零基础汇编学习笔记
第一章基础知识
- 1. 数据总线的宽度为16位的,可以一次传送16位个0、1数据。数据总线的宽度决定了CPU和外界的数据传送速度。
- 2. 地址总线决定了最多可以寻找2的N次方个内存单元,地址总线的宽度为20位,所以可以访问的地址单元为2^20个地址,为1M,一般使用5位16进制表示。
地址加法器合成物理地址的方法:物理地址=段地址×16+偏移地址
各个寄存器都是16位的,所以还需要通过“加工”进位配够5位的地址。8086内部为16位结构,它只能传送16位的地址,内部偏移地址也为16位,表现出的寻址能力却只有2^16次方,也就是64K大小,所以每段大小不超过64k的寻址。
- 3. 控制总线:CPU对外部器件的控制是通过控制总线来进行的。有多少根控制总线,就意味着CPU提供了对外部器件的多少种控制。所以,控制总线的宽度决定了CPU对外部器件的控制能力。
- 4. 一个存储单元可以存储8 个bit (用作单位写成“b”),即8 位二进制数。
1B = 8b 1KB = 1024B 1MB = 1024KB 1GB = 1024MB
- 5. 内存地址空间
地址0~7FFFH的32KB空间为主随机存储器的地址空间;
地址8000H~9FFFH的8KB空间为显存地址空间;
地址A000H~FFFFH的24KB空间为各个ROM的地址空间。
第二章寄存器
- 1. 8086CPU有14个寄存器它们的名称为:
AX、BX、CX、DX、SI、DI、SP、BP、IP、CS、SS、DS、ES、PSW。
- 2. 段寄存器
内存并没有分段,而是人为的定义段,段的划分来自于CPU,由于8086CPU用“(段地址×16)+偏移地址=物理地址”的方式给出内存单元的物理地址,使得我们可以用分段的方式来管理内存。将若干地址连续的内存单元看作一个段,用段地址×16定位段的起始地址(基础地址),用偏移地址定位段中的内存单元。
8086CPU有4个段寄存器:
CS、DS、SS、ES
当8086CPU要访问内存时,由这4个段寄存器提供内存单元的段地址。
- 3. 代码段
CS和IP是8086CPU中最关键的寄存器,它们指示了CPU当前要读取指令的地址。
CS为代码段寄存器;
IP为指令指针寄存器。
- 4. 同时修改CS、IP的内容:
jmp 段地址:偏移地址
如:jmp 13BC:0160
功能:用指令中给出的段地址修改CS,偏移地址修改IP。
仅修改IP的内容:
jmp 某一合法寄存器或数字
jmp ax (类似于mov IP,ax)
jmp 300
功能:用寄存器中的值修改IP。
第三章寄存器(内存访问)
- 1. 数据段地址DS和[address]
在8086PC中,内存地址由段地址和偏移地址组成。
DS寄存器,通常用来存放要访问的数据的段地址。
例如:mov指令
mov指令的格式:mov 寄存器名,内存单元地址
“[…]”表示一个内存单元,“[…]”中的数字表示内存单元的偏移地址。
执行指令时,8086CPU自动读取DS中的数据为内存单元的数据段地址,然后根据偏移地址读取数据。
再例如用mov al,[0]完成传送(mov指令中的[]说明操作对象是一个内存单元,[]中的0说明这个内存单元的偏移地址是0,它的段地址默认放在ds中)
- 2. 栈操作
ss,表示栈基址,sp表示当前栈指针位置。
使用push入栈,pop进行出栈
栈空时:sp为栈长度+1
栈满时:sp=ss
第四章第一个程序
- 1. 编译和链接
编译:使用masm命令进行编译,默认会生成一个obj文件
链接:使用Link命令进行链接,将编译生成的obj文件链接成exe文件
简化的编译链接在每个命令的后面加上分号“;”,也可使用ML命令直接生成exe文件
第五章 [bx]和loop指令
- 1. 寄存器一般作用
Bx一般用于数据地址的偏移量
Cx一般和loop联合使用,到0时结束loop的循环
- 2. 安全退出程序
安全退出程序必须使用如下两句
mov ax,4c00h
int 21h
验证:编译链接后生成exe程序,然后用debug载入,当运行到mov ax,4c00H的时候按p命令运行完结束程序,则会在命令提示符下显示“Program terminated normally”
- 3. Debug命令
G命令:直接执行到指定的IP地址,可用于跳出循环
P命令:Debug就会自动重复执行循环中的指令,直到(cx)=0为止。跳出循环执行到循环后的一条命令
- 4. mov ax,0ffffh。
在使用mams编译我们的汇编源程序的时候,我们知道大于9FFFH的十六进制数据A000H、A001H、C000H、FFFEH、FFFFH等,在书写的时候都是以字母开头的。而在汇编源程序中,数据不能以字母开头,所以要在前面加0。
- 5. 一段安全内存空间
在一般的PC机中,DOS方式下,DOS和其他合法的程序一般都不会使用0:200~0:2FF的256 个字节的空间。所以,我们使用这段空间是安全的。
例如“mov 0:26H,ax”语句会将内存0:26H的内容改写,则会引起程序崩溃。
第六章包含多个段的程序
- 1. 程序的多个段
程序中我们一般会定义多个段来存放我们的数据、代码和栈。而“代码段”、“数据段”、“栈段”完全是我们自己的安排。例如:我们在源程序中用伪指令“assume cs:code,ds:data,ss:stack”将cs、ds和ss分别和code、data、stack段相连。这样做了之后,CPU是否就会将cs指向code,ds 指向data,ss 指向stack,从而按照我们的意图来分别不同的方式处理这些段中的数据。
第七章灵活的寻址方法
- 1. 字母大小写转换
ASCII字母的大小写之间相差20H,十进制也就是32,例如
大写字母A(01000001)小写字母a(01100001),二进制只有第五位有区别。所以只要第五位置0就是大写字母,置1就是小写字母,所以配合or和and命令就可完成操作。
and al,11011111B 结果为小写
or al,00100000B 结果为大写
- 2. SI和DI寄存器
SI和DI寄存器和BX功能相近,但是SI和DI不能够分成两个8位的寄存器来使用。
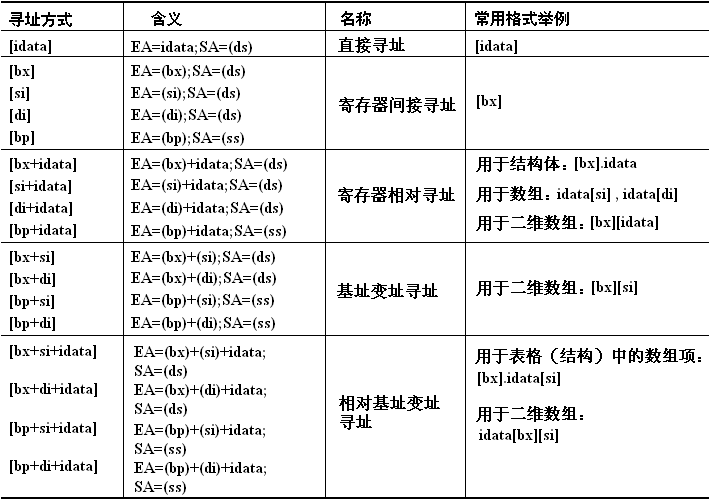
- 3. 寻址方式
几种定位内存地址的方法(可称为寻址方式),有以下几种方式:
(1)[idata] 用一个常量来表示地址,可用于直接定位一个内存单元;
(2)[bx]用一个变量来表示内存地址,可用于间接定位一个内存单元;
(3)[bx+idata] 用一个变量和常量表示地址,可用于间接定位一个内存单元;
(4)[bx+si]用两个变量表示地址;
(5)[bx+si+idata] 用两个变量和一个常量表示地址。
- 4. 寻址表示形式
例如指令mov ax,[bx+200]也可以写成如下格式(常用):
mov ax,[200+bx]
mov ax,200[bx]
mov ax,[bx].200
指令mov ax,[bx+si+idata]也可以写成如下格式(常用):
mov ax,[bx+200+si]
mov ax,[200+bx+si]
mov ax,200[bx][si]
mov ax,[bx].200[si]
mov ax,[bx][si].200
第八章数据处理的两个基本问题
- 1. 可寻址寄存器
1)在8086CPU 中,只有这4个寄存器(bx、bp、si、di)可以用在“[…]”中来进行内存单元的寻址。如果在“[…]”中程序ax、cx、dx、ds等都是错误的方式。
2)在“[…]”中,这4个寄存器(bx、bp、si、di)可以单个出现,或只能以四种组合出现:(bx和si、bx和di、bp和si、bp和di) 错误的组合:(bx和bp、si和di)
3)只要在[…]中使用寄存器bp,而指令中没有显性的给出段地址,段地址就默认在ss中。比如:
mov ax,[bp] 含义:(ax)=((ss)*16+(bp))
mov ax,[bp+idata] 含义:(ax)=((ss)*16+(bp)+idata)
mov ax,[bp+si] 含义:(ax)=((ss)*16+(bp)+(si))
mov ax,[bp+si+idata] 含义:(ax)=((ss)*16+(bp)+(si)+idata)
常用的几种寻址方式:
- 2. 数据的位置
汇编语言中用三个概念来表达数据的位置。
1、立即数(idata)
2、寄存器
3、段地址(SA)和偏移地址(EA)
- 3. 指令要处理的数据有多长?
