从命令式编程到Fork/Join再到Java 8中的并行Streams
Java 8带来了很多可以使编码更简洁的特性。例如,像下面的代码:
Collections.sort(transactions, new Comparator<Transaction>(){
public int compare(Transaction t1, Transaction t2){
return t1.getValue().compareTo(t2.getValue());
}
});
可以用替换为如下更为紧凑的代码,功能相同,但是读上去与问题语句本身更接近了:
transactions.sort(comparing(Transaction::getValue));
Java 8引入的主要特性是Lambda表达式、方法引用和新的Streams API。它被认为是自20年前Java诞生以来语言方面变化最大的版本。要想通过详细且实际的例子来了解如何从这些特性中获益,可以参考本文作者和Alan Mycroft共同编写的《Java 8 in Action: Lambdas, Streams and Functional-style programming》一书。
这些特性支持程序员编写更简洁的代码,还使他们能够受益于多核架构。实际上,编写可以优雅地并行执行的程序还是Java专家们的特权。然而,借助新的Streams API,Java 8改变了这种状况,让每个人都能够更容易地编写利用多核架构的代码。
在这篇文章中,我们将使用以下三种风格,以不同方法计算一个大数据集的方差,并加以对比。
- 命令式风格
- Fork/Join框架
- Streams API
方差是统计学中的概念,用于度量一组数的偏离程度。方差可以通过对每个数据与平均值之差的平方和求平均值来计算。例如,给定一组表示人口年龄的数:40、30、50和80,我们可以这样计算方差:
- 计算平均值:(40 + 30 + 50 + 80) / 4 = 50
- 计算每个数据与平均值之差的平方和:(40-50)2 + (30-50)2 + (50-50)2 + (80-50)2 = 1400
- 最后平均:1400/4 = 350
命令式风格
下面是计算方差的一种典型的命令式风格实现:
public static double varianceImperative(double[] population){
double average = 0.0;
for(double p: population){
average += p;
}
average /= population.length;
double variance = 0.0;
for(double p: population){
variance += (p - average) * (p - average);
}
return variance/population.length;
}
为什么说这是命令式的呢?我们的实现用修改状态的语句序列描述了计算过程。这里,我们显式地对人口年龄数组中的每个元素进行迭代,而且每次迭代时更新average和variance这两个局部变量。这种代码很适合只有一个CPU的硬件架构。确实,它可以非常直接地映射到CPU的指令集。
Fork/Join框架
那么,如何编写适合在多核架构上执行的实现代码呢?应该使用线程吗?这些线程是不是要在某个点上同步?Java 7引入的Fork/Join框架缓解了一些困难,所以让我们使用该框架来开发方差算法的一个并行版本吧。
public class ForkJoinCalculator extends RecursiveTask<Double> {
public static final long THRESHOLD = 1_000_000;
private final SequentialCalculator sequentialCalculator;
private final double[] numbers;
private final int start;
private final int end;
public ForkJoinCalculator(double[] numbers, SequentialCalculator sequentialCalculator) {
this(numbers, 0, numbers.length, sequentialCalculator);
}
private ForkJoinCalculator(double[] numbers, int start, int end, SequentialCalculator
sequentialCalculator) {
this.numbers = numbers;
this.start = start;
this.end = end;
this.sequentialCalculator = sequentialCalculator;
}
@Override
protected Double compute() {
int length = end - start;
if (length <= THRESHOLD) {
return sequentialCalculator.computeSequentially(numbers, start, end);
}
ForkJoinCalculator leftTask = new ForkJoinCalculator(numbers, start, start + length/2,
