世界是数字的重点读书笔记(计算机科普知识)
《世界是数字的》是世界顶尖计算机科学家Brian W.Kernighan写的一本计算机科普类读物,简明扼要但又深入全面地解释了计算机和通信系统背后的秘密,适合计算机初学者和非计算机专业的人读。这真的是一本好书,借Google常务董事长的话:
对计算机、互联网及其背后的奥秘充满好奇的人们,这绝对是一本不容错过的好书。
对于一个计算机已经学了N年的专业人士来说,这本书也许简单了点,不过我还是认真过了一遍,发现也有一定的收货,因为一个人很难掌握本领域里的所有知识,或多或少会有一些欠缺,总会有一些你以前不知道的,或一直没理解清楚的但又很有必要知晓的知识,我在阅读此书过程中就有这种感觉,经常会有一种恍然大悟的感觉,比如理解了互联网上一些不为人知的跟踪原理(具体可以看我下面总结的第12点“Cookie如何暴露你在互联网上的行踪”)。我是个喜欢记笔记和做总结的人,阅读完一本书,我经常会找个闲暇的时间总结下,主要是根据自己已有的知识储备体系总结一些对我有帮助的或有必要知道的知识点。
下面就简单总结下自己的所获和所感。
注意:下面的知识都是科普知识,适合非计算机专业、计算机初学者及和像我一样计算机一开始就没学好的人看,那些牛B的大牛就不用来浪费时间来读你们已称之为“常识”的知识啦。
1. P和NP问题
现在的程序员都很怕遇到NP问题,不仅算法复杂而且还保证不了每次都能找到解。那到底什么是P问题和NP问题呢?作为一个程序员,你如果回答说“P问题就是容易的问题,NP问题就是复杂的难以解决的问题”那就太失败了。P即“Polynomial”(多项式),P问题是指具有“多项式”级复杂性的问题。换句话说,解决这些问题的时间可以用N^2这样的多项式来表示,其中指数可以大于2,但都是可能在多项式时间内被解决的,这些问题相对比较简单。
但是,现实中大量的问题或者说很多实际的问题似乎都需要指数级算法来解决,即我们还不知道对这类问题有没有多项式算法。这类问题被称为“NP(nondeterministic polynomial,非确定性多项式)”问题。NP 问题的特点是,它可以快速验证某个解决方案是否正确,但要想迅速找到一个解方案却很难。可以这么认为,这些问题可以用一个算法在多项式时间内靠猜测来解决,而且该算法必须每次都能猜中。在现实生活中,没有什么能幸运到始终都做出正确的选择,所以这只是理论上的一种设想而已。
可以举个简单的例子来说明NP问题,那就是著名的“旅行推销员问题”(Traveling Salesman Problem)。一个推销员必须从他居住的城市出发,到其他几个城市去推销,然后再回家。目标是每个城市只到一次(不能重复),而且走过的总距离最短。这个问题实际应用价值很大,其原理经常被应用于设计电路板上孔洞的位置,或者部署船只到墨西哥湾的特定地点采集水样。旅行推销员问题已经被仔细推敲了50 多年,但还是解决不了NP难问题。
现在业界内也经常讨论一个问题:P 是否等于NP?即这些难题到底跟那些简单的问题是不是一类?