1) 通过寄存器名指明要处理的数据的尺寸。例如:
mov ax,ds:[0]
mov ax,[bx]
mov ah,[2+bx]
mov al,ds:[2]
2) 在没有寄存器名存在的情况下,用操作符X ptr指明内存单元的长度,X在汇编指令中可以为word或byte。
例如:使用word ptr指明了指令访问的内存单元是一个字单元
mov word ptr ds:[0],1
inc word ptr [bx]
inc word ptr ds:[0]
add word ptr [bx],2
例如:使用byte ptr指明了指令访问的内存单元是一个字节单元
mov byte ptr ds:[0],1
inc byte ptr [bx]
inc byte ptr ds:[0]
add byte ptr [bx],2
3) 其他方法
例如:push和pop操作,都是对字单元操作,比如sp+2或sp-2等
- 4. Div指令
div是除法指令,我们知道除法的数学表达式:被除数÷除数=商……余数
div指令格式:div 除数
除数可以是寄存器或内存单元,例如
div 寄存器
div 内存单元
- 5. 使用div指令的说明:
被除数:(默认)放在AX 或DX和AX中
除数:8位或16位,在寄存器或内存单元中
结果:
| 除数位数 |
8位 |
16位 |
| 被除数 |
AX |
AX+DX |
| 除数 |
寄存器或内存单元 |
寄存器或内存单元 |
| 商 |
AL |
AX |
| 余数 |
AH |
DX |
|
|
|
|
- 6. div指令示例说明
例div byte ptr ds:[0]
商数为:(al)=(ax)/((ds)*16+0)
余数为:(ah)=(ax)/((ds)*16+0)
例div word ptr es:[0]
商数为:(ax)=[(dx)*10000H+(ax)]/((ds)*16+0)的商;
余数为:(dx)=[(dx)*10000H+(ax)]/((ds)*16+0)的余数
说明:当除数为16位时,被除数需要用dx和ax存放,dx存放的是数字的高16位,而ax存放的是数字的低16位,例如:0c85 6ef7H÷1c3dH=7183H……0ec0H (数字都是用16进制表示),则计算前默认0c85存储在dx中,6ef7存储在ax中,计算后则商7183H存储在ax中,余数0ec0H存储在dx中。
- 7. 伪指令dd
前面我们用db定义字节型数据、用dw定义字型数据。
dd是用来定义dword (double word双字)型数据的。
例如:在data段中定义了三个数据
示例(1):
data segment
db 1;第一个数据为01H,在data:0处,占1个字节;
dw 1;第二个数据为0001H,在data:1处,占1个字;
dd 1;第三个数据为00000001H,在data:3处,占2个字节;
data ends
示例(2):
code segment
dd 12345678h ;定义一个十六进制的数12345678
mov ax,bx
code ends
我们编译、链接后,用debug载入,查看当前代码段定义的数据,如下:
-d 145b:0
145B:0000 78 56 34 12 8B C3 00 00-00 00 00 00 00 00 00 00
从上面的代码我们可以看出使用dd定义的数据在内存中的存储形式:78 56 34 12
- 8. 伪指令dup
dup是一个重复操作符,在汇编语言中同db、dw、dd 等一样,也是由编译器识别处理的符号。它是和db、dw、dd 等数据定义伪指令配合使用的,用来进行数据的重复。
dup示例
db 3 dup (0)
定义了3个字节,它们的值是0、0、0,相当于db 0,0,0
db 3 dup (0,1,2)
定义了9个字节,它们是0、1、2、0、1、2、0、1、2,相当于db 0,1,2,0,1,2,0,1,2
db 3 dup (“abc”,”ABC”)
定义了18个字节,它们是”abcABCabcABCabcABC”,相当于db “abcABCabcABCabcABC”
dup的使用格式如下:
db 重复的次数dup (重复的字节型数据)
dw 重复的次数dup (重复的字型数据)
dd 重复的次数dup (重复的双字数据)
比如我们要定义一个容量为200 个字节的栈段,如果不用dup,则必须用这样的格式:
stack segment
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
stack ends
当然,读者可以用dd,使程序变得简短一些,但是如果要求定义一个容量为1000字节或10000字节的呢?如果没有dup,定义部分的程序就变得太长了;有了dup就可以轻松解决。如下:
stack segment
db 200 dup (0)
stack ends
第九章转移指令的原理
- 1. 伪指令offset
操作符offset在汇编语言中是由编译器处理的符号,它的功能是取得标号的偏移地址。
例如:将s处的一条指令复制到s0处
s: mov ax,bx ;(mov ax,bx 的机器码占两个字节)
mov si,offset s
mov di,offset s0
mov ax,cs:[si]
mov cs:[di],ax
s0: nop ;(nop的机器码占一个字节)
nop
- 2. jmp指令
jmp为无条件转移,可以只修改IP,也可以同时修改CS和IP;
jmp指令要给出两种信息:
1)转移的目的地址
2)转移的距离(段间转移、段内短转移,段内近转移)
- 3. jmp原理
1) jmp short 标号(转到标号处执行指令,是段内短转移)
指令“jmp short 标号”的功能为:(IP)=(IP)+8位偏移。
这种格式的jmp 指令实现的是段内短转移,它对IP的修改范围为-128~127,也就是说,它向前转移时可以最多越过128个字节,向后转移可以最多越过127个字节。
说明:jmp的机器码指令是距离当前指令的偏移地址,例如
程序源码(1):
assume cs:codesg
codesg segment
start:mov ax,0
jmp short s
add ax,1
s:inc ax
codesg ends
end start
使用-u命令查看对应的机器码如下:
-u
145B:0000 B80000 MOV AX,0000
145B:0003 EB03 JMP 0008
145B:0005 83C001 ADD AX,+01
145B:0008 40 INC AX
程序源码(2):
assume cs:codesg
codesg segment
s:inc ax
start:mov ax,0
jmp short s
add ax,1
codesg ends
end start
使用-u命令查看对应的机器码如下:
-u 0
145B:0000 40 INC AX
145B:0001 B80000 MOV AX,0000
145B:0004 EBFA JMP 0000
145B:0006 83C001 ADD AX,+01
上面的两段源码只是修改了s标号的位置,其他的代码完全相同,通过源码和对应的机器码查看jmp命令,可以看出EB是jmp命令的机器码,而后面的数字03和FA是对应跳转的当前指令的偏移地址,通过这个数字可以看出FA应该是负数(-10:负数用补码形式表示:即正数源码取反加1),也就是对应的当前指令的偏移地址,由于是使用一个字节表示,所以数据大小只能是一个字节内的跳转,范围为-128~127之间。
2)jmp near ptr 标号 (段内近转移)
它实现的时段内近转移。
指令“jmp near ptr 标号”的功能为:(IP)=(IP)+16位偏移。
3)jmp far ptr 标号(段间转移)
实现的是段间转移,又称为远转移。例如:
程序源码:
jmp far ptr s
db 256 dup (0)
s: add ax,1
使用-u命令查看对应的机器码如下:
145B:0004 EA0B01BD0B JMP 0BBD:010B
总结:
1)指令“jmp short 标号”的功能为(IP)=(IP)+8位位移。
(1)8位位移=“标号”处的地址-jmp指令后的第一个字节的地址;
(2)short指明此处的位移为8位位移;
(3)8位位移的范围为-128~127,用补码表示
(4)8位位移由编译程序在编译时算出。
2)指令“jmp near ptr 标号”的说明:
(1)16位位移=“标号”处的地址-jmp指令后的第一个字节的地址;
(2)near ptr指明此处的位移为16位位移,进行的是段内近转移;
(3)16位位移的范围为-32769~32767,用补码表示;
(4)16位位移由编译程序在编译时算出。
3)指令“jmp far ptr 标号”功能如下:
(CS)=标号所在段的段地址;
(IP)=标号所在段中的偏移地址。
far ptr指明了指令用标号的段地址和偏移地址修改CS和IP。
4)jmp 16位寄存器
功能:IP =(16位寄存器)
Jmp 内存单元地址
5)jmp word ptr 内存单元地址(段内转移)
功能:从内存单元地址处开始存放着一个字,是转移的目的偏移地址。
6)jmp dword ptr 内存单元地址(段间转移)
功能:从内存单元地址处开始存放着两个字,高地址处的字是转移的目的段地址,低地址处是转移的目的偏移地址。
(CS)=(内存单元地址+2)
(IP)=(内存单元地址)
内存单元地址可用寻址方式的任一格式给出。
例如:程序源码
assume cs:codesg
data segment
db 16 dup(0)
data ends
codesg segment
start:mov ax,data
