Ubuntu12.10部署Spark0.9.0
Spark是由加州大学伯克利分校的AMP实验室开发的类似于Hadoop的开源集群计算环境,Spark将中间数据存放于内存中,比较适合于迭代式计算,应用于机器学习以及数据挖掘中,下面介绍一下我的部署过程,不保证适合于所有人的情况。
1 环境介绍
Ubuntu 12.10
JDK1.7.0_45
Spark 0.9.0
Scala 2.10.3
首先确保电脑已经安装JDK,Spark的运行依赖于Scala,因此首先安装Scala。
2 Scala安装
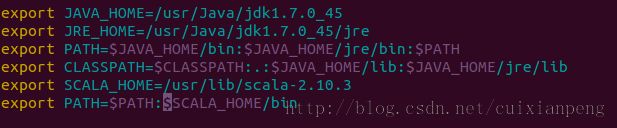
Scala的下载地址是http://www.scala-lang.org/。下载之后解压,然后置于自己的目录中,我这里是/usr/lib里面,然后配置环境变量。
vim /etc/profile具体形式如下图所示。
执行命令,使环境变量生效。
source /etc/profile执行命令,查看Scala配置是否成功。
scala -version

3 安装Spark
在这里介绍Spark的本地模式和集群模式。
3.1本地模式
Spark的下载地址是http://spark.incubator.apache.org/,我采用的是spark-0.9.0-incubating-bin-hadoop2.tgz。下载解压然后置于自己的目录,我在这里是/usr/Java下面,并将文件夹重命名为spark-0.9.0。配置环境变量以及增加SPARK_EXAMPLES_JAR的环境变量,具体如下图所示。

这样本地模式就配置完成,下面进行测试,在Spark的目录中输入命令。
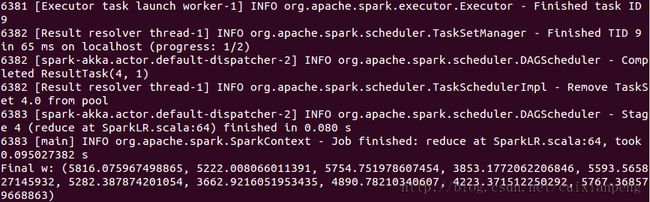
./bin/run-example org.apache.spark.examples.SparkPi local或者在命令的最后指定线程数目如local[2]。运行结果如下所示:
3.2 集群模式
共有四台机器,系统均为Ubuntu12.10,其中
Master :192.168.23.123 ubuntu
Slaves: 192.168.40.11 ubuntu11
192.168.40.12 ubuntu12
192.168.40.13 ubuntu13
四台机器Spark的安装目录均需要相同,安装配置环境变量。
3.2.1 在Master机器上
进入Spark目录下面的conf目录,将spark-env.sh.template复制一份并且重命名为spark-env.sh,并对其进行配置,配置Spark的目录、Java目录、Master的IP以及运行内存,可根据自己的情况进行扩充,具体如下图所示。

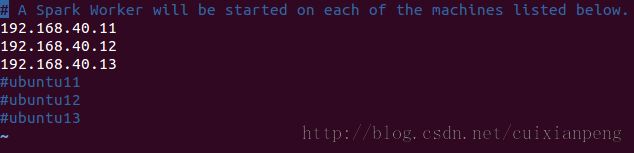
然后配置slaves文件,将每一个Slave的IP或者hostname输入,每个机器一行,具体如下图所示。
3.2.2 Slave机器上
上述两个文件配置完成后,将其拷贝到所有Slave机器上即可。
机器之间最好配置为SSH无密码登录,否则启动Spark后,MasterSSH登录Slave时需要手动输入密码太繁琐,具体设置方法可参见《Ubuntu 12.10配置SSH无密码登录》
4.启动Spark
在Spark目录中的sbin目录下有多种启动或者停止方式,在此选择./sbin/start-all.sh启动集群中的所有机器。
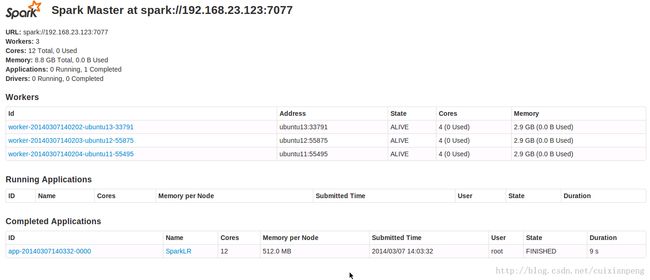
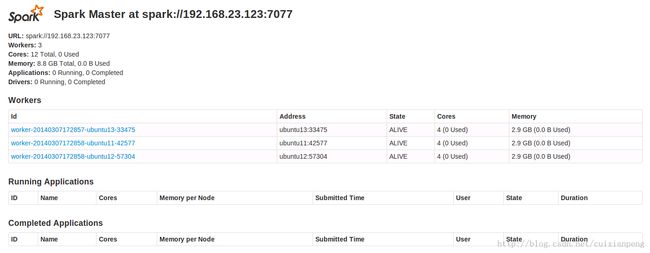
启动之后在Master浏览器中输入hostname:8080或者IP:8080可以看到所有的机器情况。
在Slave上输入IP或者hostname:8081可以查看本Slave的情况。
下面分布式运行测试示例。
./bin/run-example org.apache.spark.examples.SparkLR spark://192.168.23.123:7077命令中spark之后所跟的是Master的IP地址。运行成功的显示界面如下图所示。