通过MS SQL列存储索引实现大数据解决方案
现如今的大数据处理方案需要在比以往更短的时间内应对越来越大的数据量。MS SQL 2012版本首次引入了列存储(CS)索引技术,这也是SQL Server首次尝试从传统的行存储结构转变为面向列的存储方案,他们承诺这种方案能够以最低限度的额外工作量换取更高的性能。
MS SQL列存储索引的主要目标是将尽量多的数据加载至内存中,在进行数据处理时将访问内存,而不是直接从磁盘中读取。这种处理方式有两大优点,一是速度更快,二是硬盘的IOPS(每秒读写次数)消耗更低。但这一功能尚未臻完美。2012版本中的问题在于它仅支持只读模式,虽然这一缺点在2014版本中通过聚集列存储索引(Clustered CS Index)得到了弥补,允许用户在表中修改数据。但在使用聚集列存储索引的同时,就无法建立普通的索引,也不支持计算列、外键和触发器。在处理数据的时候,了解在哪种场景中使用哪种索引方案最为高效,这一点至关重要。
历史背景
列存储技术背后的思想并不是微软首创的,早在上世纪70年代,基于列的存储系统就与传统的行存储数据库管理系统一同出现了。最广为人知的基于列的关系型数据库软件系统之一是上世纪90年代问世的Sybase IQ,它目前归属于SAP。在之后的岁月中不断出现了各种新产品,这一趋势改变了商业智能这一技术领域的发展,也拓展了大数据技术的市场。这些产品中最为知名的包括Vertica、ParAccel、Kognito、Infobright以及SAND。列存储技术在MS SQL Server 2012中首次亮相,它的基本思想是将数据按照列分组后再保存,而不是按照行进行分组。
传统的RDBMS中的数据类似于下表中的呈现,每一页中的数据会包含多个列,或许会包括更多的行:
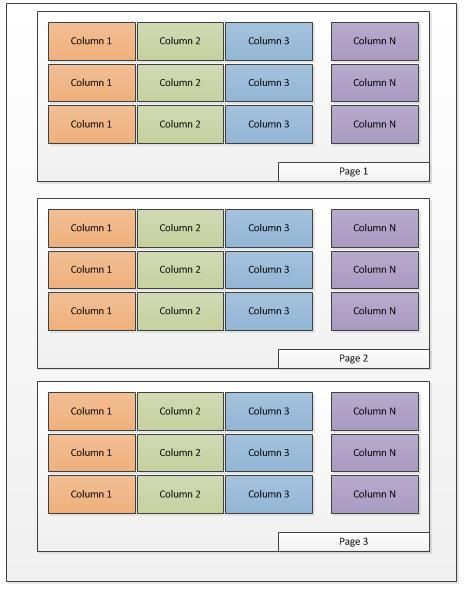
以下是一份示例数据:
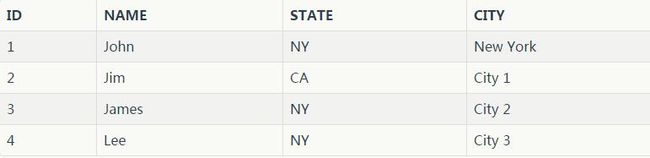
目前为止一切良好。
过量的数据读取与生产力的下降
问题来了:如果有一张表包含了大量的列,并假设要获取某个指定的结果只需要返回1至3列的数据。在这种情况下,MS SQL仍然需要读取包含了所有列数据的整个页,并“返回”所需的那部分数据。这就造成了过量的数据读取,从而导致了生产力的下降。
让我们考虑一下微软所提出的新的存储方式,以了解MS SQL如何帮助我们解决这一问题:


在上表中,数据是按照列进行分组的。这样分组的数据具有很高的一致性,因而提高了数据的压缩比。这样一来,就可以将更多的数据直接加载至内存中,而不是从磁盘中进行读取。如果在查询中只需要某一列数据,MS SQL Server就只会读取对应数据所在的页。正如我之前所说,这种方式具有两个优点:更快的速度和更低的硬盘IOPS消耗。
在数据的一致性程度与数据的压缩比之间存在着一种确定的相关性。基于列的数据组织方式通常会假定数据具有一定的一致性,可能的变化较少(在我们的示例中仅有两个值:NY和CA),这也意味着能够将更多的数据进行压缩后加载至内存中。数据的可变性越大,压缩的CPU时间就越长,并且压缩比也越低。但即便如此,列存储仍然具有高效性,因为系统只需要处理必要的数据,而不是遍历包含数据的全部页。因此,在处理数据时,应牢记所选择的数据的类型将影响处理的速度,这一点十分重要。
同样重要的是了解SQL Server列存储索引在使用方面的限制。在MS SQL 2012与2014中的列存储技术存在着巨大的差异,MS SQL 2014支持聚集与非聚集的列存储索引,而2012仅支持非聚集索引。以下是列存储的使用限制:
- 在列存储索引中不可使用以下数据类型:
- binary(n)、varbinary(n)(在2014及更高版本中允许使用,但不包括varbinary(max))
- image、text、ntext、varchar(max)、nvarchar(max)
- sql_variant
- xml
- 只能通过删除及创建索引的方式重建索引,而不可使用ALTER INDEX命令
- 在视图或索引视图中无法使用列存储索引
- 列存储索引无法结合使用以下特性:
- 分发
- 变更数据捕获
- 变更追踪
- Filestream
- 列存储索引不可包含多于1024个列
- 对应的表不可包含唯一性约束、主键约束或外键约束
