分类决策树是一种描述对实例进行分类的属性结构,决策树由内部节点和叶节点,内部节点表示一个特征或者属性,叶节点表示一个类。
Part 1 :决策树生成
用决策树分类其实是一个if-then的过程,根据一个特征值的取值将原始的数据进行分类,比如,银行往往会根据个人情况和信用进行处理是否借贷,其评比条件如下图:

那么可能其中的一个决策树就会如下:

分类树也就是这样。
那么这个时候问题就来了,每次进行选取一个特征,如上面根节点是选取年龄还是选择有房子呢,这是第一个问题。
主要有两种算法进行计算,第一个是信息增益,另外一个是信息增益比,下面会来介绍一下这两种方式
1,信息增益
信息增益不用多介绍,在分类问题上被用了无数次,主要就是用来选取特征值,其本质就是尽量是各个类尽量平均,用在分类树上其实实质是为了减少分类树的不均衡,这一点其实在学习数据结构的时候我们都知道有个叫AVL树和红黑树,称之为平衡树,总体要求是使树的树枝高度不相差太多
信息增益计算公式:

2,信息增益比
信息增益比很容易计算,和信息增益差不多,只不过是信息增益与H(D)的比:
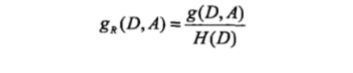
与特征选取的两种算法对应,决策树的生成也有两种算法:ID3和C4.5
ID3分类使用信息增益方法,C4.5分类使用信息增益比算法。
下面根据MLA 一书中的决策树一章使用Python语言实现一下决策树,书中使用的决策树算法是ID3,也就是使用信息增益方法进行分类选取。
原始问题的数据集如下:
dataset=[[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no']] labels=['no surfacing','flippers']
dataset每个项里面的最后一个数据是标签,也就是分类结果,前面两个是分类依据,第一个是代表是否有surfacing,第二个代表是否有flipper,现在需要根据这个数据集构建一颗决策树。
代码如下:
# -*- coding: UTF8 -*-
"""
author:luchi
date:16/2/17
theme:decision tree
desc:决策树的构建,使用ID3方法构建决策树
"""
from math import log
import operator
#计算熵值
def computeEnt(dataset):
m=len(dataset)
labels=[]
for i in range(m):
labels.append(dataset[i][-1])
labels=set(labels)
countLabel={}
for i in range(m):
clabel=dataset[i][-1]
if not countLabel.has_key(clabel):
countLabel[clabel]=1
else:
t=countLabel[clabel]+1
countLabel[clabel]=t
retEnt=0.0
for label in labels:
prob=float(countLabel[label])/m
retEnt-=prob*log(prob,2)
return retEnt
#产生数据集
def createDataset():
dataset=[[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no']]
labels=['no surfacing','flippers']
return dataset,labels
"""
根据标签分割数据集
params:
dataset:原始数据集
"""
def splitDataset(dataset,axis,value):
m=len(dataset)
retDataset=[]
for i in range(m):
if dataset[i][axis]==value:
l=dataset[i][:axis]
l.extend(dataset[i][axis+1:])
retDataset.append(l)
return retDataset
"""
获取最好的分组条件
"""
def getBestSlpit(dataset,labels):
m=len(dataset[0])-1
bestEnt=0.0
bestAxis=0
ent=computeEnt(dataset)
length=len(dataset)
for i in range(m):
l=[example[i] for example in dataset] #计算每一个特征值的数组
l=set(l) #不重复
infoEnt=0.0
for feature in l:
tempSet=splitDataset(dataset,i,feature)