尽管很多人都相信未来的某一天可以达到P=NP,但我还是希望这一天不要太早到来,因为现在一些重要的应用,如加密软件,都是完全建立在某个特定的问题确实极难解决的基础之上的。设想一下,如果某天这些难问题都被攻破了,那我们的各个账号密码、网银岂不是要……当然,如果真有那么一天,也表明计算机领域又有了一个重大的突破,这是值得可贺的。
2. 没有删除只有覆盖
我们知道,磁盘没有真正的删除,我们所谓的“delete”操作只是把文件占用的块回写到空闲块列表。但是,这些文件的内容并没有被删除。换句话说,原始文件占用的每个块中的所有字节都会原封不动地呆在原地。除非相应的块从空闲块列表中被“除名”并奉送给某个应用程序,否则这些字节不会被新内容覆盖。这意味着什么呢?意味着你认为已经删除的信息实际上还保存在硬盘上。如果有人知道怎么读取它们,仍然可以把它们读出来。任何可以不通过文件系统而能够逐块读取硬盘的程序,都可以看到那些被“删除”的内容。
那么如何真正的彻底删除呢?Mac中的“安全擦除”选项在释放磁盘块之前,会先用随机生成的比特重写其中的内容。但是即使用新信息重写了原有内容,一名训练有素的敌人仍旧可以凭借他掌握的大量资源发现蛛丝马迹。军事级的文件擦除会用随机的1 和0 对要释放的块进行多遍重写。更为保险的做法是把整块硬盘放到强磁场里进行消磁。而最保险的做法则是物理上销毁硬盘,这也是保证其中内容彻底销声 匿迹的唯一可靠方法。
也有一些彻底删除文件的软件,比如我用过的BCWipe(是看韩国黑客犯罪片“幽灵”时知道的,剧里经常用这个软件删除机密文件),它提供 Delete with wiping、Wipe free disk space 两种方式来清除你的磁盘文件,还有其它选项,不过这款软件是收费软件,我只试用过一段时间,我本人没啥见不得人的文件,也不需要此类软件,只是当时看完电视好奇试玩了一把。
3. 无线网络上网原理
从技术角度讲,无线网络利用电磁波传送信号。电磁波是特定频率的电波,其振动频率以Hz 来衡量(读者可能更熟悉广播电台常用的MHz 或GHz,比如北京交通广播电台的频率是103.9 MHz)。在发送信号之前,首先要通过调制把数据信号附加到载波上。比如,调幅(AM)就是通过改变载波的振幅或强度来传达信息,而调频(FM)的原理则是围绕一个中心值来改变载波的频率。接收器接收到信号的强度与发射器的功率成正比,与到发射器距离的平方成反比。由于存在这种二次方递减的关系,距离发射器的距离增加一倍,接收器接收到的信号强度就只有原来的四分之一。无线电波穿越各种物质时强度都会衰减,物质不同衰减程度也不同,比如说金属就会屏蔽任何电波(突然想起《超验骇客》电影里卡斯特家花园里建的用来屏蔽信号的金属网)。高频比低频更容易被吸收,二者在其他方面都一样。
无线联网对可以使用的频率范围—频段,以及使用多大的功率发送电波都有严格规定。频段分配始终都是一个有争议的话题,因为各种需求总会发生冲突。
无线以太网设备发射的电波频率为2.4~2.5 GHz,某些802.11 设备的频率会达到5 GHz。所有无线设备的频率都局限于这一较窄的范围内,冲突的可能性大大增加。更糟的是,有些无线电话、医疗设备,甚至微波炉也跟着凑热闹,同样使用这一频段。有一次作者在使用厨房里那台旧笔记本时无线连接突然断了,后来才发现是用微波炉加热咖啡的缘故。30 秒钟的加热就足以让笔记本断开无线连接。
下面介绍三种使用最广泛的无线联网技术。
(1)首先就是蓝牙,蓝牙技术是为近距离临时性连接而发明的,使用与802.11 相同的2.4 GHz 频段。蓝牙连接的距离是1 到100 米,具体取决于功率大小,数据传输速度为1~3 Mbit/s。使用蓝牙技术的设备主要包括无线麦克风、耳机、键盘、鼠标、游戏手柄,功率相对较低。
(2)第二种技术是RFID(radio-frequency identification),即无线射频识别,主要用于电子门禁、各种商品的电子标签、自动收费系统、宠物植入芯片,以及护照等身份证明。 RFID 标签其实就是一个小型无线信号收发装置,对外广播身份信息。被动式标签不带电源,通过天线接收到的RFID 读取器广播的信号来驱动。RFID 系统使用多种不同的频率,比较常见的是13.56 MHz。RFID 芯片让秘密监视物体和人的行踪成为可能。 植入宠物体内的芯片就是一种常见的应用,已经有人建议也给人植入这种芯片了。至于动机嘛,就不好说了。
(3)最后一种是GPS(Global Positioning System,全球定位系统),它是一种重要的单向无线系统,常见于汽车和手机导航系统中。GPS卫星会广播精确的时间信息,而GPS接收器会根据它从三四颗卫星接收到信号的时间来计算自己在地面的位置。然而,GPS只接收信号不发送信号。以前曾有一个关于GPS 的误解,认为它能悄悄地跟踪用户。给大家摘录一段《纽约时报》几年前闹的一个笑话吧:“有些(手机)依靠全球定位系统,也就是GPS,通过向卫星发送信号来精确地定位用户。”这完全是误解。要 想利用GPS跟踪用户,必须得有地面系统(比如手机)转发位置信息。手机与基站之间保持密切通信,因而可以(而且确实会)不断地报告你的位置。只不过有了GPS 接收器之后,它所报告的信息可以更加精确。
4. 手机为何又称作“蜂窝电话”?