mov ds,ax
mov ax,1234h
mov bx,5678h
mov ds:[0],ax
mov ds:[2],bx
jmp dword ptr ds:[0]
mov ax,1
codesg ends
end start
代码执行到跳转指令之前使用-d和-u命令查看对应的机器码如下:
-d 0 2f
145B:0000 34 12 78 56 00 00 00 00 00-00 00 00 00 00 00 00 00
145B:0010 B8 5B 14 8E D8 B8 34 12-BB 78 56 A3 00 00 89 1E
145B:0020 02 00 FF 2E 00 00 B8 01-00 00 00 00 00 00 00 00
-u 0 19
145C:0000 B85B14 MOV AX,145B
145C:0003 8ED8 MOV DS,AX
145C:0005 B83412 MOV AX,1234
145C:0008 BB7856 MOV BX,5678
145C:000B A30000 MOV [0000],AX
145C:000E 891E0200 MOV [0002],BX
145C:0012 FF2E0000 JMP FAR [0000]
145C:0016 B80100 MOV AX,0001
145C:0019 0000 ADD [BX+SI],AL
执行跳转命令后CS和IP的值分别是:
145C:0012 FF2E0000 JMP FAR [0000]
CS=5678 IP=1234
通过以上程序可以说明:
(IP)=(内存单元地址)
(CS)=(内存单元地址+2)
- 4. 负数的表示----补码
负数(补码) =正数原码取反加1
- 5. jcxz指令
jcxz指令为有条件转移指令,所有的有条件转移指令都是短转移,在对应的机器码中包含转移的位移,而不是目的地址。对IP的修改范围都为-128~127。
指令格式:jcxz 标号(如果(cx)=0,则转移到标号处执行。)
- 6. Loop指令
loop指令为循环指令,所有的循环指令都是短转移,在对应的机器码中包含转移的位移,而不是目的地址。对IP的修改范围都为-128~127。
指令格式:loop 标号 ((cx))=(cx)-1,如果(cx)≠0,转移到标号处执行。
loop 标号指令操作:
(1)(cx)=(cx)-1;
(2)如果(cx)≠0,(IP)=(IP)+8位位移。
8位位移=“标号”处的地址-loop指令后的第一个字节的地址;
8位位移的范围为-128~127,用补码表示;
8位位移由编译程序在编译时算出。
当(cx)=0,什么也不做(程序向下执行)。
第十章 call和ret指令
- 1. Call指令
CPU执行call指令,进行两步操作:
(1)将当前的IP 或CS和IP 压入栈中;
(2)转移。
语法格式:call 标号(实现的是段内转移)
16位位移=“标号”处的地址-call指令后的第一个字节的地址;
16位位移的范围为-32768~32767,用补码表示;
16位位移由编译程序在编译时算出。
CPU 执行指令“call 标号”时,相当于进行:
push IP
jmp near ptr 标号
语法格式:call far ptr 标号(实现的是段间转移)
CPU 执行指令“call far ptr 标号”时,相当于进行:
push CS
push IP
jmp far ptr 标号
说明:call 指令不能实现短转移,除此之外,call指令实现转移的方法和jmp 指令的原理相同。
- 2. Ret指令和retf指令
ret指令用栈中的数据,修改IP的内容,从而实现近转移;
CPU执行ret指令时,相当于进行:pop IP
retf指令用栈中的数据,修改CS和IP的内容,从而实现远转移;
CPU执行retf指令时,相当于进行:pop IP再pop CS
- 3. 转移地址在寄存器中的call指令
指令格式:call 16位寄存器
说明:由于寄存器为16位,使用这种方式只能是段内转移。
CPU执行call 16位reg时,相当于进行:
push IP
jmp 16位寄存器
- 4. 转移地址在内存中的call指令
有两种格式:
1)call word ptr 内存单元地址
CPU执行call word ptr时,相当于进行:
push IP
jmp dword ptr 内存单元地址
2) call dword ptr 内存单元地址
CPU执行call dword ptr时,相当于进行:
push CS
push IP
jmp dword ptr 内存单元地址
- 5. mul 指令
mul是乘法指令,使用mul 做乘法的时候:
(1)相乘的两个数:要么都是8位,要么都是16位,不能一个8位和一个16位相乘。
8 位乘法:默认使用AL中乘于8位寄存器或内存字节单元;
16 位乘法:默认使用AX中乘于16 位寄存器或内存字单元中。
(2)相乘的结果
8位乘法:结果保存在AX中;
16位乘法:结果保存在DX(高位)和AX(低位)中。
格式如下:
Mul reg
Mul 内存单元
内存单元可以用不同的寻址方式给出
- 6. 子程序参数和结果传递
1)可以用寄存器来存储参数和结果
2) 可以使用内存单元(各栈段)来存储参数和结果(一般只传首地址)
第十一章标志寄存器
- 1. 8086CPU的flag寄存器的结构:
| 15 |
14 |
13 |
12 |
11 |
10 |
9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
|
|
|
|
OF |
DF |
IF |
TF |
SF |
ZF |
|
AF |
|
PF |
|
CF |
flag的1、3、5、12、13、14、15位在8086CPU中没有使用,不具有任何含义。而0、2、4、6、7、8、9、10、11位都具有特殊的含义。
标志位在内存中的符号表示:
| 标志 |
含义说明 |
值为1的标记 |
值为0的标记 |
| 第11位OF |
溢出标志,有是1,无是0 |
OV |
NV |
| 第10位DF |
SI和DI方向标志,递增0,递减1 |
DN |
UP |
| 第9位IF |
单步调试标志,为1进行单步调试 |
EI |
DI |
| 第7位SF |
符号标志,正数是0,负数是1 |
NG |
PL |
| 第6位ZF |
操作结果为零标志 |
ZR |
NZ |
| 第4位AF |
|
AC |
NA |
| 第2位PF |
奇偶标志,偶是1,奇是0 |
PE |
PO |
| 第0位CF |
进借位标志,有是1,无是0 |
CY |
NC |
- 2. ZF是flag的第6位,零标志位。
它记录相关指令执行后,的结果的值。
结果为0 ,ZF = 1
结果不为0,ZF = 0
- 3. PF是flag的第2位,奇偶标志位。
它记录指令执行后,结果的所有二进制位中1的个数:
为偶数,PF = 1;
为奇数,PF = 0。
- 4. SF是flag的第7位,符号标志位。
它记录指令执行后,结果的正负数情况。
结果为负,SF = 1;
结果为正,SF = 0。
- 5. CF是flag的第0位,进位标志位。
它记录相关指令执行的过程中是否有进位或借位的情况。
有进位或借位,CF=1;
无进位或借位,CF=0;
一般情况下,在进行无符号数运算的时候,它记录了运算结果的最高有效位向更高位的进位值,或从更高位的借位值。
- 6. OF是flag的第11位,溢出标志位。
一般情况下,OF记录了有符号数运算的结果是否发生了溢出。
如果发生溢出,OF=1,
如果没有,OF=0。
如果运算结果超出了机器所能表达的范围,将产生溢出。这里所讲的溢出,只是对有符号数运算而言。
- 7. CF和OF的区别:
CF是对无符号数运算有意义的标志位;
OF是对有符号数运算有意义的标志位。
对于无符号数运算,CPU用CF位来记录是否产生了进位;
对于有符号数运算,CPU 用OF 位来记录是否产生了溢出,当然,还要用SF位来记录结果的符号。
CF 和OF 所表示的进位和溢出,是分别对无符号数和有符号数运算而言的,它们之间没有任何关系。
- 8. adc指令
adc是带进位加法指令,它利用了CF位上记录的进位值。
格式:adc 操作对象1,操作对象2
功能:操作对象1=操作对象1+操作对象2+CF
比如:adc ax,bx,实现的功能是:(ax)=(ax)+(bx)+CF
可以看出,adc指令比add指令多加了一个CF位的值。
adc指令执行后,将对CF进行设置。
在执行adc 指令的时候加上的CF 的值的含义,由adc指令前面的指令决定的,也就是说,关键在于所加上的CF值是被什么指令设置的。
利用adc指令我们可以对任意大的数据进行加法运算,先对低位运算,然后再对高位运算。
- 9. sbb指令
sbb是带错位减法指令,它利用了CF位上记录的借位值。
格式:sbb 操作对象1,操作对象2
功能:操作对象1=操作对象1–操作对象2–CF
比如:sbb ax,bx,实现功能:(ax) = (ax) –(bx) –CF
可以看出,sbb指令比sub指令多减了一个CF位的值。
sbb指令执行后,将对CF进行设置。
利用sbb指令我们可以对任意大的数据进行减法运算,先对低位运算,然后再对高位运算。
显然,如果CF 的值是被sub指令设置的,那么它的含义就是借位值;如果是被add指令设置的,那么它的含义就是进位值。
- 10. cmp指令
cmp 是比较指令,功能相当于减法指令,只是不保存结果。
cmp 指令执行后,将对标志寄存器产生影响。
其他相关指令通过识别这些被影响的标志寄存器位来得知比较结果。
格式:cmp 操作对象1,操作对象2
功能:计算操作对象1–操作对象2 但并不保存结果,仅仅根据计算结果对标志寄存器进行相应的设置。