size=len(tempSet)
prob=float(size)/length
infoEnt+=prob*computeEnt(tempSet)
infoEnt=ent-infoEnt
if(infoEnt>bestEnt):
bestEnt=infoEnt
bestAxis=i
return bestAxis
"""
在选出了最好的分组之后,在分组终止之后,就需要判断其类别
采用的是最大投票的方法,也就是哪个类别多就这个分组为其类别
"""
def chooseClassLabel(dataset):
labels=[example[-1] for example in dataset]
labels=set(labels)
labelCounts={}
for i in range(len(dataset)):
l=dataset[i][-1]
if not labelCounts.has_key(l):
labelCounts[l]=1
else:
m=labelCounts[l]+1
labelCounts[l]=m
sortedLabelCounts=sorted(labelCounts.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedLabelCounts[0][0]
"""
递归的构造决策树
"""
def buildDecisionTree(dataset,labels):
#判断终止条件
classList=[example[-1] for example in dataset]
uniClassList=set(classList)
if len(uniClassList)==1 :
return classList[0]
if len(dataset[0])==1:
return chooseClassLabel(dataset)
bestFeat=getBestSlpit(dataset,labels)
bestFeatLabel=labels[bestFeat] #最好的分类标签
myTree={bestFeatLabel:{}}
del(labels[bestFeat])
featValues=[example[bestFeat] for example in dataset]
uniFeat=set(featValues)
for value in uniFeat:
subLabels=labels[:]
myTree[bestFeatLabel][value]=buildDecisionTree(splitDataset(dataset,bestFeat,value),subLabels)
return myTree
if __name__=="__main__" :
dataset,labels=createDataset()
# ent=computeEnt(dataset)
# print ent
# newdateset=splitDataset(dataset ,0,1)
# print newdateset
# label=chooseClassLabel(dataset)
# print label
# bestEnt,bestAxis=getBestSlpit(dataset,labels)
# print bestEnt
# print bestAxis
mytree=buildDecisionTree(dataset,labels)
print mytree
运行结果如下:
![]()
使用图形表达出来就是下图:
Part 2:决策树剪枝
决策树生成完毕,也会产生一些问题,就是和所有机器学习问题一样,会产生过拟合问题,表现在决策树上,就是分类的树过于复杂,对部分特征学习过度,忽略了整体特征。解决其问题就是剪枝。
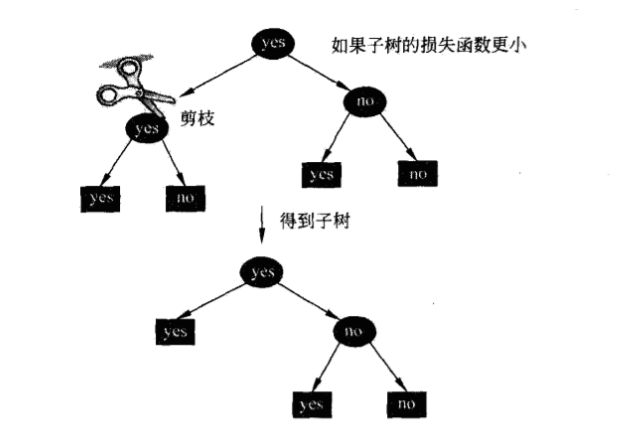
如上图所示,如果一棵树的不剪枝的损失函数值大于剪枝后的损失函数值的话,那么就将子节点合并到其父节点上。决策树剪枝实质上是将一些叶节点合并到其父节点上,以此递归实现。
决策树剪枝算法也有很多种,具体见【1】P65-P67,这里不细述。
附1: 关于CART算法
CART算法可以用于决策树的生成,生成过程和上面的ID3算法大同小异,区别在于其特征选取的方法是基尼指数,听着挺高端,其实也不过是一种新的计算方法,没什么特殊的。也就是说上面的程序将信息增益的方法改变成基尼指数方法就可以了
附2:决策树与回归树
决策树是用来分类的,而回归树是一种预测模型。回归树和所有回归方法一样,根据已知的数据构造数据模型,然后根据需要预测对象的参数输出预测结果,回归问题会在后面的讲回归的章节中描述,所以这里不在具体描述。
参考文献:
【1】 统计学习方法,李航
【2】Machine Learning in Action