何谓“蜂窝”?因为频段和无线电的覆盖范围都是有限的,因此就要把整个地区划分为蜂窝状的许多小区。可以将每个这样的小区想象为六边形,然后中央有一个基站,相邻的小区之间通过基站相连。打电话的时候,手机会与最近的基站通信。当用户移动到另一个小区时,进行中的通话就由原来的小区移交给新小区,但这个切换用户一般觉察不到。
由于接收功率会随着距离的二次方衰减,所以位于既定频段中的频带在不相邻的小区内可以重用,而不会相互干扰。这就是可以高效利用有限频段的秘密所在。
大家看下面这幅示意图:
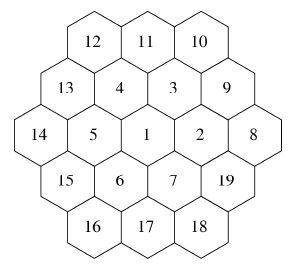
1 号小区中的基站与2 到7 号小区中的基站不会使用相同的频率,但可以跟8到19号小区中的基站使用相同的频率,因为与它们之间的距离足以避免干扰了。“蜂窝”中小区的实际形状要取决很多因素,比如天线的辐射图形。这张图只是一种理想化的结果。
蜂窝手机是常规的电话网络的一部分,只不过连接这个网络不是靠电话线,而是靠基站发射无线电波。
手机使用的频段很窄,传输信息的能力有限。因为要使用电池,所以打电话时发射的都是低功率无线电波。而且根据法律规定,为了避免与其他无线设备发生干扰,它们的传输功率也受到限制。
手机在世界的不同地区会使用不同的频带,但一般都在900 MHz 左右。每个频带被分成多个信道,每次通话时,收发信号各占用一个信道。发送呼叫信号的信道由小区中所有手机共享,在某些系统中这个信道也可以同时用于发送短信和数据。
拨打电话的原理:每个手机都有唯一的识别码(可不是说手机号啊),相当于以太网的地址。启动手机后,它就会广播自己的识别码。距离最近的基站接收到手机信号后,会通过后台系统验证该识别码。随着手机移动,基站实时更新其位置信息,并不断向后台系统报告。如果有人呼叫该手机,后台系统就能通过一直与它保持联系的基站找到它。
手机与基站通信时的信号强度很高。但手机会动态调整功率,在距离基站较近时降低功率。这样不仅可以省电,也可以减少干扰。待机时的耗电量远远比不上一次通话,而这也是为什么待机时间以天为单位,而通话时间以小时为单位的原因。如果手机所在小区信号较弱或根本没有信号,那么它就会因为拼命查找基站而大量耗电。
美国使用了两种完全不同的手机通信技术:
(1)AT&T和T-Mobile使用GSM(Global System for Mobile Communications,全球移动通信系统),这是一种在欧洲使用非常普遍的系统,它把频带分成很窄的信道,在每个信道内依次附加多路通话。GSM 是世界上应用范围最广的系统。
(2)Verizon 和Sprint 使用CDMA (Code Division Multiple Access,码分多址),这是一种“扩展频段”技术,它把信号扩展到频带之外,但对不同的通话采用不同的编码模式进行调制。这就意味着,虽然所有手机都使用相同的频带,但大多数情况下通话之间不会发生干扰。
GSM 和CDMA 都会利用数据压缩来尽可能减少封装信号的比特量。对于通过嘈杂的无线电信道发送数据时无法避免的错误,再添加错误校验来解决问题。
