Spark下实现LDA+SVM的文本分类处理
最新发布的Spark1.3.1版本中已经实现了LDA的算法,并且以前实现过LDA+SVM进行文本分类的处理程序,借此机会想将程序改为Spark的分布式,Spark已经支持SVM和LDA算法。Spark的环境配置和安装可参考我以前的博客http://blog.csdn.net/cuixianpeng/article/details/20715673,不过Spark版本是以前的。关于SVM和LDA请自行查找资料。
1.环境介绍
系统环境:Ubuntu 12.10
Spark:1.3.1
JDK: 1.7.0_45
Scala:2.10.3
Hadoop:1.2.1
分布式环境
Master:10.0.96.99
Slaves:192.168.40.11, 12, 13
2.Java下运行Spark
Spark的配置和安装在此不做介绍,设置Spark运行信息,获取JavaSparkContext,
SparkConf conf = new SparkConf();
conf.setMaster("spark://10.0.96.99:7077")
// conf.setMaster("local")
.setAppName("Spark Cls")
.setSparkHome(sparkHome)
.setJars(new String[] { "sparkApps_fat.jar" })
.set("spark.executor.memory", "2g");
JavaSparkContext sc = new JavaSparkContext(conf);
3.语料读取
训练语料可以存放于机器的本地环境也可以直接读取HDFS中的语料,若存放于本地环境中则需要确保语料在各个机器上都有并且路径一致。我这里的训练语料相同类别存放于同一个文件夹中,文件夹名词即为类别名。读取语料直接采用Spark的分布式读取。读取代码如下所示。
4.LDA输入预处理
首先介绍一下采用Java api调用运行LDA的输入文件格式,格式如下图所示:
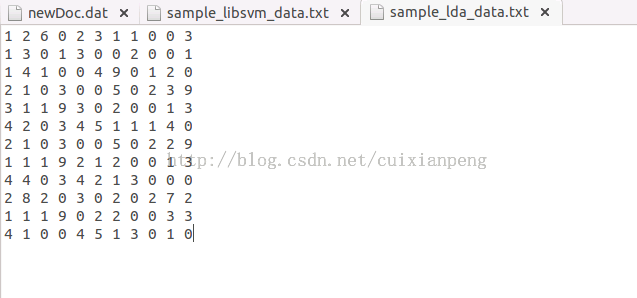
输入格式为二维矩阵数值,每一行表示一个语料文档,每一列表示语料中的词语,对应的数值表示当前词语在当前文档中出现的次数。根据这一格式要求将输入语料文件转化为对应格式的输入文件,并将文件上传至HDFS中。具体过此在此不做介绍了。下面介绍LDA的处理过程。
加载文件,将数值内容存储预Vector中。
// Load and parse the data
JavaRDD<String> data = sc.textFile(srcFile);
JavaRDD<Vector> parsedData = data.map(new Function<String, Vector>() {
public Vector call(String s) {
String[] sarray = s.trim().split(" ");
double[] values = new double[sarray.length];
for (int i = 0; i < sarray.length; i++)
values[i] = Double.parseDouble(sarray[i]);
return Vectors.dense(values);
}
});对文档进行唯一序号标示
// Index documents with unique IDs
JavaPairRDD<Long, Vector> corpus = JavaPairRDD.fromJavaRDD(parsedData.zipWithIndex()
.map(new Function<Tuple2<Vector, Long>, Tuple2<Long, Vector>>() {
public Tuple2<Long, Vector> call(
Tuple2<Vector, Long> doc_id) {
return doc_id.swap();
}
}));设置主题数目并进行训练
// Cluster the documents into three topics using LDA DistributedLDAModel ldaModel = new LDA().setK(topicNum).run(corpus);获取LDA 处理结果中的文档-主题分布矩阵,行表示文档,列表示文档属于每一个主题的概率。
RDD<Tuple2<Object, Vector>> topicDistRDD = ldaModel.topicDistributions();
5.Spark下的SVM处理
首先看一下SVM的输入格式,采用的是libSVM的输入格式,如下所示。
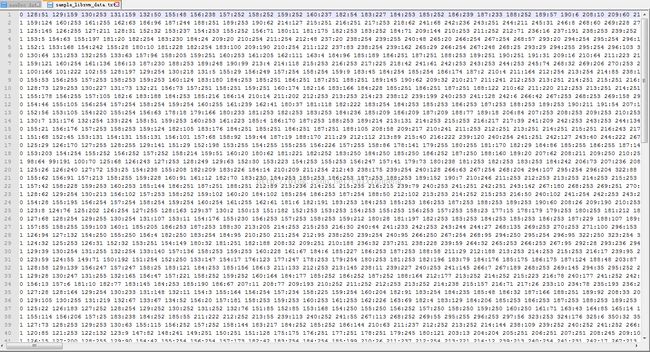
Spark官方网站也提供了示例代码,直接加载文件。
String path = "data/mllib/sample_libsvm_data.txt";
JavaRDD<LabeledPoint> data = MLUtils.loadLibSVMFile(sc, path).toJavaRDD();
我在此处为了减少磁盘的读写操作,没有将LDA的处理结果输出为文件,直接存于内存中并转换为所需格式。需要自己手动生成LabeledPoint类型的List。
SVM训练代码如下所示。
JavaRDD<LabeledPoint> dataPointRDD = sc.parallelize(svmPointsList); dataPointRDD.cache(); SVMWithSGD svmAlg = new SVMWithSGD(); int numIterations = 100; svmAlg.optimizer() .setNumIterations(numIterations) .setRegParam(0.1) .setUpdater(new L1Updater()); final SVMModel modelL1 = svmAlg.run(dataPointRDD.rdd());
最后模型保存
// Save and load model String modelPath = GlobalUtil.LDA_MODEL_DIST_DIR + "/" + "ldaSVMModel"; modelL1.save(sc.sc(), modelPath);
当前版本的LDA还不支持LDA的预测过程,所以多少还有点遗憾。
以上只是我的处理思路,还请大家指正。