使用列存储索引时所隐含的一些挑战
虽然列存储索引技术看上去前景非常光明,但在2012版中对于它的使用仍然有许多重大限制。
最大的不便之处在于,使用了列存储索引的表将无法进行数据的变更、新增或删除。实际上,这张表已经进入了只读状态。用户不得不采取以下方式应对:首先删除索引,加载变更后再重建索引。对于海量数据来说,整个过程所占用的超长时间足以抵消列存储索引功能所带来的正面效果。
在MS SQL Server 2014版中宣布引入了聚集列存储索引,它允许在表中进行数据修改。但问题在于,使用列存储索引之后,就无法使用计算字段、外键与触发器了。因此,在使用列存储索引功能时,对以上所提及的限制要事先有所警觉。
列存储的惊艳效果
列存储功能体验足以令人惊艳,让我们来看一下以下示例:我们在表中保存的销售数据超过5千万条记录。现在让我们尝试一下计算每个客户的销售总额。
运行以下查询:
-- 清除SQL SERVER查询缓存
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT CUSTOMER_ID, SUM(AMOUNT)
FROM ORDER_DETAILS
GROUP BY CUSTOMER_ID
以下是运行的结果:
表'ORDER_DETAILS'。扫描5次,逻辑读132615,物理读取0,预读132622,lob逻辑读0,lob物理读0,lob预读0.
SQL Server执行时间:
CPU time = 12699 ms, elapsed time = 11064 ms.
执行计划:
(点击放大图像)

聚集扫描详细信息:
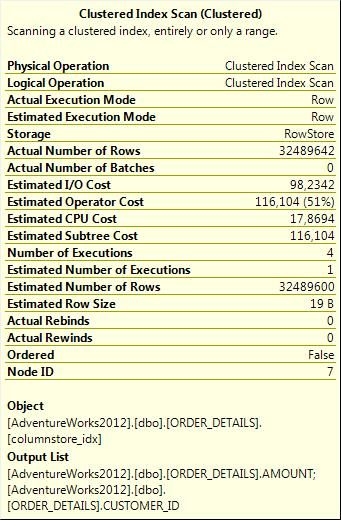
现在让我们来创建一个聚集列存储索引,并再次运行该查询(在查询执行前必须先清除缓存)。应当指出的是,在这种数据量的表中创建索引大约需要一分钟左右时间。我们还必须删除表中的聚集索引,因为一张表无法包含两个聚集索引,这是使用列存储索引的限制,正如我们在上文中所说的。
CREATE CLUSTERED COLUMNSTORE INDEX columnstore_idx ON ORDER_DETAILS
现在让我们再一次运行之前的那个查询:
-- 清除SQL SERVER查询缓存
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT CUSTOMER_ID, SUM(AMOUNT)
FROM ORDER_DETAILS
GROUP BY CUSTOMER_ID
结果如下:
表'ORDER_DETAILS'。扫描4次,逻辑读35262,物理读23,预读48195,lob逻辑读0,lob物理读0,lob预读0。
SQL Server执行时间:
CPU time = 1248 ms, elapsed time = 1634 ms.
执行计划:
(点击放大图像)

列存储索引扫描详细信息:
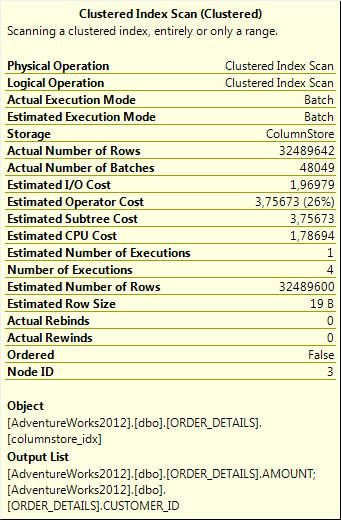
是不是惊艳到你了?对你的反应我们期待以久了。
如你所见,使用列存储索引之后,读取次数下降了4倍,而执行时间下降了10倍。
但如果是对数据进行搜索呢?
让我们尝试在一个使用了列存储索引的表中运行以下查询:
-- 清除SQL SERVER查询缓存
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
SET STATISTICS IO ON
SET STATISTICS TIME ON
declare @p1 float
declare @p2 float
set @p1 = 100.0
set @p2 = 200.0
SELECT CUSTOMER_ID, AMOUNT FROM ORDER_DETAILS
WHERE CUSTOMER_ID = 651 AND AMOUNT BETWEEN @p1 AND @p2
(1571 row(s) affected)
表'ORDER_DETAILS'。扫描4次,逻辑读36031,物理读21,预读52794,lob逻辑读0,lob物理读0,lob预读0。
SQL Server执行时间:
CPU time = 79 ms, elapsed time = 1125 ms.