手机带来了一系列难解的非技术问题:
(1)频段的分配。在美国,政府限 制每个频带最多只能有两家公司使用指定频率。因此频段是非常稀缺的资源,也是无线联网系统的关键资源。
(2)手机信号发射塔的位置。信号发射塔作为户外建筑算不上漂亮,很多地区为 此拒绝在自己的地界上搭设这种东西。
5. TCP/IP协议作用
互联网有很多协议,其中最基础的有两个,一是互联网协议(Internet Procotol,IP),定义了单个包的格式和传输方式,二是传输控制协议(Transmission Control Protocol,TCP),定义了IP包如何组合成数据流以及如何连接到服务。两者合起来起就叫TCP/IP。当然TCP/IP协议族不只是包含这两个协议,还包含其它许多的协议。
6. 数据压缩技术
数据压缩技术分为无损压缩和有损压缩。
- 无损压缩,即压缩过程中不丢失信息,解压后得到的数据和原始数据一模一样,比如霍夫曼编码(Huffman coding),和广泛使用的zip程序或bzip2程序,都属于无损压缩。只不过前者按单个字母来压缩,而后者按大块文字,比如zip就是根据原始文档的属性选择按单词或词组压缩。
- 有损压缩最常用于处理要给人看或听的内容。比如压缩数码相机拍出来 的照片。人眼分辨不出来非常相近的颜色,所以不必保留实际输入的那么多种颜色,颜色少一点没有任何问题,这样就可以减少编码所用的位数。与此类似,某些难以觉察的细节也可以丢弃,这样处理后的图像尽管没有原始画面那么精密,但眼睛看不出来。细微的亮度变化也是如此。比如JPEG算法和用于压缩电影和电视节目的MPEG 系列算法都是有损压缩。
所有压缩算法的思路都是减少或去掉那些不能物尽其用的位串,采用的主要方法包括把出现频率较高的元素编码成短位串、构造频率字典、用数字代替重复内容等。无损压缩能够完美重现原始数据,有损压缩通过丢弃接收者不需要的信息,来达成数据质量和压缩率的折中。
7. 如何根据银行卡号判断卡的真伪?
在“错误检测和校正”小节看到了一个有意思的算法,是IBM公司的彼得·卢恩(Peter Luhn)于1954年设计的一个校验和(checksum)算法,来检测在实际操作中最常见的两种错误:单个数字错误、由于两个数字写错位置而引起的大多数换位错误。后来这个算法有了很多应用场景,比如可以检测16位长的信用卡和储蓄卡的卡号是否是有效的卡号(这是美国的情况,中国的储蓄卡一般是19位,不过算法同样适用);10 位或13 位的ISBN 书号也采用了类似算法的校验和,用来对付同类错误。
这个算法很简单:从最右一位数开始向左,把每个数字交替乘1或2,如果结果大于 9就减9。如果把各位数的计算结果加起来,最后得到的总和能被10 整除,那这个卡号就是有效卡号。
你可以用这个方法测试一下信用卡,以“4417 1234 5678 9112”为例(此卡号取自某银行广告),这个卡号计算的结果是69,所以不是真卡号;如果把它的最后一个数字换成3,那就是有效卡号了。我用该算法测试了自己的银行卡和信用卡,的确可以用来检测卡的真伪,这也算是个小知识吧。
8. 你能用一句话解释CGI是干嘛的吗?
