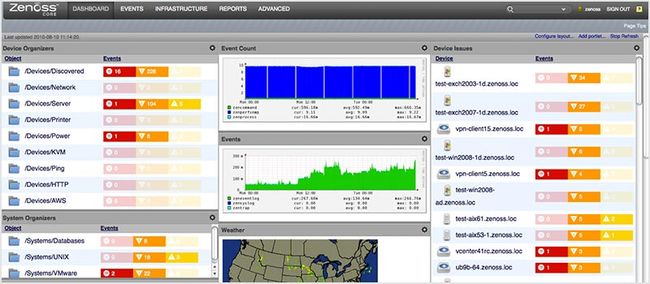
Zenoss 提供了一个 Web 界面,使你可以监控所有的系统及网络指标。此外,它能自动发现网络资源和修改网络配置。并且会提醒你采取行动,它也支持 Nagios 的插件。
81. Cacti
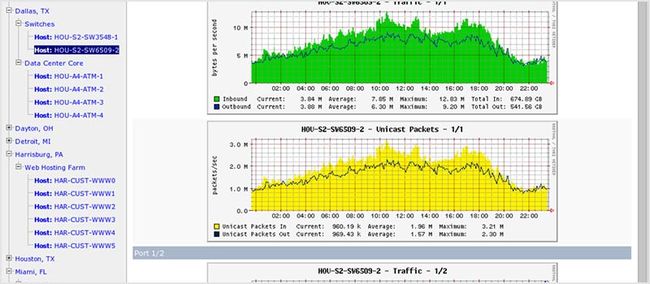
(和上一个一样!) Cacti 是一个网络图形解决方案,其使用 RRDtool 进行数据存储。它允许用户在预定的时间间隔进行投票服务并将结果以图形显示。Cacti 可以通过 shell 脚本扩展来监控你所选择的来源。
82. Zabbix
Zabbix 是一个开源的基础设施监控解决方案。它使用了许多数据库来存放监控统计信息。其核心是用 C 语言编写,并在前端中使用 PHP。如果你不喜欢安装代理端,Zabbix 可能是一个最好选择。
附加部分
感谢您的建议。这是我们的一个附加部分,由于我们需要重新编排所有的标题,鉴于此,这是在最后的一个简短部分,根据您的建议添加的一些 Linux 监控工具:
83. collectd
Collectd 是一个 Unix 守护进程,用来收集所有的监控数据。它采用了模块化设计并使用插件来填补一些缺陷。这样能使 collectd 保持轻量级并可进行定制。
84. Observium
Observium 是一个自动发现网络的监控平台,支持大量硬件平台和操作系统。Observium 专注于提供一个优美、功能强大、简单直观的界面来显示网络的健康和状态。
85. Nload
这是一个命令行工具来监控网络的吞吐量。它很整洁,因为它使用两个图表和其他一些类似传输的数据总量这样的有用数据来对进出站流量进行可视化。你可以使用如下方法安装它:
yum install nload
或者
sudo apt-get install nload
86. SmokePing
SmokePing 可以跟踪你网络延迟,并对他们进行可视化。有各种为 SmokePing 开发的延迟测量插件。如果图形用户界面对你来说非常重要,现在有一个正在开发中的插件来实现此功能。
87. MobaXterm
如果你整天在 windows 环境下工作。你可能会觉得 Windows 下终端窗口的限制。MobaXterm 正是由此而来的,它允许你使用多个通常出现在 Linux 中的命令。这将会极大地帮助你在监控方面的需求!
88. Shinken monitoring
Shinken 是一个监控框架,其是采用 python 对 Nagios 进行了完全重写。它的目的是增强灵活性和管理更大环境。但仍保持所有的 nagios 配置和插件。
via: https://blog.serverdensity.com/80-linux-monitoring-tools-know/
作者:Jonathan Sundqvist 译者:strugglingyouth 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出
http://www.oschina.net/news/70563/80-linux-monitoring-tools-know