走进cassandra之五: 存储机制
有图有真相。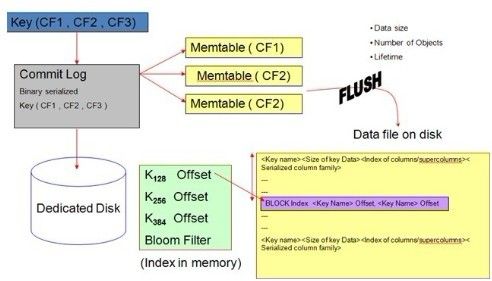
先上个图。
这个图总的意思就是说,
数据先写入内存中的Memtable,Memtable达到条件后刷新到磁盘,保存为SSTable,同一个CF的多个SSTable可以合并(Compaction)以优化读操作
commit log -> memtable -> sstable -> compaction.
看起来似乎有些麻烦,存个数据要这么多弯弯绕,但是记得,兄弟们,现在是应付海量数据,同时有很多节点,所以必须要走这么多弯路。
memtable是啥呢,所谓mem, mem,就是memory,内存,放在内存的table。
数据放内存有啥好处呢?
一个字: 快。
因为离CPU最近的,就是内存.
找数据的时候,先去内存里找,找不到再去硬盘找。
从硬盘上找东西的时候,要注意一点,因为硬盘比较矫情。
很容易发生i/o block。
为了应付这个矫情,cassandra找了Bloom兄弟来帮忙。
有个算法叫 Bloom Filter,
可以通过布隆过滤算法(Bloom Filter)减少对不可能包含查询key的SSTable的读取。
说了半天,啥是SSTable呢?
大家伙可以去自己硬盘上看一看:
SSTable包含对应的三种文件
Datafile
按照Key排序顺序保存的数据文件
文件名称格式如下:ColumnFamilyName-序号-Data.db
Indexfile
保存每个Key在Datafile中的位置偏移
文件名称格式如下: ColumnFamilyName-序号-Filter.db
Filterfile
保存BloomFilter的Key查找树
文件名称格式如下: ColumnFamilyName-序号-index.db
大家伙实际看下,估计能有个感观印象了。
sstable多了也占空间,麻烦,可以使劲压一压,压扁了,就不占那么大地儿了。
压扁的过程,在cassandra里面,叫compaction.
一个CF可能有很多SSTable,系统会将多个SSTable合并排序后保存为一个新的SSTable,称之为Compaction。
一次compaction最多请求合并32个SSTable,最少4个。超过32个则按时间排序分批进行(这两个阈值可以设置)。
如果空间不足,则尝试去掉最大的SSTable再合并,如果连合并两个最小的SSTable的空间都不足,则告警。
Major Comaction:合并CF的所有SSTable为一个新的SSTable,同时执行垃圾数据(已标记删除的数据tombstone)清理。
Minor Compaction:只合并大小差不多的SSTable,超过4个需要合并的SSTable就会自动触发。
可通过nodetool compact命令手动触发。
数据目录最好保持50%以上的可用空间。
就好像雷锋做了好事,要写在日记本上一样,咱凡事都有个log文件。
cassandra也有一个,叫 commitlog.
Commitlog是server级别的,不是Column Family级别的,每一个节点上的Commitlog都是统一管理。
每个Commitlog文件的大小是固定的,称之为一个CommitlogSegment,目前版本(0.7.0)中,这个大小是128MB,硬编码在代码中。
当一个Commitlog文件写满以后,会新建一个的文件。
SSTable持久后不可变更,故Commitlog只用于Memtable的恢复,相当于Oracle的Instance Recovery。Cassandra不需要做Media Recover
当节点异常重启后,将根据SSTable和Commitlog进行实例恢复,在内存中重新恢复出宕机前的Memtable。
当一个Commitlog文件对应的所有CF的Memtable都刷新到磁盘后,该Commitlog就不再需要,系统会自动清除