利用In-Database Analytics技术在大规模数据上实现机器学习的SGD算法
随着应用数据的增长,在大规模数据集上进行统计分析和机器学习越来越成为一个巨大的挑战。目前,适用于统计分析/机器学习的语言/库有很多,如专为数据分析用途而设计的R语言,Python语言的机器学习库Scikits,支持分布式环境扩展的有基于Map-Reduce实现的Mahout,以及分布式内存计算框架Spark上的机器学习库MLlib等等。目前Spark框架也推出了R语言的接口SprakR。但是,本文要讨论的,则是另外一种设计思路,在database中实现统计分析和机器学习算法,即In-Database Analysis,Madlib库就是这种设计思路的代表。
把机器学习库内置到database中(通过database的UDF)有许多优点,执行机器学习算法时只需要编写相应的SQL语句就可以了,同时database本身作为分析的数据源,使用非常方便,大大降低了机器学习的应用门槛。当然缺点也是明显的,由于受限于database提供的UDF编程接口,实现算法时会受到很多限制,很多优化难以实现,而大规模数据集上的机器学习,尤其是需要迭代计算的,通常对算法性能和结果收敛速度要求较高,否则很难做到实用。本文的重点就是讨论如何在In-database Analysis的框架下,高效的实现机器学习中的SGD(随机梯度下降)算法。由于很多机器学习算法如linear SVM分类器、K-mean、Logistic Regression都可以采用SGD算法来实现,只需要针对不同算法设计不同的目标函数即可。因此在database上实现高性能的SGD算法框架,便可用来执行一大类机器学习算法。
以Madlib为例,如果要Madlib用SVM算法对数据集做训练,可以执行如下SQL语句:
SELECT madlib.lsvm_classification( 'my_schema.my_train_data',
'myexpc',
false
);
madlib.lsvm_classification是Madlib中实现的SVM计算函数,上述方式的调用则是采用SGD算法进行linear SVM分类,其中my_schema.my_train_data是训练数据表,必须满足如下结构定义:
TABLE/VIEW my_schema.my_train_table
(
id INT, -- point ID
ind FLOAT8[], -- data point
label FLOAT8 -- label of data point,即分类结果
);
执行之后生成的Model将会被存到第二个参数’myexpec’指定的表中。第三个参数(true/false)指定算法是否需要并行执行。
生成Model表myexpec后,执行以下SQL语句就可以进行预测:
SELECT madlib.lsvm_predict( 'myexpc',
'{10,-2,4,20,10}'
);
madlib.lsvm_classification函数还有更多的参数可以设置。如可以设置kernel-function,那么这时候计算实现的方式就不是SGD了,还可以设置迭代精度阈值等,具体参见Madlib文档。
从这个例子可以看出,Madlib库的使用是非常方便的,只要我们按照库函数要求建好相应的数据表并导入数据,就可以通过调用Madlib库中的SQL函数来进行模型训练和模型预测了。目前Madlib支持PostgreSQL、Greenplum、Pivotal HAWQ。
但是,在很多情形下,Madlib的执行性能是很差的,以基于SGD算法实现的机器学习训练模型为例,在数据量大的情况下经常需要几十小时甚至几百小时来完成,为了提高计算速度和模型收敛速度,有两个非常值得优化的地方:一是改为并发更新模型,二是优化数据读取顺序。
首先看基本的SGD算法框架在database的UDFA(自定义聚合函数)上的实现。以linear SVM为例,可以定义如下目标函数f(x):
![]()
其中<xi, yi>就是训练数据,w是训练模型。如下的梯度下降算法通过迭代找出使这个目标函数值尽可能小的w:

其中![]() 是步长值。
是步长值。
但是直接按照上式计算,每迭代一次,就需要遍历所有的数据,难以在实际场景中应用,因此就有了SGD(随机梯度下降)算法,对每一步迭代中的f(x),近似的用随机的一个数据点来代替原有f(x)中对所有数据点的求和:
![]()
在原始数据顺序随机的情况下,每次迭代只需要顺次取出一条记录并按上式进行迭代即可。这种迭代更新的计算方式,和database中提供的UDFA扩展接口是非常吻合的。可以把这个计算过程抽象为三个函数:
initialize(state) transition(state, row_data) terminate(state)
state用于存储这个UDFA计算上下文,对应SDG算法,state存的就是不停被迭代更新的model。row_data是每次读入的一行记录,即一个数据点。terminate函数返回最终的计算结果。具体这三个函数调用的次序如下图所示:

在PostgreSQL数据库中,这三个函数分别被命名为initcond、sfunc和finalfunc。
在训练数据表上执行一次这样的UDFA,相当于顺次用表中所有的数据按照上述的迭代式计算了一遍。通常要对总体数据迭代多遍才能得到想要精度的结果,因此Madlib库中那些训练函数实际上是用SQL脚本语言编写的函数,其中包含了对整个表数据的多轮迭代,直到获得所需精度的结果。如果数据表的数据顺序是有序的,那么顺次迭代将大大降低算法的收敛速度,这时可以先将数据表的数据顺序打乱再执行上述算法,如在PostgreSQL中,可以先用order by random()打乱数据顺序,然后再进行迭代计算。