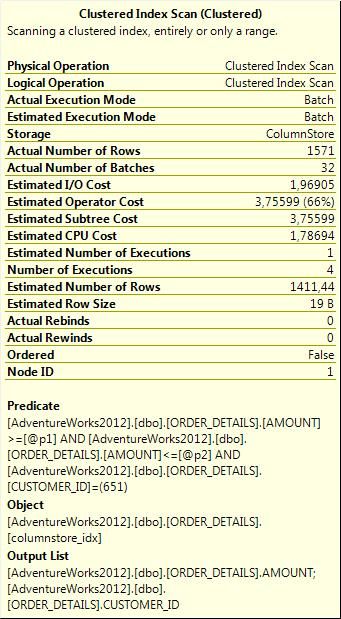
在我看来结果还可以。
现在让我们删除列存储索引,并创建我们所需的索引:
CREATE INDEX idx1 ON ORDER_DETAILS(CUSTOMER_ID, AMOUNT)
然后再次运行相同的查询
(1571 row(s) affected)
表'ORDER_DETAILS'。扫描1次,逻辑读9,物理读1,预读5,lob逻辑读0,lob物理读0,lob预读0。
(1 row(s) affected)
SQL Server执行时间:
CPU time = 0 ms, elapsed time = 254 ms.
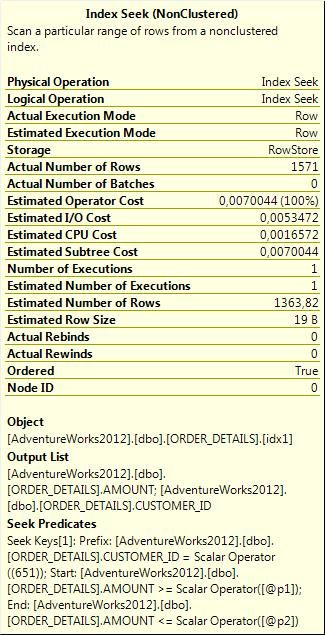
很显然,列存储索引此时就毫无用武之地了。当然了,没有哪种“惊艳”是与生俱来的。并且可以有把握的说,记录的数量越多,服务器的负载越大,列存储索引的效率就越低。之所以产生这种结果,是因为这种查询需要读取大量的信息,并且无法使用普通的“搜索”索引。好消息是,微软已经宣布在MS SQL 2016中同时支持列存储索引与B树索引了。
但是,如果我们既想要实现快速的搜索,同时又想要进行快速的计算并获得统计数据,我们该怎么办呢?在MS SQL 2012中,我们只剩下一种选择:定期地创建一个备份表,为其添加必要的聚集索引。由于在MS SQL 2014中引入了聚集列存储索引,我们就能够更新数据了,但必须在主表与备份表中同时进行数据的添加与修改。不过,如果你问我最好的办法是什么,我会回答你还是耐心等待2016问世吧!
在SQL Server 2016中我们将看到以下一些主要变化:
- 之前版本中的非聚集列存储索引都是只读的。在2016中,行存储表(即不包含聚集列存储索引的表)中将能够创建一个可更新的非聚集列存储索引。
- 在之前版本中,使用列存储索引的表不支持普通的非聚集索引。在2016中,非聚集列存储索引定义支持使用某种经过滤的条件,在使用聚集列存储索引的表中可定义一至多个非聚集的普通行存储索引。
- 在聚集列存储索引表中将支持使用主键与外键,通过使用B树的方式强制这些约束。
总的来说,列存储索引技术并非适用一切场合的银弹,但它确实能够表现出非凡的结果。对于通过联机分析处理(OLAP)的Cube进行数据汇总的场景,它表现十分完美,能够促进生产力的提高。不过,常规的索引以及常规的表优化手段在大数据处理方面仍有用武之地,同样能够表现出良好的结果,前提是你知道怎样以及何时使用他们。
关于作者
 Aleksandr Shavlyuga于1999年毕业于白俄罗斯国立大学(Belarusian State University),随后在多个IT公司中担任Delphi开发者、软件架构师、数据库架构师以及管理员。他在2007加入Itransition担任.NET开发者,并在2008年升任高级开发者。Aleksandr拥有Brainbench颁发的ANSI SQL和MS SQL Programmer证书。他现在专注于打造高伸缩的web应用与数据库设计。他在技术方面感兴趣的领域包括.NET以及Oracle和MS SQL Server数据库。
Aleksandr Shavlyuga于1999年毕业于白俄罗斯国立大学(Belarusian State University),随后在多个IT公司中担任Delphi开发者、软件架构师、数据库架构师以及管理员。他在2007加入Itransition担任.NET开发者,并在2008年升任高级开发者。Aleksandr拥有Brainbench颁发的ANSI SQL和MS SQL Programmer证书。他现在专注于打造高伸缩的web应用与数据库设计。他在技术方面感兴趣的领域包括.NET以及Oracle和MS SQL Server数据库。
查看英文原文:Big Data Solutions with MS SQL ColumnStore Index