比如:cmp ax,ax
做(ax)–(ax)的运算,结果为0,但并不在ax中保存,仅影响flag的相关各位。
指令执行后:
ZF=1,
PF=1,
SF=0,
CF=0,
OF=0。
我们通过cmp 指令执行后,相关标志位的值就可以看出比较的结果。
cmp ax,bx
如果(ax)=(bx),则(ax)-(bx)=0,所以:ZF=1
如果(ax)≠(bx),则(ax)-(bx)≠0,所以:ZF=0
如果(ax)<(bx),则(ax)-(bx)将产生借位,所以:ZF=1
如果(ax)≥(bx),则(ax)-(bx)将不必借位,所以:ZF=0
如果(ax)>(bx),则(ax)-(bx)既不必借位,结果又不为0,所以:CF=0并且ZF=0
如果(ax)≤(bx),则(ax)-(bx)既可能借位,结果可能为0,所以:CF=1或者ZF=1
反过来推理上面的例子cmp ax,ax
指令cmp ax,bx 的逻辑含意是比较ax和bx中的值,如果执行后:
ZF=1,说明:(ax)=(bx)
ZF=0,说明:(ax) ≠ (bx)
CF=1,说明:(ax) <(bx)
CF=0,说明:(ax) ≥ (bx)
CF=0并且ZF=0,说明:(ax) >(bx)
CF=1或者ZF=1,说明:(ax) ≤ (bx)
从上面的我们也可以看出,CPU利用cmp指令可以对无符号数进行比较,也可以对有符号数进行比较,比如进位、借位、溢出等。所以cmp 指令所作的比较结果,不是仅仅靠SF就能记录的,因为它只能记录实际结果的正负,我们应该在考察SF(得知实际结果的正负)的同时考察OF(得知有没有溢出),就可以得知逻辑上真正结果的正负,同时就可以知道比较的结果。
我们以cmp ah,bh为例,总结CPU执行cmp指令后,SF和OF的值是如何来说明比较的结果的。
(1)如果SF=1,而OF=0
因OF=0,说明没有溢出,逻辑上真正结果的正负=实际结果的正负;
因SF=1,实际结果为负,所以逻辑上真正的结果为负。通过:SF=1,OF = 0,说明了(ah)<(bh)。
(2)如果SF=1,而OF=1
因OF=1 ,说明有溢出,逻辑上真正结果的正负≠实际结果的正负;
因SF=1 ,实际结果为负,而又有溢出且结果非0,这说明是由于溢出导致了实际结果为负,
简单分析一下,就可以看出,如果因为溢出导致了实际结果为负,那么逻辑上真正的结果必然为正。通过:SF=1,OF = 1 ,说明了(ah)>(bh)。
(3)如果SF=0,而OF=1
因OF=1 ,说明有溢出,逻辑上真正结果的正负≠实际结果的正负;
因SF=0,实际结果非负,而又有溢出且结果非0,这说明是由于溢出导致了实际结果非负,
简单分析一下,就可以看出,如果因为溢出导致了实际结果为正,那么逻辑上真正的结果必然为负。通过:SF=0,OF = 1 ,说明了(ah)<(bh)。
(4)如果SF=0,而OF=0
因OF=0,说明没有溢出,逻辑上真正结果的正负=实际结果的正负;
因SF=0,实际结果非负,所以逻辑上真正的结果必然非负。通过:SF=0,OF = 0,说明了(ah)≥(bh)。
- 11. 条件转移指令
“转移”指的是它能够修改IP,而“条件”指的是它可以根据某种条件,决定是否修改IP。
所有条件转移指令的转移位移都是:[-128,127]。
比如:jcxz就是一个条件转移指令,它可以检测cx 中的数值,如果(cx)=0,就修改IP,否则什么也不做。
除了jcxz 之外,CPU还提供了其他条件转移指令,大多数条件转移指令都检测标志寄存器都是根据cmp指令影响的相关标志位,根据检测的结果来决定是否修改IP。条件转移指令通常都和cmp相配合使用,就好像call 和ret 指令通常相配合使用一样。
cmp 指令可以进行无符号数比较和有符号数比较,所以根据cmp 指令的比较结果进行转移的指令也分为两种,即:
(1)根据无符号数的比较结果进行转移的条件转移指令,它们检测ZF、CF的值;
(2)和根据有符号数的比较结果进行转移的条件转移指令,它们检测SF、OF和ZF的值。
无符号转移的条件转移指令
| 指令 |
含义 |
检测的标准位 |
| je |
等于则转移 |
ZF=1 |
| jne |
不等于则转移 |
ZF=0 |
| jb |
低于则转移 |
CF=1 |
| jnb |
不低于则转移 |
CF=0 |
| ja |
高于则转移 |
ZF=0,CF=0 |
| jna |
不高于则转移 |
ZF=1或CF=1 |
这些指令比较常用,它们都很好记忆,它们的每一个字母的含义如下:
j:表示jump
e:表示equal;
ne:表示not equal;
b:表示below;
nb:表示not below;
a:表示above;
na:表示not above。
通过上面说明条件跳转指令是根据判断不同的标志位进行跳转的,这也说明跳转前是否使用cmp指令在于我们自己的安排,不管前面是什么语句,只要影响力对应的标志位,那么条件跳转就会发生转移。
- 12. DF是flag的第10位,方向标志位。
在串处理指令中,控制每次操作后si,di的增减。
DF = 0:每次操作后si,di递增;
DF = 1:每次操作后si,di递减。
格式1:rep movsb
功能:(以字节为单位传送)
(1) ((es)×16 + (di)) = ((ds) ×16 + (si))
(2) 如果DF = 0则:(si) = (si) + 1 , (di) = (di) + 1
如果DF = 0则:(si) = (si) -1 , (di) = (di) -1
我们用汇编语法描述movsb的功能,8086CPU并不支持这样的指令,这里只是个描述。如下:
mov es:[di],byte ptr ds:[si];
如果DF=0:
inc si
inc di
如果DF=1:
dec si
dec di
可以看出,movsb 的功能是将ds:si 指向的内存单元中的字节送入es:di中,然后根据标志寄存器DF位的值,将si和di递增或递减。
格式2:rep movsw
功能:(以字为单位传送)
将ds:si指向的内存字单元中word送入es:di中,然后根据标志寄存器DF位的值,将si和di递增2或递减2。
以用汇编语法描述movsw的功能如下:
mov es:[di],word ptr ds:[si]; 8086 CPU并不支持这样的指令,这里只是个描述。
如果DF=0:
add si,2
add di,2
如果DF=1:
sub si,2
sub di,2
- 13. rep指令和movsb指令和movsw指令
rep指令是根据cx循环的指令,movsb和movsw进行的是串传送操作中的一个步骤,一般来说,movsb 和movsw 都和rep配合使用。
格式如下:
rep movsb
用汇编语法来描述rep movsb的功能就是:
s : movsb loop s
rep movsw
用汇编语法来描述rep movsw的功能就是:s : movsw loop s
可见,rep的作用是根据cx的值,重复执行后面的串传送指令。
由于每执行一次movsb指令si和di都会递增或递减指向后一个单元或前个单元,则rep movsb就可以循环实现(cx)个字符的传送。
由于flag的DF位决定着串传送指令执行后,si和di改变的方向,所以CPU应该提供相应的指令来对DF位进行设置,从而使程序员能够决定传送的方向。8086CPU提供下而两条指令对DF位进行设置:
cld指令:将标志寄存器的DF位置0
std指令:将标志寄存器的DF位置1
指令助记:cl可看作clear—清除;st表示set—设置,d表示DF标志位
第十二章 内中断
- 1. 什么是中断
中断的意思是指,CPU不再接着(刚执行完的指令)向下执行,而是转去处理这个特殊信息。
根据中断的类型可分为:
内中断:中断信息来自CPU 的内部,当CPU 的内部有需要处理的事情发生的时候,将产生需要马上处理的中断信息,引发中断过程。
外中断:中断信息来自CPU 的外部,当CPU 的内部有需要处理的事情发生的时候,将产生需要马上处理的中断信息,引发中断过程。
对于8086CPU,当内部有下面情况发生的时候,将产生中断信息:
1、除法错误,比如:除法溢出;à对应CPU的0号中断
2、单步执行; à对应CPU的1号中断
3、执行int0指令; à对应CPU的4号中断
4、执行int 指令。 à把指令提供给CPU
说明:int 指令的格式为:int n,指令中的n为字节型立即数,是提供给CPU的中断类型码。
- 2. 中断向量表
CPU用8 位的中断类型码通过中断向量表找到相应的中断处理程序的入口地址。
中断向量表在内存中保存,其中存放着256个中断源所对应的中断处理程序的入口,对于8086PC机,中断向量表指定放在内存地址0处。从内存0000:0000到0000:03FF的1024个单元中存放着中断向量表。但是一般0000:0200到0000:02FF这里的256 个字节的空间没有使用。所以,我们使用这段空间是安全的。
- 3. 中断过程
用中断类型码找到中断向量,并用它设置CS和IP,这个工作是由CPU的硬件自动完成的。完成这个工作的过程被称为中断过程。
8086CPU的中断过程:
(1)(从中断信息中)取得中断类型码;
(2)标志寄存器的值入栈(因为在中断过程中要改变标志寄存器的值,所以先将其保存在栈中。);
(3)设置标志寄存器的第8位TF 和第9位IF的值为0;(这一步的目的后面的单步中断将介绍)
(4)CS的内容入栈;
(5)IP的内容入栈;
(6)从内存地址为中断类型码*4 和中断类型码*4+2 的两个字单元中读取中断处理程序的入口地址设置IP和CS。
我们用汇编的形式描述中断过程,如下:
(1)取得中断类型码N;
(2)pushf
(3)TF = 0,IF = 0