通用网关接口(Common Gateway Interface,CGI),是HTTP 协议里一个从客户端(你的浏览器)向服务器传递信息的机制,它能用来传递用户名和密码、查询条件、单选按钮和下拉菜单选项。
CGI机制在HTML里用<form> ... </form>标签来控制。你可以在<form>标签里放入文本输入区、按钮等常见界面元素。如果再加上一个“提交”按钮,按下去就会把表单里的数据发送到服务器,服务器用这些数据作为输入,来运行指定的程序。
9. 伟大的Netscape公司
Cookie技术和Javascript脚本语言都是Netscape公司发明的,网景公司对互联网的贡献真是太大了(还记得网景浏览器吗?),不得不佩服。
10. 病毒和蠕虫的差别
病毒和蠕虫在技术上有个细微差别是:病毒的传播需要人工介入,也就是只有你的操作才能催生它的传播;而蠕虫的传播却不需要你的援手,完全自发进行。
11. 搜索引擎核心竞争力及主要收入来源
搜索引擎的核心竞争力在于怎么才能迅速从抓取的页面中筛选出匹配度最高的URL,比如最为匹配的十个页面。谁能把最佳匹配结果排在前头,谁的响应速度快,谁就能赢得用户。
第一批搜索引擎只会显示一组包含搜索关键词的页面,而随着网页数量激增,搜索结果中就会混入大量无关页面。谷歌的PageRank算法会给每个页面赋予一个权重,权重大小取决于是否有其他页面引用该页面,以及引用该页面的其他页面自身的权重。从理论上讲,权重越大的页面与查询的相关度就越高。正如布林和佩奇所说:“凭直觉,那些经常被其他网页提及和引用的页面的价值一定更高一些。”当然,要产生高质量的搜索结果绝对不会只靠这一点。搜索引擎公司会不断采取措施来改进自己的结果质量,以期超越对手。
搜索引擎的收入通常来自广告。简单来说,搜索引擎的广告模式有两种:
(1)广告客户付钱在网页上显示广告,价格由多少人看过以及什么样的人看到该网页来决定。这种定价模式叫按页面浏览量收费,即按“展示”, 也就是按广告在页面上被展示的次数收费。
(2)另一种模式是按点击收费,即按浏览者点击 广告的次数收费。因此搜索引擎的广告模式。
说到底就是拍卖搜索关键词,且搜索引擎公司都有完备的手段避免虚假点击。
12. Cookie如何暴露你在互联网上的行踪?— Cookie跟踪的原理
只要上网,我们的信息就会被收集,而如果没有我们留下的蛛丝马迹,几乎什么事儿也干不了。使用其他系统时的情况也一样,特别是使用手机的时候,手机网络随时都知道我们在哪里。如果是在户外,支持GPS的手机(现在的智能手机几乎都支持)定位用户的误差不超过10米,而且随时都会报告你的位置。有些数码相机也带GPS,可以在照片中编入地理位置信息,这种做法被称为打地理标签。
把多个来源的跟踪信息汇总起来,就可以绘制一幅关于个人的活动、喜好、财务状况,以及其他很多方面的信息图。这些信息最起码可以让广告客户更精准地定位我们,让我们看到乐意点击的广告。不过,跟踪数据的应用可远不止于此。这些数据还可能被用在很多我们意想不到的地方。比如根据收入把人分成三六九等,在贷款时区别对待,或者更糟糕地,被人冒名顶替,被政府监控,被人图财,甚至害命。
怎么收集我们的浏览信息呢?有些信息会随着浏览器的每一次请求发送,包括你的IP地址、正在浏览的页面、浏览器的类型和版本、操作系统,还有语言偏好。
此外,如果服务器的域中有cookie,那么这些“小甜饼”也会随浏览器请求一块发送。根据cookie的规范,只能把这些保存用户信息的小文件发给最初生成它们的域。那还怎么利用cookie跟踪我对其他网站的访问呢?
要知道答案,就得明白链接的工作原理:
每个网页都包含指向其他页面的链接(这正是“超链接”的本义)。我们都知道链接必须由我们主动点击,然后浏览器才会打开或转向新页面。但图片不需要任何人点击,它会随着页面加载而自动下载。网页中引用的图片可以来自任何域。于是,在浏览器取得图片时,提供该图片的域就知道我访问过哪个页面了。而且这个域也可以在我的计算机上存放cookie,并且收到之前访问过的域所产生的cookie。
以上就是实现跟踪的秘密所在,下面我们再通过例子来解释一下。假设我想买一辆新车,因此访问了toyota.com。我的浏览器因此会下载60 KB的HTML文件,还有一些JavaScript,以及40张图片。其中一张图片的源代码如下:
<img src="http://ad.doubleclick.net/ad/
N2724.deduped_spotlight/B1009212;
sz=1x1;tag=total_traffic;ord=1?"