sequentialCalculator);
leftTask.fork();
ForkJoinCalculator rightTask = new ForkJoinCalculator(numbers, start + length/2, end,
sequentialCalculator);
Double rightResult = rightTask.compute();
Double leftResult = leftTask.join();
return leftResult + rightResult;
}
}
这里我们编写了一个RecursiveTask类的子类,它对一个double数组进行切分,当子数组的长度小于等于给定阈值(THRESHOLD)时停止切分。切分完成后,对子数组进行顺序处理,并将下列接口定义的操作应用于子数组。
public interface SequentialCalculator {
double computeSequentially(double[] numbers, int start, int end);
}
利用该基础设施,可以按如下方式并行计算方差。
public static double varianceForkJoin(double[] population){
final ForkJoinPool forkJoinPool = new ForkJoinPool();
double total = forkJoinPool.invoke(new ForkJoinCalculator
(population, new SequentialCalculator() {
@Override
public double computeSequentially(double[] numbers, int start, int end) {
double total = 0;
for (int i = start; i < end; i++) {
total += numbers[i];
}
return total;
}
}));
final double average = total / population.length;
double variance = forkJoinPool.invoke(new ForkJoinCalculator
(population, new SequentialCalculator() {
@Override
public double computeSequentially(double[] numbers, int start, int end) {
double variance = 0;
for (int i = start; i < end; i++) {
variance += (numbers[i] - average) * (numbers[i] - average);
}
return variance;
}
}));
return variance / population.length;
}
本质上,即便使用Fork/Join框架,相对于顺序版本,并行版本的编写和最后的调试仍然困难许多。
并行Streams
Java 8让我们可以以不同的方式解决这个问题。不同于编写代码指出计算如何实现,我们可以使用Streams API粗线条地描述让它做什么。作为结果,库能够知道如何为我们实现计算,并施以各种各样的优化。这种风格被称为声明式编程。Java 8有一个为利用多核架构而专门设计的并行Stream。我们来看一下如何使用它们来更快地计算方差。
假定读者对本节探讨的Stream有些了解。作为复习,Stream<T>是T类型元素的一个序列,支持聚合操作。我们可以使用这些操作来创建表示计算的一个管道(pipeline)。这里的管道和UNIX的命令管道一样。并行Stream就是一个可以并行执行管道的Stream,可以通过在普通的Stream上调用parallel()方法获得。要复习Stream,可以参考Javadoc文档。
好消息是,Java 8 API内建了一些算术操作,如max、min和average。我们可以使用Stream的几种基本类型特化形式来访问前面几个方法:IntStream(int类型元素)、LongStream(long类型元素)和DoubleStream(double类型元素)。例如,可以使用IntStream.rangeClosed()创建一系列数,然后使用max()和min()方法计算Stream中的最大元素和最小元素。
回到最初的问题,我们想使用这些操作来计算一个规模较大的人口年龄数据的方差。第一步是从人口年龄数组创建一个Stream,可以通过Arrays.stream()静态方法实现:
DoubleStream populationStream = Arrays.stream(population).parallel();
我们可以使用DoubleStream所支持的average()方法:
double average = populationStream.average().orElse(0.0);
下一步是使用average计算方差。人口年龄中的每个元素首先需要减去平均值,然后计算差的平方。可以将其视作一个Map操作:使用一个Lambda表达式(double p) -> (p - average) * (p - average)把每个元素转换为另一个数,这里是转换为该元素与平均值差的平方。一旦转换完成,我们就可以调用sum()方法来计算所有结果元素的和了。.