(4)push CS
(5)push IP
(6)(IP) = (N*4),(CS) = (N*4+2)
在最后一步完成后,CPU 开始执行由程序员编写的中断处理程序。
- 4. 中断处理程序
中断处理程序的编写方法和子程序的比较相似,下面是常规的步骤:
(1)保存用到的寄存器。
(2)处理中断。
(3)恢复用到的寄存器。
(4)用iret 指令返回。
- 5. iret指令
iret指令的功能是恢复中断指令保存的标准寄存器、CS、IP的状态,iret通常和硬件自动完成的中断过程配合使用。
用汇编语法描述为:
pop IP
pop CS
popf
可以看出,在中断过程中,寄存器入栈的顺序是:标志寄存器、CS、IP ,而iret的出栈顺序是IP、CS、标志寄存器,刚好和其对应,实现了用执行中断处理程序前的CPU现场恢复标志寄存器、CS、IP的工作。
- 6. 编程处理0号中断
分析(1):
当发生除法溢出的时候,产生0号中断信息,从而引发中断过程。此时,CPU将进行以下工作:
①取得中断类型码0;
②标志寄存器入栈,TF、IF设置为0;
③CS、IP入栈;
④(IP) = (0*4),(CS) = (0*4+2)
分析(2):
可见,当中断0 发生时,CPU将转去执行中断处理程序。只要按如下步骤编写中断处理程序,当中断0发生时,即可显示“overflow!”。
①相关处理。
②向显示缓冲区送字符串“overflow!”。
③返回DOS
我们将这段程序称为do0。
分析(3):
现在的问题是:do0 应放在内存中。因为除法溢出随时可能发生,CPU随时都可能将CS:IP指向do0的入口,执行程序。
分析(4):
根据前面我们可以直接自己写个子程序来处理中断,此时我们要做以下几件事情:
①编写可以处理0号中断的处理程序:do0;
②将do0送入内存0000:0200处;
③将do0的入口地址0000:0200存储在中断向量表0号表项中。
说明:中断处理的子程序所用到的数据等全部信息要同时保存到内存0000:0200处;
- 7. 单步中断
基本上,CPU在执行完一条指令之后,如果检测到标志寄存器的TF位为1,则产生单步中断,引发中断过程。单步中断的中断类型码为1,则它所引发的中断过程如下:
(1)取得中断类型码1;
(2)标志寄存器入栈,TF、IF设置为0;
(3)CS、IP入栈;
(4)(IP)=(1*4),(CS)=(1*4+2)。
如上所述,如果TF=1,则执行一条指令后,CPU就要转去执行1号中断处理程序。
我们来简要地考虑一下Debug是如何利用CPU所提供的单步中断的功能的。
①Debug提供了单步中断的中断处理程序。中断程序功能:显示所有寄存器中的内容后等待输入命令。
②在使用T 命令执行指令时,Debug 将TF设置为1,使得CPU在工作于单步中断方式下,则在CPU执行完这条指令后就引发单步中断,执行单步中断的中断处理程序。
说明:在进入中断处理程序之前,设置TF=0。这就是为什么在中断过程中有TF=0这个步骤。
我们再来看一下一般通用的中断过程:
(1)取得中断类型码N;
(2)标志寄存器入栈,TF=0、IF=0;
(3)CS、IP入栈;
(4)(IP) = (N*4),(CS) = (N*4+2)
- 8. TF是flag的第8位,单步中断标志位。
它记录相关指令执行的过程中是否发生单步中断,单步中断的中断类型码为1。
单步中断,TF=1;
无单步中断,TF=0;
一般情况下,CPU在执行完一条指令之后,如果检测到标志寄存器的TF位为1,则产生单步中断,引发中断过程,转入中断处理程序,在进入中断处理程序之前,设置TF=0。
- 9. 中断的特殊情况
一般情况下,CPU在执行完当前指令后,如果检测到中断信息,就响应中断,引发中断过程。可是,在有些情况下,CPU 在执行完当前指令后,即便是发生中断,也不会响应。
例如:在执行完向ss寄存器传送数据的指令后,即便是发生中断,CPU 也不会响应。这样做的主要原因是,ss:sp联合指向栈顶,而对它们的设置应该连续完成。如果在执行完设置ss的指令后,CPU响应中断,引发中断过程,在中断处理程序中还要在栈中压入标志寄存器、CS和IP的值。而中断返回后ss:sp指向的不是正确的栈顶,将引起错误。所以CPU在执行完设置ss的指令后,不响应中断。这给连续设置ss和sp,指向正确的栈顶提供了一个时机。
例如,我们要将栈顶设为1000:0,程序代码如下:
mov ax,1000h
mov ss,ax
mov bx,1234h
mov sp,0
我们使用debug单步执行,发现mov bx,1234h是没有暂停的,而是直接暂停在mov sp,0这里,充分说明设置ss的指令后不会暂停,会再执行一条语句后暂停,也就是执行设置ss指令会连续执行两条命令后才暂停。
我们应该利用这个特性,将设置ss和sp的指令连续存放,使得设置ss的指令后紧接着设置sp的指令执行,而在此之间,CPU不会引发中断过程,其中也包括单步中断,所以Debug设置的单步中断程序(用来显示寄存器状态和等待输入命令的中断处理程序)根本没有得到执行,所以我们看不到预期的结果。
第十三章 int指令
- 1. int指令
CPU 执行int n指令,相当于引发一个n号中断的中断过程,程序转而执行中断处理程序。
int格式:int n,n为中断类型码。它的功能是引发中断过程。
int n指令执行过程如下:
(1)取中断类型码n;
(2)标志寄存器入栈,IF = 0,TF = 0;
(3)CS、IP入栈;
(4)(IP) = (n*4),(CS) = (n*4+2)。
从此处转去执行n号中断的中断处理程序。
可以在程序中使用int指令调用任何一个中断的中断处理程序。例如在程序中调用0号中断:int 0
- 2. BIOS和DOS中断例程
先看一下int 10h中断例程的设置光标位置功能。int 10h中断例程是BIOS提供的中断例程,其中包含了多个和屏幕输出相关的子程序。一般来说,一个供程序员调用的中断例程中往往包括多个子程序,中断例程内部用传递进来的参数来决定执行哪个子程序。BIOS 和DOS 提供的中断例程,都用ah来传递内部子程序的编号。
mov ah,2 ; 表示调用第10h号中断例程的2号子程序
mov bh,0 ; 表示设置光标到显存的第0页
mov dh,5 ;表示行号
mov dl,12 ;表示列号
int 10h
(ah)=2表示调用第10h号中断例程的2号子程序,功能为设置光标位置,可以提供光标所在的行号(80*25字符模式下:0~24)、列号(80*25字符模式下:0~79),和页号作为参数。
(bh)=0,(dh)=5,(dl)=12,设置光标到第0页,第5行,第12列。
bh中页号的含义:
内存地址空间中,B8000h~BFFFFh共32K的空间,为80*25 彩色字符模式的显示缓冲区。一屏的内容在显示缓冲区中共占4000个字节。显示缓冲区分为8页,每页4K(≈4000),显示器可以显示任意一页的内容。一般情况下,显示第0 页的内容。也就是说,通常情况下,B8000~B8F9F中的4000个字节的内容将出现在显示器上。
再看一下int 10h中断例程的在光标位置显示字符功能。
mov ah,9;设置光标
mov al,‟a‟;将要显示的字符
mov bl,7;颜色属性
mov bh,0;第0页
mov cx,3;字符重复个数
int 10h
(ah)=9 表示调用第10h号中断例程的9号子程序;
功能:在光标位置显示字符,可以提供要显示的字符、颜色属性、页号、字符重复个数作为参数。
(bh)中的颜色属性格式如下:
| 7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
| BL |
R |
G |
B |
I |
R |
G |
B |
| 闪烁 |
背景色 |
高亮 |
前景色 |
||||
可以看出,和显存中的属性字节的格式相同。
int 21h 中断例程是DOS提供的中断例程,其中包含了DOS提供给程序员在编程时调用的子程序。我们从前一直使用的是int 21中断例程的4ch号功能,即程序返回功能,如下:
mov ah,4ch ;程序返回
mov al,0 ;返回值
int 21h
(ah)=4ch表示调用第21h号中断例程的4ch号子程序,功能为程序返回,可以提供返回值作为参数。
我们前面使用这个功能的时候经常写作:
mov ax,4c00h
int 21h
我们看一下int 21h中断例程的在光标位置显示字符串的功能:
ds:dx ;指向字符串;要显示的字符串需用“$”作为结束符
mov ah ,9 ;表示9号子程序,表示在光标位置显示字符串
int 21h
(ah)=9表示调用第21h号中断例程的9号子程序,功能为在光标位置显示字符串,可以提供要显示字符串的地址作为ds:dx参数,并且以$符号为结束符号。
例如在屏幕的5列12行显示字符串“Welcome to masm!”,直到遇见“$”(“$”本身并不显示,只起到边界的作用)。如果字符串比较长,遇到行尾,程序会自动转到下一行开头处继续显示;如果到了最后一行,还能自动上卷一行。DOS为程序员提供了许多可以调用的子程序,都包含在int 21h 中断例程中。我们这里只对原理进行了讲解,对于DOS提供的所有可调用子程序的情况,读者可以参考相关的书籍。
- 3. LEA指令
lea(Load Effective Address:载入有效地址),lea指令的功能是将源操作数、即存储单元的有效地址(偏移地址)传送到目的操作数,将一个近地址指针写入到指定的寄存器,内存单元可以使用多种寻址方式。
格式:LEA reg16,mem16
lea还可以作简单的算术计算,特别是有了32位指令的增强寻址方式,更是“如虎添翼”, 比如你要算EAX*4+EBX+3,结果放入EDX,怎么办?