width=1 height=1 border=0>这个<img>标签会让浏览器从ad.doubleclick.net下载一张图片。这张图片只有1像素宽、1像素高,没有边框,而且很可能是透明的,总之页面上看不见它(称之为网页信标)。当然,这张图片根本就没想让人看到。当我的浏览器请求它时,DoubleClick会知道我正在浏览丰田汽车公司网站的某个页面,而且(如果我允许)还会在我的计算机中保存一个cookie文件。要是我随后又访问了一个内置DoubleClick图片的网站,DoubleClick就可以绘制一张我的“足迹图”。如果我的“足迹”大都留在汽车网站上,DoubleClick会把这个信息透露给自己的广告客户。于是乎,我就能看到汽车经销商、购车贷款、修车服务、汽车配件等等各种广告。如果我的“足迹”更多与交通事故或止疼有关,那么就会看到律师和医生投放的广告。
DoubleClick(现为谷歌所有)在拿到用户访问过的站点信息后,会根据这些信息向丰田等广告客户推销广告位。丰田公司继而利用这些信息定向投放广告,而且(可能)会参考包括我的IP地址在内的其他信息。(DoubleClick不会把这些信息卖给任何人。)随着我访问的页面越来越多,DoubleClick就可以绘制一幅关于我的更详细的图画,借以推断我的个性、爱好,甚至知道我已经60多岁了,是个男的,收入中上,住在新泽西中部,在普林斯顿大学上班。知道我的信息越多,DoubleClick的广告客户投放的广告就越精准。到了某个时刻,DoubleClick甚至可以确定那个人就是我,尽管大多数公司都声称不会针对具体的某个人。可是假如我的确在某些网页中填过自己的名字和电子邮件地址,那谁也不敢保证这些信息不会被传播。
这套互联网广告系统设计得极其精密。打开一个网页,这个网页的发布者会立即通知雅虎的Right Media或谷歌的
Ad Exchange,说这个网页上有一个空地儿正虚位以待,可以显示广告。同时发过去的还有浏览者的信息(例如,25到40岁之间、单身、住在旧金山,是个技术宅,喜欢泡馆子)。于是,广告客户会为这个广告位而竞价,胜出者的广告将被插入到这个网页中。整个过程不过零点几秒而已。
如何防范?
只要上网,防范基本上是不可能的,不过可以选择性的关闭一些cookie跟踪。比如作者使用过Firefox的一个扩展TACO(Target Advertising Cookie Opt-out,定向广告Cookie 自愿回避),这个扩展维护着一个cookie 跟踪站点的列表(目前有大约150个名字),在浏览器中保存着它们的自愿回避cookie。而我呢,同时对大多数网站都选择关闭cookie。
许多网站都含有多家公司的跟踪程序。给大家推荐一个浏览器扩展Ghostery,通过它可以禁用JavaScript 跟踪代码,还能查看被阻止的跟踪器。装上它,你会惊讶于互联网上潜伏着多少“间谍”。仅适用于Firefox的Noscript插件也有类似的功能。
总结:
一个像素大的图片或者叫网页信标(web beacon,一个很小而且通常是看不到的图片,用于记录某个网页是否已经被下载过了。)都可以用来跟踪你。 用于取得像素图片的URL 可以包含一个标识码,表示你正在浏览什么网页,还可以包含一个标识符,表示特定的用户。这两个标志就足以跟踪你的浏览活动了。
13. 隐私失控问题
随着社交网站的流行,为了娱乐和与其他人联系,我们自愿放弃了很多个人隐私。社交网站存在隐私问题是毫无疑义的,因为它们会收集注册用户的大量信息,而且是通过把这些信息卖给广告客户来赚钱。
作为最大也最成功的社交网站,Facebook 的问题也最明显。Facebook 给第三方提供了 API,以方便编写Facebook 用户可以使用的应用。但这些API 有时候会违背公司隐私政策透露一些隐私信息。当然,并非只有Facebook 一家如此。做地理定位服务的Foursquare 会在手机上显示用户的位置,能够为找朋友和基于位置的游戏提供方便。在知道潜在用户位置的情况下,定向广告的效果特别好。如果你走到一家餐馆的门口,而手机上恰好是关于这家餐馆的报道,那你很可能就会推门进去体验一下。虽然让朋 友知道你在哪儿没什么问题,但把自己的位置昭告天下则非明智之举。比如,有人做了一个示范性的网站叫“来抢劫我吧”(Please Rob Me),该网站根据Foursquare 用户在Twitter 上发表的微博可以推断出他们什么时候不在家,这就为入室行窃提供了机会。
社交网站很容易根据自己的用户构建一个交往群体的“社交图谱”,其中包括被这些用户牵连进来但并未同意甚至毫不知情的人。