不过别那么着急。Stream只能消耗一次。如果复用populationStream,我们会碰到下面这个令人惊讶的错误:
java.lang.IllegalStateException: stream has already been operated upon or closed
所以我们需要使用第二个流来计算方差,如下所示:
public static double varianceStreams(double[] population){
double average = Arrays.stream(population).parallel().average().orElse(0.0);
double variance = Arrays.stream(population).parallel()
.map(p -> (p - average) * (p - average))
.sum() / population.length;
return variance;
}
通过使用Streams API内建的操作,我们以声明式、而且非常简洁的方式重写了最初的命令式风格代码,而且声明式风格读上去几乎就是方差的数学定义。我们再来研究一下三种实现版本的性能。
基准测试
我们以非常不同的风格编写了三个版本的方差算法。Stream版本是最简洁的,而且是以声明式风格编写的,它让类库去确定具体的实现,并利用多核基础设施。不过你可能想知道它们的执行效果如何。为找出答案,让我们创建一个基准测试,对比一下三个版本的表现。我们先随机生成1到140之间的3000万个人口年龄数据,然后计算其方差。我们使用jmh来研究每个版本的性能。Jmh是OpenJDK支持的一个Java套件。读者可以从GitHub克隆该项目,自己运行基准测试。
基准测试运行的机器是Macbook Pro,配备2.3 GHz的4核Intel Core i7处理器,16GB 1600MHz DDR3内存。此外,我们使用的JDK 8版本如下:
java version "1.8.0-ea" Java(TM) SE Runtime Environment (build 1.8.0-ea-b121) Java HotSpot(TM) 64-Bit Server VM (build 25.0-b63, mixed mode)
结果用下面的柱状图说明。命令式版本用了60毫秒,Fork/Join版本用了22毫秒,而流版本用了46毫秒。
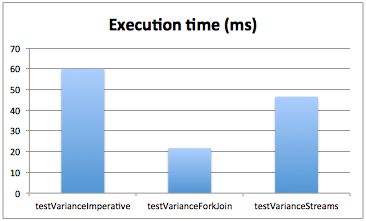
这些数据应该谨慎对待。比如,如果在32位JVM上运行测试,结果很可能有较大的差别。然而有趣的是,使用Java 8中的Streams API这种不同的编程风格,为在场景背后执行一些优化打开了一扇门,而这在严格的命令式风格中是不可能的;相对于使用Fork/Join框架,这种风格也更为直接。
关于作者
 Raoul-Gabriel Urma 20岁开始在剑桥大学攻读计算机科学博士学位。他的研究主要关注的是编程语言与软件工程。他以一等荣誉生的成绩获得了伦敦帝国理工学院的计算机科学工程硕士学位,并赢得一些技术创新奖项。他曾经为Google、eBay、Oracle和Goldman Sachs等很多大公司工作过,也参与过不少创业项目。此外,他还经常在Java开发者会议上发表讲话,也是一位Java课程讲师。他的Twitter:@raoulUK,网站。
Raoul-Gabriel Urma 20岁开始在剑桥大学攻读计算机科学博士学位。他的研究主要关注的是编程语言与软件工程。他以一等荣誉生的成绩获得了伦敦帝国理工学院的计算机科学工程硕士学位,并赢得一些技术创新奖项。他曾经为Google、eBay、Oracle和Goldman Sachs等很多大公司工作过,也参与过不少创业项目。此外,他还经常在Java开发者会议上发表讲话,也是一位Java课程讲师。他的Twitter:@raoulUK,网站。
 Mario Fusco 是Red Hat的一位高级软件工程师,主要从事Drools核心和JBoss规则引擎方面的开发工作。作为Java开发者,他有着丰富的经验,参与了从媒体公司到金融部门等行业的很多企业级项目,而且经常作为项目的领导者。他的兴趣包括函数式编程和领域特定语言(Domain Specific Language,DSL)。凭借在这两个方面的激情,他创建了开源类库lambdaj,意在在Java中为操作集合提供一种内部Java DSL,并支持一点函数式编程。他的Twitter是@mariofusco。
Mario Fusco 是Red Hat的一位高级软件工程师,主要从事Drools核心和JBoss规则引擎方面的开发工作。作为Java开发者,他有着丰富的经验,参与了从媒体公司到金融部门等行业的很多企业级项目,而且经常作为项目的领导者。他的兴趣包括函数式编程和领域特定语言(Domain Specific Language,DSL)。凭借在这两个方面的激情,他创建了开源类库lambdaj,意在在Java中为操作集合提供一种内部Java DSL,并支持一点函数式编程。他的Twitter是@mariofusco。
查看英文原文:From Imperative Programming to Fork/Join to Parallel Streams in Java 8