mov edx, eax
shl edx, 2
add edx, ebx
add edx, 3
现在用lea一条指令搞定: lea edx, [ebx+eax*4+3]
LEA与MOV传送指令的区别:MOV传送的是地址所指的内容,而LEA只是地址。
第十四章 端口
- 1. CPU可直接读写的数据
CPU可以直接读写3 个地方的数据:
(1)CPU 内部的寄存器;
(2)内存单元;
(3)端口。
端口的读写指令只有两条:in和out,
分别用于从端口读取数据和往端口写入数据。
- 2. 访问端口的过程
in al,60h;从60h号端口读入一个字节,执行时与总线相关的操作过程:
①CPU通过地址线将地址信息60h发出;
②CPU通过控制线发出端口读命令,选中端口所在的芯片,并通知它,将要从中读取数据;
③端口所在的芯片将60h端口中的数据通过数据线送入CPU。
注意:在in和out 指令中,只能使用ax 或al 来存放从端口中读入的数据或要发送到端口中的数据。访问8 位端口时用al ,访问16 位端口时用ax 。in或out会同时执行两条语句,也就是紧跟在in或out后面的语句也会执行,无法单步跟踪。
(1)对0~255以内的端口进行读写:
in al,20h;从20h端口读入一个字节
out 20h,al ;往20h端口写入一个字节
(2)对256~65535的端口进行读写时,端口号放在dx中:
mov dx,3f8h ;将端口号3f8送入dx
in al,dx ;从3f8h端口读入一个字节
out dx,al ;向3f8h端口写入一个字节
- 3. CMOS RAM芯片
PC机中有一个CMOS RAM芯片,其有如下特征:
(1)包含一个实时钟和一个有128个存储单元的RAM存储器。(早期的计算机为64个字节)
(2)该芯片靠电池供电。所以,关机后其内部的实时钟仍可正常工作,RAM 中的信息不丢失。
(3)128 个字节的RAM 中,内部实时钟占用0~0dh单元来保存时间信息,其余大部分分单元用于保存系统配置信息,供系统启动时BIOS程序读取。BIOS也提供了相关的程序,使我们可以在开机的时候配置CMOS RAM 中的系统信息。
(4)该芯片内部有两个端口,端口地址为70h和71h。CPU 通过这两个端口读写CMOS RAM。
(5)70h为地址端口,存放要访问的CMOS RAM单元的地址;71h为数据端口,存放从选定的CMOS RAM 单元中读取的数据,或要写入到其中的数据。
可见,CPU对CMOS RAM的读写分两步进行。比如:读CMOS RAM的2号单元:
1、将2送入端口70h
2、从71h读出2号单元的内容
- 4. shl和shr指令
shl和shr 是逻辑移位指令。
shl逻辑左移指令,功能为:
(1)将一个寄存器或内存单元中的数据向左移位;
(2)将最后移出的一位写入CF中;
(3)最低位用0补充。
可以看出,将X逻辑左移一位,相当于执行X=X*2。
shr逻辑右移指令,它和shl所进行的操作刚好相反:
(1)将一个寄存器或内存单元中的数据向右移位;
(2)将最后移出的一位写入CF中;
(3)最高位用0补充。
可以看出,将X逻辑右移一位,相当于执行X=X/2
如果移动位数大于1时,必须将移动位数放在cl中。
- 5. CMOS RAM中存储的时间信息
在CMOS RAM中,存放着当前时间:
秒:00H
分:02H
时:04H
日:07H
月:08H
年:09H
这6个信息的长度长度都为1个字节。
这些数据以BCD码的方式存放:
| 数码 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
| BCD码 |
0000 |
0001 |
0010 |
0011 |
0100 |
0101 |
0110 |
0111 |
1000 |
1001 |
比如:数值26,用BCD码表示为:0010 0110。可见,一个字节可表示两个BCD码。则CMOS RAM存储时间信息的单元中,存储了用两个BCD码表示的两位十进制数,高4 位的BCD码表示十位,低4 位的BCD 码表示个位。
比如:00010100b表示14。
第十五章 外中断
- 1. 外中断
在PC 系统中,由外部硬件等引发的中断称为外中断,外中断源一共有两类:
1、可屏蔽中断
2、不可屏蔽中断
可屏蔽中断:是CPU 可以不响应的外中断。
CPU 是否响应可屏蔽中断,要看标志寄存器的IF 位的设置。
当CPU 检测到可屏蔽中断信息时:
如果IF=1,则CPU 在执行完当前指令后响应中断,引发中断过程;
如果IF=0,则不响应可屏蔽中断。
回忆一下内中断所引发的中断过程:
(1)取中断类型码n;
(2)标志寄存器入栈,设置IF=0,TF=0;
(3)CS 、IP 入栈;
(4)(IP)=(n*4),(CS)=(n*4+2)
由此转去执行中断处理程序。
- 2. 可屏蔽中断和内中断的区别
可屏蔽中断所引发的中断过程,除在第1步的实现上有所不同外,基本上和内中断的中断过程相同。因为可屏蔽中断信息来自于CPU外部,中断类型码是通过数据总线送入CPU 的;而内中断的中断类型码是在CPU内部产生的。
- 3. IF是flag的第9位,是中断标志位。
它记录相关指令执行的过程中是否响应中断,中断类型码为1。
响应中断,TF=1;跳转到中断处理程序
不响应中断,TF=0;屏蔽中断,不转去处理中断程序
一般情况下,CPU在执行完一条指令之后,如果检测到标志寄存器的IF位为1,则产生中断,引发中断过程,转入中断处理程序。
我们可以解释一般中断过程中将IF置为0的原因了。将IF置0的原因就是,在进入中断处理程序后,禁止其他的可屏蔽中断。当然,如果在中断处理程序中还需要处理其他的中断,如可屏蔽中断,可以用指令将IF 置1 ,这样在处理中断断过程中同样也可以被其他中断程序中断,转去执行中断程序。
8086CPU 提供的设置IF的指令如下:
sti,用于设置IF=1;
cli,用于设置IF=0。
- 4. 不可屏蔽中断
不可屏蔽中断是CPU 必须响应的外中断。当CPU 检测到不可屏蔽中断信息时,则在执行完当前指令后,立即响应,引发中断过程。对于8086CPU 不可屏蔽中断的中断类型码固定为2。所以中断过程中,不需要取中断类型码。
不可屏蔽中断的中断过程:
1、标志寄存器入栈,IF=0,TF=0;
2、CS、IP入栈;
3、(IP)=(8),(CS)=(0AH)。
几乎所有由外设引发的外中断,都是可屏蔽中断。当外设有需要处理的事件(比如说键盘输入)发生时,相关芯片向CPU 发出可屏蔽中断信息。
不可屏蔽中断是在系统中有必须处理的紧急情况发生时用来通知CPU 的中断信息。在我们的课程中,主要讨论可屏蔽中断。
- 5. int 9中断例程--键盘输入的处理过程讲解
例如键盘输入的处理过程,并以此来体会一下PC 机处理外设输入的基本方法。
1、键盘输入
2、引发9号中断
3、执行int 9中断例程
键盘上的每一个键相当于一个开关,键盘中有一个芯片对键盘上的每一个键的开关状态进行扫描。
按下一个键时,开关接通,该芯片就产生一个扫描码,扫描码说明了按下的键在键盘上的位置。扫描码被送入主板上的相关接口芯片的寄存器中,该寄存器的端口地址为60H 。
松开按下的键时,也产生一个扫描码,扫描码说明了松开的键在键盘上的位置。松开按键时产生的扫描码也被送入60H 端口中。
一般将按下一个键时产生的扫描码称为通码,松开一个键产生的扫描码称为断码。扫描码长度为一个字节,通码的第7 位为0 ,断码的第7位为1,即:断码=通码+80H
比如:g键的通码为22H,断码为a2H。
部分键盘上部分键的扫描码:
| 键 |
扫描码 |
键 |
扫描码 |
键 |
扫描码 |
键 |
扫描码 |
| Esc |
01 |
[ |
1A |
\ |
2B |
NumLock |
45 |
| 1~9 |
02~0A |
] |
1B |
Z |
2C |
ScrollLock |
46 |
| 0 |
0B |
Enter |
1C |
X |
2D |
Home |
47 |
| - |
0C |
Ctrl |
1D |
C |
2E |
↑ |
48 |
| = |
0D |
A |
1E |
V |
2F |
PgUp |
49 |
| Backspace |
0E |
S |
1F |
B |
30 |
- |
4A |
| Tab |
0F |
D |
20 |
N |
31 |
← |
4B |
| Q |
10 |
F |
21 |
M |
32 |
→ |
4D |
| W |
11 |
G |
22 |
, |
33 |
+ |
4E |
| Esc |
12 |
H |
23 |
. |
34 |
End |
4F |
| R |
13 |
J |
24 |
/ |
35 |
↓ |
50 |
| Tab |
14 |
K |
25 |
Shift(右) |
36 |
PgDn |
51 |
| Y |
15 |
L |
26 |
Prtsc |
37 |
