机器学习实战笔记——基于KNN算法的手写识别系统
本文主要利用k-近邻分类器实现手写识别系统,训练数据集大约2000个样本,每个数字大约有200个样本,每个样本保存在一个txt文件中,手写体图像本身是32X32的二值图像,如下图所示:

首先,我们需要将图像格式化处理为一个向量,把一个32X32的二进制图像矩阵通过img2vector()函数转换为1X1024的向量:
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
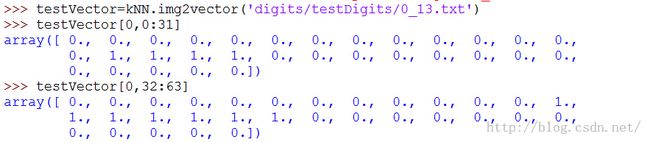
手写数字识别系统的测试代码:
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits') #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
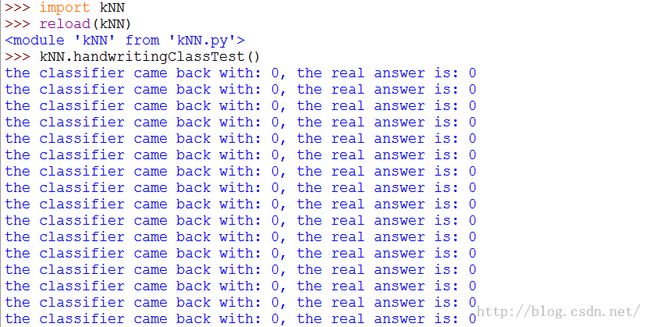
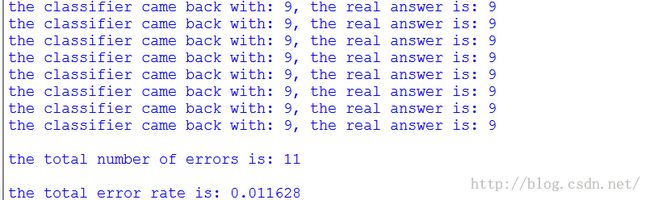
在Python命令提示符中输入kNN.handwritingClassTest(),测试该函数的输出结果:

注:本文的相关代码均来源于Peter Harringtor的《机器学习实战》