机器学习(十一)机器学习系统设计的细节问题
本文由 @lonelyrains 出品,转载请注明出处。
文章链接: http://blog.csdn.net/lonelyrains/article/details/49365349
2、前期:
1)首先实现一种简单算法,能快速使用交叉检验测试,然后画学习曲线,再决定是否要更多数据、特征变量等,避免前期过度优化。
2)将交叉检验分错的部分人工分析一下,是否有什么系统性的规律,启发新的特征变量。
3)基于交叉检验数据集检验的定量误差分析。通过增减新特征变量,判断误差是降低还是升高。
3、正样本或者负样本所占比例非常少时,比如得癌症的人数和没有得癌症的人,则是否得癌症的这个特征称为偏斜类(skewed class)。处理这类数据的方法:
查准率(precision)、召回率(recall)[指的都是交叉检验的数据]。
查准率=真真/(真的真+假的真),召回率=真真/(真的真+假的假)。
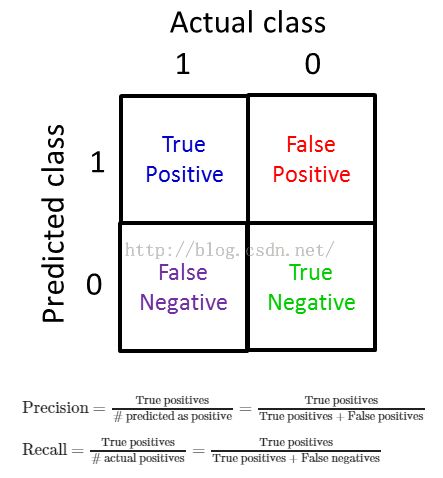
如果一个算法有高查准率和召回率,则可以认为这个算法模型效果比较好。
事实上,经常P、R的关系曲线是这样:
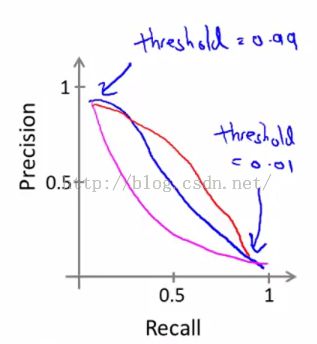
当查准率和召回率不能同时满足高位时,有一个经验公式:

4、增加样本数据,以提高模型准确率。现在的共识是:取得成功的不是拥有最好算法的,而是拥有最多数据的。
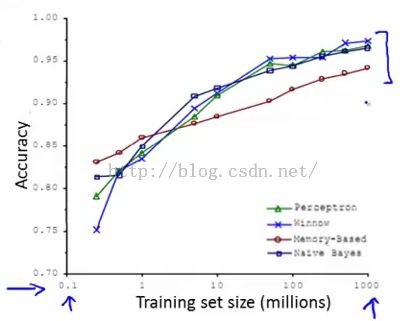
【专门有学科介绍怎么获取数据并清洗的,有机会再单独写博客介绍一下】。
当遇到提取特征变量的问题,一个有用的测试方法就是,如果一个经验丰富的专家在拥有这些特征变量的具体值的情况下,能否较准确或自信地预测结果。例如如果只告诉房子的大小,专家也无法准确预测房子的价格,还跟地理位置、房龄等因素有关。
大样本不容易过拟合,低方差,即使高偏差(欠拟合),大样本也意味着Jtrain很可能与Jtest相差不大,所以如果Jtrain比较小,Jtest可能也比较小。