Ins |
52 |
| U |
16 |
; |
27 |
Alt |
38 |
Del |
53 |
| I |
17 |
‘ |
28 |
Space |
39 |
|
|
| O |
18 |
` |
29 |
CapsLock |
3A |
|
|
| P |
19 |
Shift(左) |
2A |
F1~F10 |
3B~44 |
|
|
键盘的输入到达60H 端口时,相关的芯片就会向CPU 发出中断类型码为9 的可屏蔽中断信息。
CPU检测到该中断信息后,如果IF=1,则响应中断,引发中断过程,转去执行int 9中断例程。
BIOS 提供了int 9中断例程,用来进行基木的键盘输入处理,主要的工作如下:
(1)读出60H 端口中的扫描码;
(2)如果是字符键的扫描码,将该扫描码和它所对应的字符码(即ASCII码)送入内存中的BIOS 键盘缓冲区;如果是控制键(比如Ctrl )和切换键(比如CapsLock)的扫描码,则将其转变为状态字节(用二进制位记录控制键和切换键状态的字节)写入内存中存储状态字节的单元。
(3)对键盘系统进行相关的控制,比如说,向相关芯片发出应答信息。
BIOS键盘缓冲区是系统启动后,BIOS用于存放int 9 中断例程所接收的键盘输入的内存区。该内存区可以存储15 个键盘输入,因为int 9 中断例程除了接收扫描码外,还要产生和扫描码对应的字符码,所以在BIOS键盘缓冲区中,一个键盘输入用一个字单元存放,高位字节存放扫描码,低位字节存放字符码。在内存的0040:17 字节单元中存储键盘状态字节,该字节记录了控制键和切换键的状态。键盘状态字节各位记录的信息如下:
0:右shift状态,置1表示按下右shift键;
1:左shift状态,置1表示按下左shift键;
2:Ctrl状态,置1表示按下Ctrl键;
3:Alt状态,置1表示按下Alt键;
4:ScrollLock状态,置1表示按下ScrollLock键,Scroll指示灯亮;
5:NumLock状态,置1表示小键盘输入的是数字;
6:CapsLock状态,置1表示输入大写字母;
7:Insert状态,置1表示处于删除状态;
从上面的内容中,我们可以看出键盘输入的处理过程:
(1)键盘产生扫描码;
(2)扫描码送入60h 端口;
(3)引发9 号中断;
(4)CPU执行int 9中断例程处理键盘输入。
上面的过程中,第(1)、(2)、(3)步都是由硬件系统完成的。我们能够改变的只有int 9中断处理程序。我们可以重新编写int 9中断例程,按照自己的意图来处理键盘的输入。
例如:
程序功能:编写程序在屏幕中间显示“a”~“z”,并可以让人看清,这个任务比较好实现。
(1)在b800:[ 160*12+40*2]处存入a的ASCII码、(2)在循环中使用一个100000000000H次的循环空转达到延迟效果、(3)按键盘引发int9中断改变颜色
那么如何实现,按下Esc 键后,改变显示的颜色呢?
键盘输入到达60h 端口后,就会引发9号中断,CPU 则转去执行int 9中断例程。
我们可以编写int 9中断例程,功能如下:
(1)从60h 端口读出键盘的输入;
(2)调用BIOS 的int 9 中断例程,处理其他硬件细节;
(3)判断是否为Esc的扫描码,如果是,改变显示的颜色后返回;如果不是则直接返回。
我们对这些功能的实现一一进行分析
1、从端口60h读出键盘的输入使用:in al,60h
2、调用BIOS的int 9中断例程
有一点要注意的是,我们写的中断处理程序要成为新的int 9中断例程,主程序必须要将中断向量表中的int 9中断例程的入口地址改为我们写的中断处理程序的入口地址。那么在新的中断处理程序中调用原来的int 9中断例程时,中断向量表中的int 9中断例程的入口地址却不是原来的int 9 中断例程的地址。所以我们不能使用int 指令直接调用。要在我们写的新中断例程中调用原来的中断例程,就必须在将中断向量表中的中断例程的入口地址改为新地址之前,将原来的入口地址保存起来。这样,在需要调用的时候,我们才能找到原来的中断例程的入口。对于我们现在的问题,假设我们将原来int 9中断例程的偏移地址和段地址保存在ds:[0]和ds:[2]单元中。那么我们在需要调用原来的int 9中断例程时候,就可以在ds:[0]、ds:[2] 单元中找到它的入口地址。那么,有了入口地址后,我们如何进行调用呢?
当然不能使用指令int 9来调用。我们可以用别的指令来对int指令进行一些模拟,从而实现对中断例程的调用。我们来看,int 指令在执行的时候,CPU 进行下面的工作:
(1)取中断类型码n;
(2)标志寄存器入栈;
(3)IF=0,TF=0;
(4)CS 、IP 入栈;
(5)设置(IP)=(n*4),(CS=(n*4+2)。
取中断类型码是为了定位中断例程的入口地址,在我们的问题中,中断例程的入口地址已经知道。所以,我们用别的指令模拟int指令时候,不需要做第(1)步。在假设要调用的中断例程的入口地址在ds:0和ds:2单元中的前提下,我们将int 过程用下面几步模拟:
(1)标志寄存器入栈;
(2)IF=0,TF=0;
(3)CS、IP入栈;
(4)(IP)=((ds)*16+0),(CS)=((ds)*16+2)。
可以注意到第(3)、(4)步和call dword ptr ds:[0]的功能一样。call dword ptr ds:[0]的功能也是:(1)CS 、IP 入栈;(2)(IP)=((ds)*16+0),(CS)=((ds)*16+2)。
说明:如果还有疑问,复习10.6节的内容。
所以int 过程的模拟过程变为:
(1)标志寄存器入栈;
(2)IF=0,TF=0;
(3)call dword ptr ds:[0]
对于(1),可用pushf来实现。
对于(2),可用and和popf实现,如下面的指令实现。
实现IF=0,TF=0步骤:
pushf
pop ax
and ah,11111100b ;IF和OF为标志寄存器的第9位和第8位
push ax
popf
这样,模拟int指令的调用功能,调用入口地址在ds:0、ds:2中的中断例程的程序如下
pushf ;标志寄存器入栈
pushf;实现IF=0,TF=0的功能
pop ax
and ah,11111100b ;IF和OF为标志寄存器的第9位和第8位
push ax
popf ;IF=0、TF=0
call dword ptr ds:[0];call功能: ①CS、IP入栈,②;(IP)=((ds)*16+0),③;(CS)=((ds)*16+2)
3、如果是Esc键的扫描码,改变显示的颜色后返回,如何改变显示的颜色?
显示的位置是屏幕的中问,即第12行40列,显存中的偏移地址为:160*12+40* 2。所以字符的ASCII码要送入b800:160*12+40*2处。而b800:160*12+40*2+1处是字符的属性,我们只要改变此处的数据就可以改变在b800:160*12+40*2处显示的字符的颜色了。
该程序的最后一个问题是,要在程序返回前,将中断向量表中的ini 9中断例程的入口地址恢复为原来的地址。否则程序返回后,别的程序将无法使用键盘。
注意,本章中所有关于键盘的程序,因要直接访问真实的硬件,则必须在DOS实模式下运行。在Windows 2000 的DOS 方式下运行,会出现一些和硬件工作原理不符合的现象。
程序完整代码可参考博客:http://www.cnblogs.com/mq0036/p/5150801.html
开发int9中断例程架构:
①在主程序中把原来的int9的原始程序入口保存到data段中,并把自己写的int9中断例程入口地址替换到中断向量表的9号中断地址,对应的是IP是0: [9*4]和CS是0[9*4+2]
②等待外部中断自动调用int9
③程序运行完后还原int9原来的中断例程入口
在int9中断例程内部结构
1.保存用到的通用寄存器
2.接收60h端口的数据
3.修改IF和TF的值为0
4.处理数据
5.使用call模拟调用int9的系统中断例程
6.还原通用寄存器
说明:由于中断例程使用的是iret返回,而iret的过程是①从栈中还原IP和CS,②从栈中还原寄存器状态;这里使用了call的远跳转(地址在data段中),而用call过程是先把CS和IP保存进栈,跳转到指定地址执行完再通过retf返回,调用完成后再从栈中还原IP和CS;而这里我们调用的是中断例程,是用iret返回的,retf和iret返回的IP和CS顺序相同,而iret比retf多一步还原寄存器状态,所以我们要构造供iret的返回的栈数据:就是在call前先保存寄存器状态,然后就可以使用iret的形式还原程序的IP,CS,标志寄存器。我们只要在自己编写的中断例程中处理完自己的数据后再调用BIOS 的int 9中断例程就可以了。
第十六章 直接定址表
- 1. 描述了单元长度的标号
我们一直使用标号在我们的代码段中,例如标记循环或子程序等,例如:
S0:
………..