上述的UDFA执行过程存在着两大缺陷:1.没有并行化。2.在数据量大的情况下,将数据次序打乱可能是一个非常大的开销。下面先讨论并行化的改进方案:
一个简单的并行化计算方法是,将表数据分为多个部分,每个部分有自己的model state,每个部分的model各自进行各自的迭代计算,当各个model都计算完毕时再进行合并。简单的合并方案就是将所有的model做平均值得到最终的model。为什么SDG算法可以用这种方法拆分计算然后取model平均值,可以参见这篇论文[1]。当然,这要求database对UDFA提供一个merge(state, state)的函数接口让用户来自定义合并方式。这种简单的并行化方式不仅可以应用在单机database上,也可以用在数据分布到多个结点上的分布式database/datawarehouse上,如Cloudera Impala。但是这种简单的share nothing的并行计算方案通常会极大的影响model的收敛速度,因此还需要寻找更好的并行执行方案。
实现不影响收敛速度的并行执行,就需要所有在不同区段数据上并发执行的UDFA去更新同一个model,这就要database提供Share-Memory的接口以便于UDFA访问共享内存。像PostgreSQL就提供了相应的接口[3]。
但是这种并发更新model的方式又带来了另外一个矛盾,在用迭代式更新model时必须对model加锁,假设多个UDFA计算线程同时工作,在同一时刻显然只有一个线程能获得锁进行计算并更新模型,本质上还是等同于单线程的计算效率。要解决这个矛盾,可以采用论文[2]中提出的lock-free parallelizing SGD算法。这个算法避免了更新model时对model加锁,核心思想是通过稀疏化model,使得每次迭代只需要更新model中的很少一部分分量,然后证明在lock-free方式下并发更新,收敛速度有一个不错的下限。
第二个问题是如何避免大数据量情况下打乱数据次序的开销,因为如果原始数据是有序的话,可能对model收敛速度有很大影响,但是打乱大量数据通常又要耗费大量开销。一个简单的方法是,对所有表数据做reservior sampling,这是一个经典的算法,通过一遍扫描原始数据集进行等概率抽样。然后对抽样数据打乱次序后在抽样数据上进行迭代。当然这种算法缺点也很明显,大量有效的数据点被舍弃了,对训练结果的准确性影响很大。为了避免这个缺陷,可以把数据抽样和按数据顺序迭代相结合,即如下的multiplexed reservior sampling:
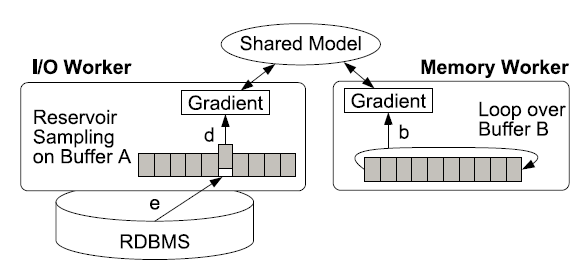
如上图所示,设立两个工作线程并发更新Model,一个是I/O线程,分配好buffer A;另一个是Memory线程,分配好buffer B。
第一轮迭代,只有I/O线程工作,假设buffer A的容量为M,总记录数为N,遍历每一条记录,前M条记录直接填入buffer A。从M+1条记录开始,假设当前为第i条记录,第i条记录有M/i的概率被选中,如果被选中那么替换掉buffer A中的随机一条记录,替换出的记录被丢弃,否则直接丢弃第i条记录。这时候用被丢弃的记录更新模型,直到所有记录遍历完成。
第一轮迭代后交换buffer A和buffer B。第二轮以后的迭代都是I/O线程和Memory线程同时工作。Memory线程负责循环读取出buffer B中的数据并用来更新model,I/O线程的工作和第一轮的工作方式相同。每一轮迭代过后交换buffer使得memory线程可以用到上一轮I/O线程采样出的数据。
基于Hadoop的分布式SQL查询引擎Cloudera Impala也集成了Madlib库,当然现在还很不成熟,感兴趣的读者可以点击:
http://blog.cloudera.com/blog/2013/10/how-to-use-madlib-pre-built-analytic-functions-with-impala/
这个项目的Github地址在:
https://github.com/cloudera/madlibport
这个项目把Madlib库和Bismark计算框架移植到了Impala上,当然好处是可以利用Impala的分布式处理能力,至于性能和成熟度,目前还无法期待太多,毕竟Imapla也才刚刚在1.2的版本中加入了UDFA的编程接口,还有太多局限的地方。
参考文献
[1]M.Zinkevich,M.Weimer,A.Smola,and L.Li.Parallelized Stochastic Gradient Descent.In NIPS,2010.
[2]F.Niu,B.Recht,C.R e,and S.Wright.Hogwild:A Lock-Free Approach to Parallelizing Stochastic Gradient Descent.In NIPS,2011.
[3]http://www.postgresql.org/docs/9.3/static/xfunc-c.html#AEN53973
作者
梁堰波,北京航空航天大学计算机硕士,美团网资深工程师,曾在法国电信、百度和VMware工作和实习,这几年一直在折腾Hadoop/HBase/Impala和数据挖掘相关的东西,新浪微博 @DataScientist。
徐伟辰,北京航空航天大学计算机硕士,IBM中国软件开发中心研发工程师,参与开发过大数据分析平台,PaaS平台,熟悉Hadoop相关技术,目前的兴趣点在大数据分析技术及相关算法和工具。