Loop s0
我们还可以使用一种标号,这种标号不但表示内存单元的地址,还表示了内存单元的长度,即表示在此标号处的单元,是一个字节单元,还是字单元,还是双字单元。
在段中使用的标号a、b后面没有“:”,它们是同时描述内存地址和单元长度的标号。
对于下面的程序片段,在code中定义的a db 1,2,3,4,5,6,7,8 :
assume cs:code
code segment
a db 1,2,3,4,5,6,7,8
b dw 0
start :
mov cx,8
……
指令:mov al,a [si] 相当于:mov al,cs:0[si]
指令:mov al,a[3] 相当于:mov al,cs:0[3]
指令:mov al,a[bx+si+3] 相当于:mov al,cs:0[bx+si+3]
注意,如果想在代码段中,直接用数据标号访问数据,则需要用伪指令assume 将标号所在的段和一个段寄存器联系起来。否则编译器在编译的时候,无法确定标号的段地址在哪一个寄存器中。当然,这种联系是编译器需要的,但绝对不是说,我们因为编译器的工作需要,用assume 指令将段寄存器和某个段相联系,段寄存器中就会真的存放该段的地址。我们在程序中还要使用指令对段寄存器进行设置。因为这些实际编译出的指令,都默认所访问单元的段地址在ds中,而实际要访问的段为data,所以,若要访问正确,在这些指令执行前,ds 中必须为data 段的段地址。
我们将这种标号称为数据标号。
1)它标记了存储数据的单元的地址和长度。
2)它不同于仅仅表示地址的地址标号。
我们可以将标号当作数据来定义,此时,编译器将标号所表示的地址当作数据的值。
比如:
data segment
a db 1,2,3,4,5,6,7,8
b dw 0
c dw a,b
data ends
数据标号c处存储的两个字型数据为标号a、b 的偏移地址。
c dw a,b 相当于:c dw offset a, offset b
再比如:
data segment
a db 1,2,3,4,5,6,7,8
b dw 0
c dd a,b
data ends
数据标号c处存储的两个双字型数据为标号a的偏移地址和段地址、标号b 的偏移地址和段地址。
c dd a,b 相当于: c dw offset a, seg a, offset b, seg b
- 2. seg操作符
seg操作符功能:取得某一标号的段地址。
- 3. 直接定址表
我们将通过给出的数据进行计算或比较而得到结果的问题,转化为用给出的数据作为查表的依据,通过查表得到结果的问题。
例如:根据字节单元的值,输出16进制的字符
我们知道4位二进制可以用一位十六进制表示,其对应关系如下:
| 0000 |
0001 |
0010 |
0011 |
0100 |
0101 |
0110 |
0111 |
1000 |
1001 |
1010 |
1011 |
1100 |
1101 |
1110 |
1111 |
| 0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
A |
B |
C |
D |
E |
F |
使用我们在data段中定义table db ‘0123456789ABCDEF’,只要根据对应的数值查找table中对应的偏移就可以找到对应的字符的数据。具体的查表方法,是用查表的依据数据,直接计算出所要查找的元素在表中的位置。像这种可以通过依据数据,直接计算出所要找的元素的位置的表,我们称其为:直接定址表。
我们可以在直接定址表中存储子程序的地址,从而方便地实现不同子程序的调用。
例如:实现一个子程序setscreen ,为显示输出提供如下功能:
(1)清屏。
(2)设置前景色。
(3)设置背景色。
(4)向上滚动一行
各个子程序入口参数说明:
1)用ah 寄存器传递功能号:
0 表示清屏,
1表示设置前景色,
2 表示设置背景色,
3 表示向上滚动一行;
2)对于2、3号功能,用al传送颜色值,
我们讨论一下各种功能如何实现:
①清屏:将显存中当前屏幕中的字符设为空格符;
②设置前景色:设置显存中当前屏幕中处于奇地址的属性字节的第0、1、2位;
③设置背景色:设置显存中当前屏幕中处于奇地址的属性字节的第4、5、6位;
④向上滚动一行:依次将第n+1行的内容复制到第n行处:最后一行为空。
使用根据功能号查找地址表的方法,程序的结构清晰,便于扩充。如果加入一个新的功能子程序,那么只需要在地址表中加入它的入口地址就可以了。
具体程序代码前去www.cnblogs.com/mq0036/p/5163181.html查看
第十七章 使用BIOS进行键盘输入和磁盘读写
- 1. int 9中断例程对键盘输入的处理
我们已经讲过,键盘输入将引发9 号中断,BIOS 提供了int 9 中断例程。
CPU 在9 号中断发生后,执行int 9中断例程,从60h 端口读出扫描码,并将其转化为相应的ASCII 码或状态信息,存储在内存的指定空间(键盘缓冲区或状态字节)中。键盘缓冲区中有16 个字单元,可以存储15个按键的扫描码和对应的入ASCII 码。
- 2. 使用int 16h中断例程读取键盘缓冲区
BIOS提供了int 16h 中断例程供程序员调用。
int 16h 中断例程中包含的一个最重要的功能是从键盘缓冲区中读取一个键盘输入,该功能的编号为0。下面的指令从键盘缓冲区中读取一个键盘输入,并且将其从缓冲区中删除:
mov ah,0
int 16h
结果:
(ah)=扫描码,
(al)=ASCII码。
int 16h 中断例程的0 号功能,进行如下的工作:
(1)检测键盘缓冲区中是否有数据;
(2)没有则继续做第1 步;
(3)读取缓冲区第一个字单元中的键盘输入;
(4)将读取的扫描码送入ah,ASCII 码送入al;
(5)将己读取的键盘输入从缓冲区中删除。
可见,B1OS 的int 9 中断例程和int 16h 中断例程是一对相互配合的程序,int 9 中断例程向键盘缓冲区中写入,int 16h 中断例程从缓冲区中读出。它们写入和读出的时机不同,int 9 中断例程在有键按下的时候向键盘缓冲区中写入数据;而int 16h 中断例程是在应用程序对其进行调用的时候,将数据从键盘缓冲区中读出。
在我们的课程中,仅在逻辑结构的基础上,讨论BIOS键盘缓冲区的读写问题。其实键盘缓冲区是用环形队列结构管理的内存区,但我们不对队列和环形队列的实现进行讨论。
- 3. 应用int13h中断例程对磁盘进行读写
常用的3.5英寸软盘的结构:
分为上下两面,每面有80个磁道,每个磁道又分为18个扇区,每个扇区的大小为512B。
总容量为:2面×80磁道×18扇区×512B=1440KB≈1.44MB
磁盘的实际访问由磁盘控制器进行,我们可以通过控制磁盘控制器来访问磁盘。只能以扇区为单位对磁盘进行读写。在读写扇区的时候,要给出面号、磁道号和扇区号。面号和磁道号从0开始,而扇区号从1开始。如果我们通过直接控制磁盘控制器来访问磁盘,则需要涉及许多硬件细节。BIOS提供了对扇区进行读写的中断例程,这些中断例程完成了许多复杂的和硬件相关的工作。我们可以通过调用BIOS中断例程来访问磁盘。
BIOS 提供的访问磁盘的中断例程为int 13h 。如下:
1)读取0面0道1扇区的内容到0:200:
mov ax,0
mov es,ax
mov bx,200h
mov al,1
mov ch,0
mov cl,1
mov dl,0
mov dh,0
mov ah,2
int 13h
入口参数:
(ah)=int 13h的功能号(2表示读扇区)
(al)=读取的扇区数
(ch)=磁道号
(cl)=扇区号
(dh)=磁头号(对于软驱即面号,因为一个面用一个磁头来读写)
(dl)=驱动器号
软驱从0开始,0:软驱A,1:软驱B;
硬盘从80h开始,80h:硬盘C,81h:硬盘D。
es:bx指向接收此扇区读入数据的内存区
返回参数:
操作成功:(ah)=0,(al)=读入的扇区数
操作失败:(ah)=出错代码
2)将0:200中的内容写入0面0道1扇区:
mov ax,0
mov es,ax
mov bx,200h
mov al,1
mov ch,0
mov cl,1
mov dl,0
mov dh,0
mov ah,3
int 13h
入口参数:
(ah)=int 13h的功能号(3表示写扇区)
(al)=写入的扇区数
(ch)=磁道号
(cl)=扇区号
(dh)=磁头号(面)
(dl)=驱动器号
软驱从0开始,0:软驱A,1:软驱B;
硬盘从80h开始,80h:硬盘C,81h:硬盘D。
es:bx指向将写入磁盘的数据
返回参数:
操作成功:(ah)=0,(al)=写入的扇区数
操作失败:(ah)=出错代码
注意:
下面我们要使用int 13h 中断例程对软盘进行读写。直接向磁盘扇区写入数据是很危险的,很可能覆盖掉重要的数据。
如果向软盘的0 面0 道1 扇区中写入了数据,要使软盘在现有的操作系统下可以使用,必须要重新格式化。
①②③④⑤⑥⑦⑧⑨⑩
下面可以学习:
罗云斌—《win32汇编》
程序的测试代码以及word版笔记下载地址:练习代码和笔记